

Ubuntu 20.04 Hadoop

- 2355
- 192
- Mrs. Willie Beahan
O Apache Hadoop é composto por vários pacotes de software de código aberto que funcionam juntos para armazenamento distribuído e processamento distribuído de big data. Existem quatro componentes principais no Hadoop:
- Hadoop comum - As várias bibliotecas de software que o Hadoop depende de correr
- Sistema de arquivos distribuído Hadoop (HDFS) - Um sistema de arquivos que permite distribuição e armazenamento eficientes de big data em um conjunto de computadores
- Hadoop MapReduce - usado para processar os dados
- Fio Hadoop - Uma API que gerencia a alocação de recursos de computação para todo o cluster
Neste tutorial, examinaremos as etapas para instalar o Hadoop versão 3 no Ubuntu 20.04. Isso envolverá a instalação de HDFs (Namenode e Datanode), Yarn e MapReduce em um único cluster de nós configurados no modo pseudo -distribuído, que é distribuído simulação em uma única máquina. Cada componente do Hadoop (HDFS, YARN, MapReduce) será executado em nosso nó como um processo Java separado.
Neste tutorial, você aprenderá:
- Como adicionar usuários para o ambiente Hadoop
- Como instalar o pré -requisito Java
- Como configurar ssh sem senha
- Como instalar o Hadoop e configurar os arquivos XML relacionados necessários
- Como começar o cluster Hadoop
- Como acessar o Namenode e o ResourceManager Web UI
Apache Hadoop no Ubuntu 20.04 Fossa focal | Categoria | Requisitos, convenções ou versão de software usada |
|---|---|
| Sistema | Ubuntu instalado 20.04 ou Ubuntu atualizado 20.04 Fossa focal |
| Programas | Apache Hadoop, Java |
| Outro | Acesso privilegiado ao seu sistema Linux como raiz ou através do sudo comando. |
| Convenções | # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de sudo comando$ - Requer que os comandos do Linux sejam executados como um usuário não privilegiado regular |
Crie usuário para o ambiente Hadoop
Hadoop deve ter sua própria conta de usuário dedicada em seu sistema. Para criar um, abra um terminal e digite o seguinte comando. Você também será solicitado a criar uma senha para a conta.
$ sudo adduser hadoop
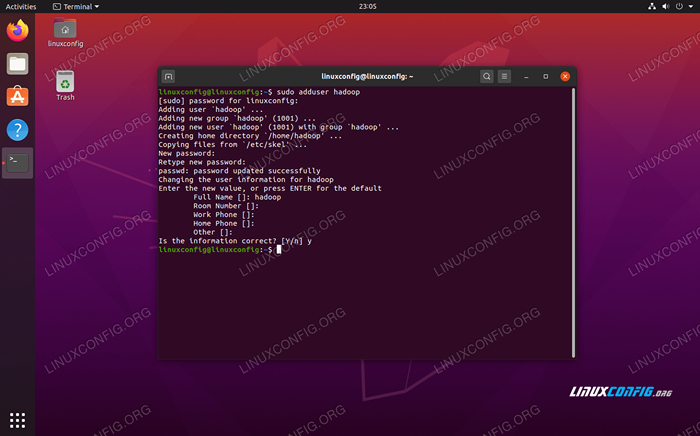 Crie um novo usuário do Hadoop
Crie um novo usuário do Hadoop Instale o pré -requisito Java
O Hadoop é baseado em Java, então você precisará instalá -lo no seu sistema antes de poder usar o Hadoop. No momento da redação deste artigo, a atual versão 3 do Hadoop.1.3 requer Java 8, então é isso que estaremos instalando em nosso sistema.
Use os dois comandos a seguir para buscar as listas de pacotes mais recentes em apt e instalar Java 8:
$ sudo apt update $ sudo apt install openjdk-8-jdk openjdk-8-jre
Configure ssh sem senha
Hadoop depende do SSH para acessar seus nós. Ele se conectará a máquinas remotas através do SSH e da máquina local se você tiver Hadoop funcionando nela. Portanto, mesmo que estejamos montando apenas o Hadoop em nossa máquina local neste tutorial, ainda precisamos ter o SSH instalado. Também temos que configurar ssh sem senha
para que o Hadoop possa estabelecer silenciosamente conexões em segundo plano.
- Precisamos do Pacote OpenSsh Server e OpenSsh Client. Instale -os com este comando:
$ sudo apt install OpenSsh-Server OpenSsh-Client
- Antes de continuar mais longe, é melhor ser registrado no
Hadoopconta de usuário que criamos anteriormente. Para alterar os usuários em seu terminal atual, use o seguinte comando:$ su Hadoop
- Com esses pacotes instalados, é hora de gerar pares de chave pública e privada com o seguinte comando. Observe que o terminal solicitará várias vezes, mas tudo o que você precisa fazer é continuar batendo
DIGITARpara prosseguir.$ ssh -keygen -t rsa
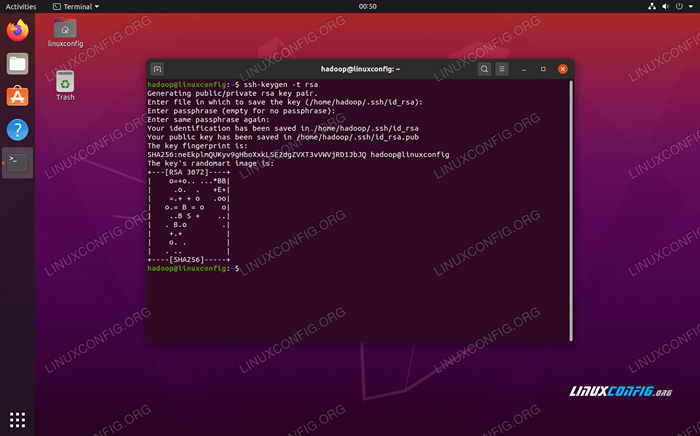 Gerando chaves RSA para ssh sem senha
Gerando chaves RSA para ssh sem senha - Em seguida, copie a chave RSA recém -gerada em
id_rsa.barparaAutorizado_keys:$ cat ~//.ssh/id_rsa.pub >> ~///.ssh/autorizado_keys
- Você pode garantir que a configuração tenha sido bem -sucedida ao sshing no host. Se você é capaz de fazer isso sem ser solicitado por uma senha, está pronto para ir.
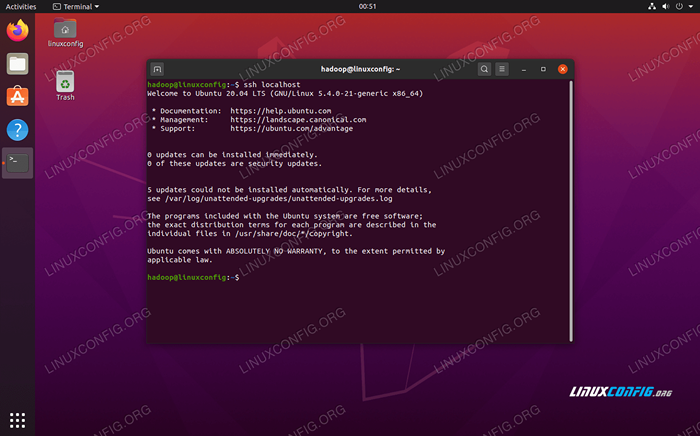 Sshing no sistema sem ser solicitado por senha significa que funcionou
Sshing no sistema sem ser solicitado por senha significa que funcionou
Instale o Hadoop e configure arquivos XML relacionados
Vá para o site da Apache para baixar o Hadoop. Você também pode usar este comando se quiser baixar o Hadoop versão 3.1.3 Binário diretamente:
$ wget https: // downloads.apache.org/hadoop/comum/hadoop-3.1.3/Hadoop-3.1.3.alcatrão.gz
Extrair o download para o Hadoop Diretório doméstico do usuário com este comando:
$ tar -xzvf Hadoop -3.1.3.alcatrão.gz -c /home /hadoop
Configurando a variável de ambiente
A seguir exportar Os comandos configurarão as variáveis de ambiente Hadoop necessárias em nosso sistema. Você pode copiar e colar tudo isso no seu terminal (pode ser necessário alterar a linha 1 se tiver uma versão diferente do Hadoop):
exportar hadoop_home =/home/hadoop/hadoop-3.1.3 exportar hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home exportar yarn_home = $ hadoop_home houlOop_Common_lib_native exportar Hadoop_Opts = "-Djava.biblioteca.caminho = $ hadoop_home/lib/nativo "Fonte do .Bashrc Arquivo na sessão de login atual:
$ fonte ~//.Bashrc
Em seguida, faremos algumas alterações no Hadoop-env.sh arquivo, que pode ser encontrado no diretório de instalação do Hadoop em /etc/hadoop. Use Nano ou seu editor de texto favorito para abri -lo:
$ nano ~/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
Mudar o Java_home variável para onde o java está instalado. Em nosso sistema (e provavelmente seu também, se você estiver executando o Ubuntu 20.04 e seguimos conosco até agora), mudamos essa linha para:
exportar java_home =/usr/lib/jvm/java-8-openjdk-amd64
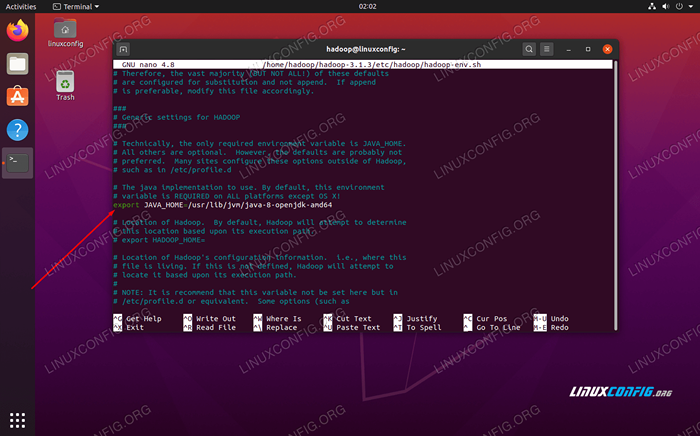 Altere a variável de ambiente java_home
Altere a variável de ambiente java_home Essa será a única mudança que precisamos fazer aqui. Você pode salvar suas alterações no arquivo e fechá -lo.
Alterações de configuração no local do núcleo.Arquivo XML
A próxima mudança que precisamos fazer é dentro do Site do núcleo.xml arquivo. Abra -o com este comando:
$ nano ~/hadoop-3.1.3/etc/Hadoop/Core-Site.xml
Digite a configuração a seguir, que instrui os HDFs a executar na porta 9000 do localhost e configura um diretório para dados temporários.
fs.Defaultfs hdfs: // localhost: 9000 hadoop.TMP.dir/home/hadoop/hadooptmpdata 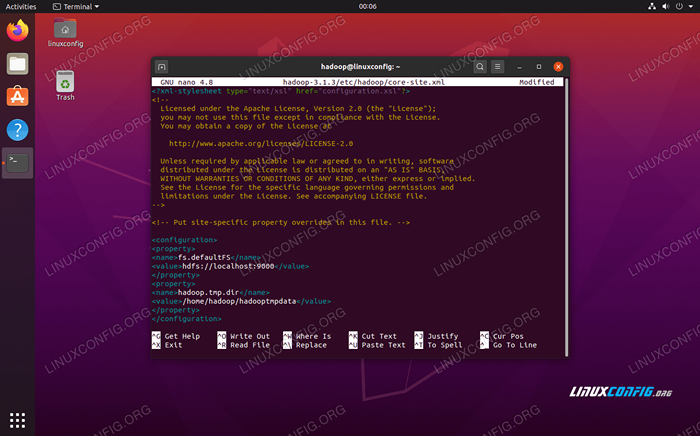 Site do núcleo.Alterações do arquivo de configuração XML
Site do núcleo.Alterações do arquivo de configuração XML Salve suas alterações e feche este arquivo. Em seguida, crie o diretório no qual dados temporários serão armazenados:
$ mkdir ~/hadooptmpdata
Alterações de configuração no site HDFS.Arquivo XML
Crie dois novos diretórios para o Hadoop armazenar as informações de Namenode e DataNode.
$ mkdir -p ~/hdfs/namenode ~/hdfs/datanode
Em seguida, edite o seguinte arquivo para dizer ao Hadoop onde encontrar esses diretórios:
$ nano ~/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
Faça as seguintes alterações no Site HDFS.xml Arquivo, antes de salvá -lo e fechá -lo:
dfs.Replicação 1 DFS.nome.Arquivo Dir: /// Home/Hadoop/HDFS/Namenode DFS.dados.Arquivo Dir: /// Home/Hadoop/HDFS/DataNode 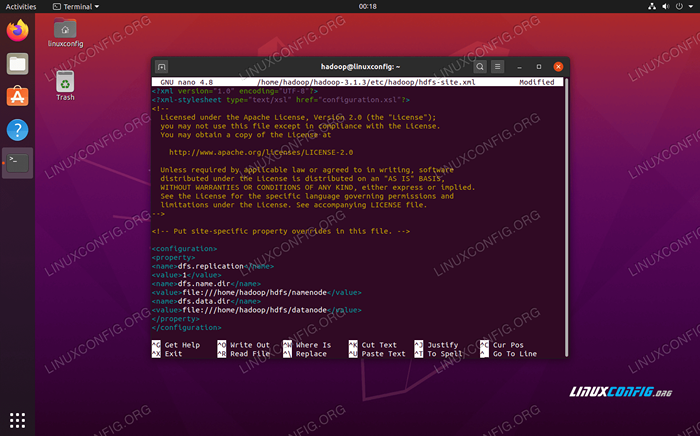 Site HDFS.Alterações do arquivo de configuração XML
Site HDFS.Alterações do arquivo de configuração XML Alterações de configuração no MapRed-Site.Arquivo XML
Abra o arquivo de configuração do MapReduce XML com o seguinte comando:
$ nano ~/hadoop-3.1.3/etc/hadoop/mapa-site.xml
E faça as seguintes alterações antes de salvar e fechar o arquivo:
MapReduce.estrutura.Nome Yarn 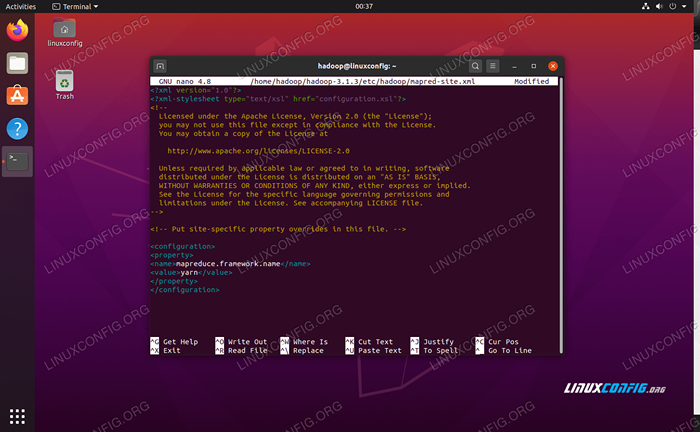 MapRed-site.Alterações do arquivo de configuração XML
MapRed-site.Alterações do arquivo de configuração XML Alterações de configuração no local do fio.Arquivo XML
Abra o arquivo de configuração de fios com o seguinte comando:
$ nano ~/hadoop-3.1.3/etc/Hadoop/Yarn-site.xml
Adicione as seguintes entradas neste arquivo, antes de salvar as alterações e fechá -lo:
MapReduceyarn.NodeManager.Aux-Services mapReduce_shuffle 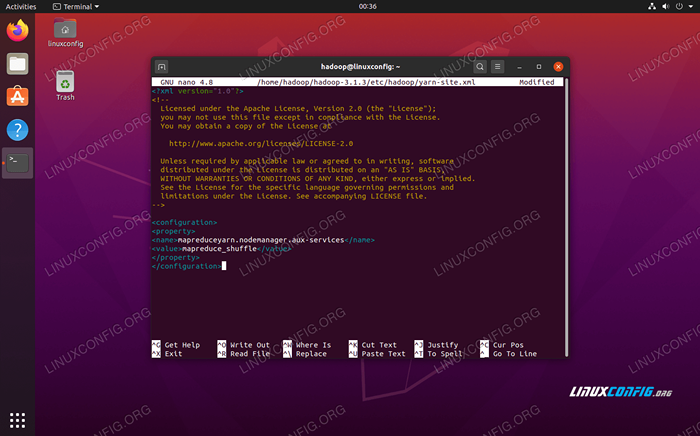 Alterações do arquivo de configuração do local do fio
Alterações do arquivo de configuração do local do fio Iniciando o cluster Hadoop
Antes de usar o cluster pela primeira vez, precisamos formatar o namenode. Você pode fazer isso com o seguinte comando:
$ hdfs namenode -format
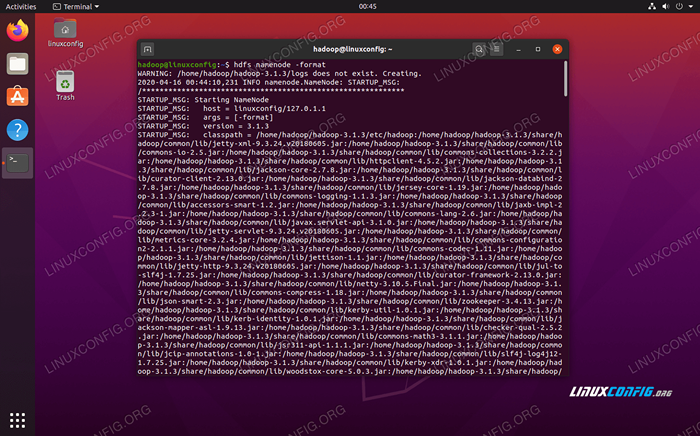 Formatando o Namenode HDFS
Formatando o Namenode HDFS Seu terminal vai cuspir muitas informações. Contanto que você não veja nenhuma mensagem de erro, você pode assumir que funcionou.
Em seguida, inicie os HDFs usando o start-dfs.sh roteiro:
$ start-dfs.sh
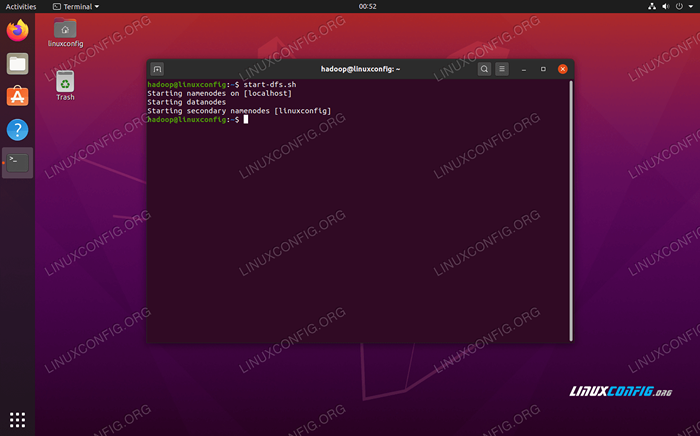 Execute o Start-DFS.script sh
Execute o Start-DFS.script sh Agora, inicie os serviços de fios via Start-yarn.sh roteiro:
$ start-yarn.sh
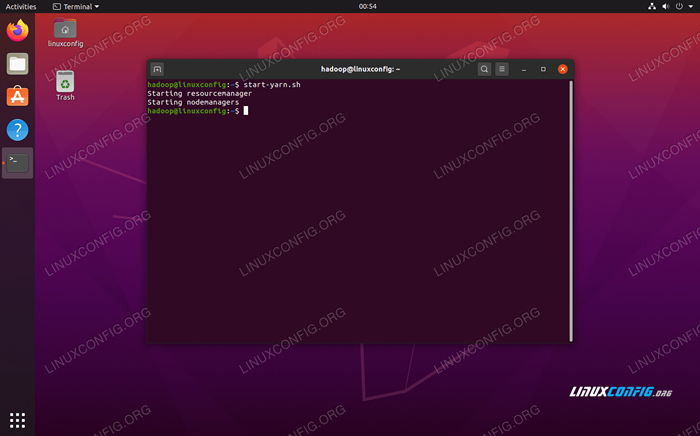 Execute o Yarn Start.script sh
Execute o Yarn Start.script sh Para verificar todos os serviços/daemons do Hadoop são iniciados com sucesso, você pode usar o JPS comando. Isso mostrará todos os processos atualmente usando o Java que estão em execução no seu sistema.
$ jps
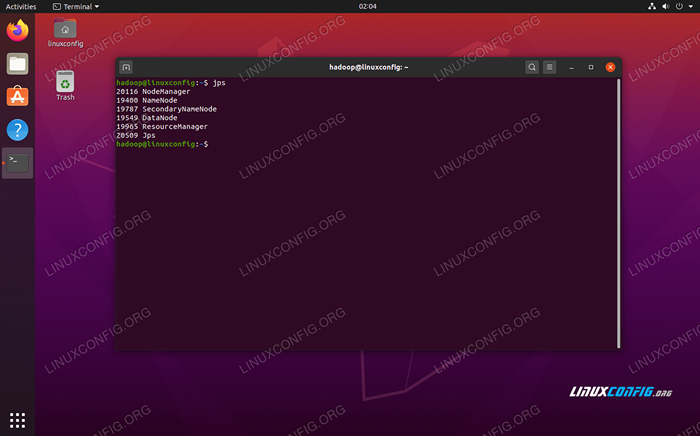 Execute os JPs para ver todos os processos dependentes de Java e verificar os componentes do Hadoop estão em execução
Execute os JPs para ver todos os processos dependentes de Java e verificar os componentes do Hadoop estão em execução Agora podemos verificar a versão atual do Hadoop com um dos seguintes comandos:
$ hadoop versão
ou
Versão $ hdfs
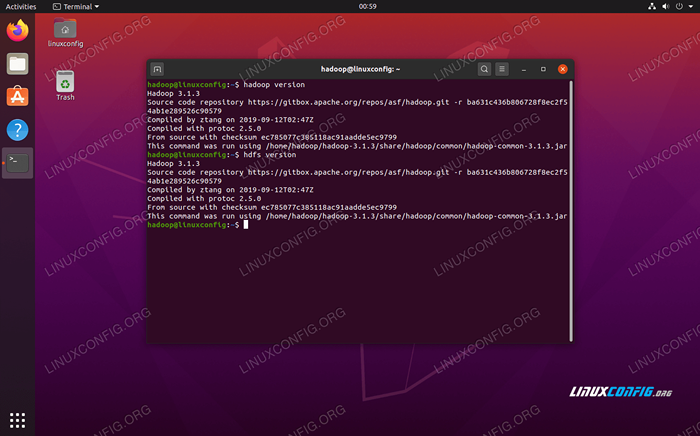 Verificando a instalação do Hadoop e a versão atual
Verificando a instalação do Hadoop e a versão atual Interface da linha de comando HDFS
A linha de comando HDFS é usada para acessar HDFs e criar diretórios ou emitir outros comandos para manipular arquivos e diretórios. Use a seguinte sintaxe de comando para criar alguns diretórios e listá -los:
$ hdfs dfs -mkdir /teste $ hdfs dfs -mkdir /hadoopoNubuntu $ hdfs dfs -ls /
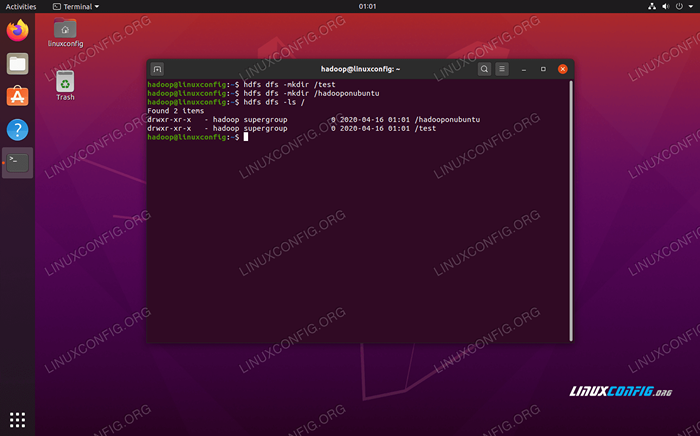 Interagindo com a linha de comando HDFS
Interagindo com a linha de comando HDFS Acesse o namenode e o fio do navegador
Você pode acessar a interface do usuário da Web para Namenode e Yarn Resource Manager por qualquer navegador de sua escolha, como Mozilla Firefox ou Google Chrome.
Para a interface da web namenode, navegue para http: // hadoop-hostname-or-ip: 50070
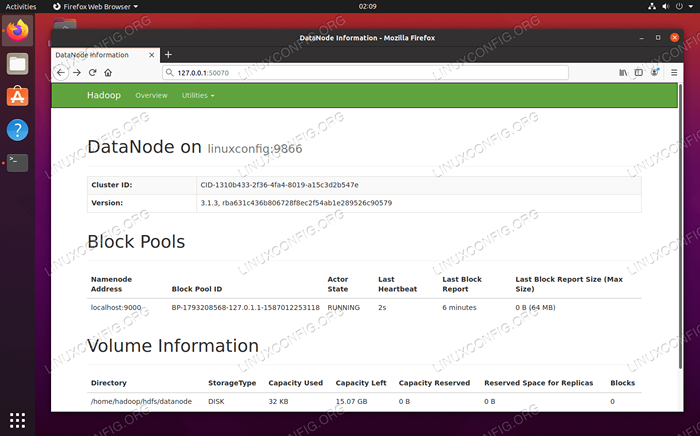 DataNode Web Interface para Hadoop
DataNode Web Interface para Hadoop Para acessar a interface da web do Yarn Resource Manager, que exibirá todos os trabalhos atualmente executando o cluster Hadoop, navegue para http: // hadoop-hostname-or-ip: 8088
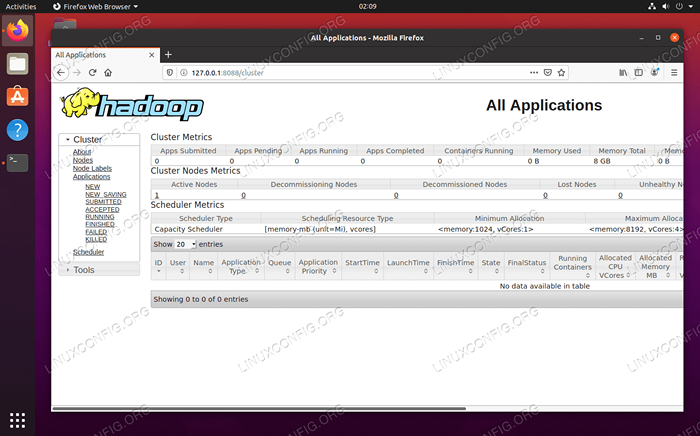 Interface da Web do Gerenciador de Recursos de Yarn para Hadoop
Interface da Web do Gerenciador de Recursos de Yarn para Hadoop Conclusão
Neste artigo, vimos como instalar o Hadoop em um único cluster de nós no Ubuntu 20.04 Fossa focal. O Hadoop nos fornece uma solução Wieldy para lidar com o Big Data, permitindo -nos utilizar clusters para armazenamento e processamento de nossos dados. Isso facilita nossa vida ao trabalhar com grandes conjuntos de dados com sua configuração flexível e interface da web conveniente.
Tutoriais do Linux relacionados:
- Coisas para instalar no Ubuntu 20.04
- Como criar um cluster Kubernetes
- Ubuntu 20.04 WordPress com instalação do Apache
- Como instalar Kubernetes no Ubuntu 20.04 fossa focal linux
- Como trabalhar com a API de Rest WooCommerce com Python
- Loops aninhados em scripts de basquete
- Coisas para fazer depois de instalar o Ubuntu 20.04 fossa focal linux
- Mastering Bash Script Loops
- Como instalar Kubernetes no Ubuntu 22.04 Jellyfish…
- Uma introdução à automação, ferramentas e técnicas do Linux
- « Crie um ubuntu inicializável 20.04 USB Stick no MS Windows 10
- Ubuntu 20.04 Requisitos do sistema »