

Como instalar e configurar o Hadoop no Ubuntu 20.04

- 3102
- 627
- Ms. Travis Schumm
O Hadoop é uma estrutura de software gratuita, de código aberto e baseado em Java, usado para o armazenamento e processamento de grandes conjuntos de dados em grupos de máquinas. Ele usa HDFs para armazenar seus dados e processar esses dados usando o MapReduce. É um ecossistema de ferramentas de big data que são usadas principalmente para mineração de dados e aprendizado de máquina.
Apache Hadoop 3.3 vem com melhorias notáveis e muitas correções de bugs nos lançamentos anteriores. Possui quatro componentes principais, como Hadoop Common, HDFs, Yarn e MapReduce.
Este tutorial explicará como instalar e configurar o Apache Hadoop no Ubuntu 20.04 LTS Linux System.
Etapa 1 - Instalando Java
Hadoop está escrito em Java e suporta apenas Java versão 8. Hadoop versão 3.3 e os mais recentes também suportam o Java 11 Runtime, bem como o Java 8.
Você pode instalar o OpenJDK 11 a partir dos repositórios APT padrão:
Atualização do sudo aptsudo apt install openjdk-11-jdk
Depois de instalado, verifique a versão instalada do Java com o seguinte comando:
Java -version Você deve obter a seguinte saída:
Versão OpenJdk "11.0.11 "2021-04-20 OpenJdk Runtime Environment (Build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK de 64 bits servidor VM (Build 11.0.11+9-Ubuntu-0ubuntu2.20.04, modo misto, compartilhamento)
Etapa 2 - Crie um usuário do Hadoop
É uma boa ideia criar um usuário separado para executar o Hadoop por razões de segurança.
Execute o seguinte comando para criar um novo usuário com o nome Hadoop:
Sudo Adduser Hadoop Forneça e confirme a nova senha como mostrado abaixo:
Adicionando o usuário 'Hadoop'… Adicionando um novo grupo 'Hadoop' (1002)… Adicionando novo usuário 'Hadoop' (1002) com grupo 'Hadoop' ... criando diretório doméstico '/home/hadoop' ... copiando arquivos de '/etc/skel' … Nova senha: reddeme a nova senha: Passwd: Senha atualizada alterando com sucesso as informações do usuário para Hadoop, insira o novo valor ou pressione Enter para o nome completo padrão []: Número da sala []: Phone de trabalho []: Telefone doméstico []: Outros []: a informação está correta? [Y/n] y
Etapa 3 - Configure a autenticação baseada em chave SSH
Em seguida, você precisará configurar a autenticação SSH sem senha para o sistema local.
Primeiro, mude o usuário para Hadoop com o seguinte comando:
Su - Hadoop Em seguida, execute o seguinte comando para gerar pares de chave pública e privada:
ssh -keygen -t rsa Você será solicitado a entrar no nome do arquivo. Basta pressionar Enter para concluir o processo:
Gerando par de chaves RSA pública/privada. Digite o arquivo para salvar a chave (/home/hadoop/.ssh/id_rsa): diretório criado '/home/hadoop/.ssh '. Digite a senha (vazia sem senha): Digite a mesma senha novamente: Sua identificação foi salva em/home/hadoop/.ssh/id_rsa Sua chave pública foi salva em/home/hadoop/.ssh/id_rsa.Pub A principal impressão digital é: sha256: qsa2syeiswp0hd+uxxxi0j9msorjkdgibkfbm3ejyik [email protegido] A imagem aleatória da chave é:+--- [rsa 3072] ----+|… o ++ = =.+ | |… Oo++.O | |. OO. B . | | o… + o * . | | = ++ o s | |.++O+ O | |.+.+ + . O | | o . o * o . | | E + . | +---- [SHA256]-----+
Em seguida, anexe as chaves públicas geradas de id_rsa.pub para autorizado_keys e definir permissão adequada:
gato ~//.ssh/id_rsa.pub >> ~///.ssh/autorizado_keyschmod 640 ~//.ssh/autorizado_keys
Em seguida, verifique a autenticação SSH sem senha com o seguinte comando:
ssh localhost Você será solicitado a autenticar hosts adicionando chaves RSA aos hosts conhecidos. Digite sim e pressione Enter para autenticar o host local:
A autenticidade do host host 'Host (127.0.0.1) 'Não pode ser estabelecido. A impressão digital da ECDSA é SHA256: JFQDVBM3ZTPHUPGD5OMJ4CLVIH6TZIRZ2GD3BDNQGMQ. Tem certeza de que deseja continuar se conectando (sim/não/[impressão digital])? sim
Etapa 4 - Instalando o Hadoop
Primeiro, mude o usuário para Hadoop com o seguinte comando:
Su - Hadoop Em seguida, faça o download da versão mais recente do Hadoop usando o comando wget:
WGet https: // downloads.apache.org/hadoop/comum/hadoop-3.3.0/Hadoop-3.3.0.alcatrão.gz Depois de baixado, extraia o arquivo baixado:
Tar -xvzf Hadoop -3.3.0.alcatrão.gz Em seguida, renomeie o diretório extraído para o Hadoop:
MV Hadoop-3.3.0 Hadoop Em seguida, você precisará configurar variáveis de ambiente Hadoop e Java em seu sistema.
Abra o ~/.Bashrc Arquivo em seu editor de texto favorito:
nano ~//.Bashrc Anexar as linhas abaixo para arquivar. Você pode encontrar o local Java_home executando Dirname $ (Dirname $ (readlink -f $ (que java)))) comando no terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$ Hadoop_home export hadoop_common_lib_native_dir = $ hadoop_home/lib/nativo caminho de exportação = $ caminho: $ hadoop_home/sbin: $ hadoop_home/bin exportar hadoop_opt = "-djava.biblioteca.caminho = $ hadoop_home/lib/nativo "
Salve e feche o arquivo. Em seguida, ative as variáveis de ambiente com o seguinte comando:
fonte ~///.Bashrc Em seguida, abra o arquivo variável do ambiente Hadoop:
nano $ hadoop_home/etc/hadoop/hadoop-env.sh Defina novamente o java_home no ambiente Hadoop.
exportar java_home =/usr/lib/jvm/java-11-openjdk-amd64
Salve e feche o arquivo quando terminar.
Etapa 5 - Configurando o Hadoop
Primeiro, você precisará criar os diretórios Namenode e DataNode dentro do Hadoop Home Directory:
Execute o seguinte comando para criar os dois diretórios:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Em seguida, edite o Site do núcleo.xml Arquive e atualize com o seu nome de host do sistema:
nano $ hadoop_home/etc/hadoop/site core.xml Altere o seguinte nome de acordo com o seu nome de host do sistema:
fs.Defaultfs hdfs: // hadoop.Tecadmin.com: 9000| 123456 | fs.Defaultfs hdfs: // hadoop.Tecadmin.com: 9000 |
Salve e feche o arquivo. Então, edite o Site HDFS.xml arquivo:
nano $ hadoop_home/etc/hadoop/hdfs-site.xml Altere o caminho do diretório Namenode e DataNode, como mostrado abaixo:
dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode| 1234567891011121314151617 | dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode |
Salve e feche o arquivo. Então, edite o MapRed-site.xml arquivo:
nano $ hadoop_home/etc/hadoop/mapa-site.xml Faça as seguintes alterações:
MapReduce.estrutura.Nome Yarn| 123456 | MapReduce.estrutura.Nome Yarn |
Salve e feche o arquivo. Então, edite o Site de fio.xml arquivo:
nano $ hadoop_home/etc/hadoop/yarn site.xml Faça as seguintes alterações:
fio.NodeManager.Aux-Services mapReduce_shuffle| 123456 | fio.NodeManager.Aux-Services mapReduce_shuffle |
Salve e feche o arquivo quando terminar.
Etapa 6 - Iniciar o Hadoop Cluster
Antes de iniciar o cluster Hadoop. Você precisará formatar o Namenode como um usuário do Hadoop.
Execute o seguinte comando para formatar o Hadoop Namenode:
HDFS Namenode -Format Você deve obter a seguinte saída:
2020-11-23 10: 31: 51.318 Informações Namenode.NnstorageretentionManager: vai reter 1 imagens com txid> = 0 2020-11-23 10: 31: 51.323 Informações Namenode.FSIMAGE: FSIMAGESAVER LIMPO Ponto de verificação: TXID = 0 Quando o encontro de desligamento. 2020-11-23 10: 31: 51.323 Informações Namenode.Namenode: Shutdown_msg: /*********************************************** *************** Shutdown_msg: Desligando o Namenode no Hadoop.Tecadmin.net/127.0.1.1 *************************************************** ***********/
Após a formatação do Namenode, execute o seguinte comando para iniciar o cluster Hadoop:
start-dfs.sh Depois que os HDFs começarem com sucesso, você deve obter a seguinte saída:
Iniciando namenodos no [Hadoop.Tecadmin.com] Hadoop.Tecadmin.com: Aviso: Adicionado permanentemente 'Hadoop.Tecadmin.com, Fe80 :: 200: 2dff: Fe3a: 26ca%eth0 '(ecdsa) para a lista de hosts conhecidos. Iniciando Datanodes iniciando Namenodes secundários [Hadoop.Tecadmin.com]
Em seguida, inicie o serviço de fio, como mostrado abaixo:
Start-yarn.sh Você deve obter a seguinte saída:
Iniciando RecursoManager iniciando NodeManagers
Agora você pode verificar o status de todos os serviços Hadoop usando o comando jps:
JPS Você deve ver todos os serviços em execução na seguinte saída:
18194 NAMENODE 18822 NodeManager 17911 Secundário 17720 DataNode 18669 ResourceManager 19151 JPS
Etapa 7 - Ajuste o firewall
O Hadoop agora está começando e ouvindo nas portas 9870 e 8088. Em seguida, você precisará permitir essas portas através do firewall.
Execute o seguinte comando para permitir conexões no Hadoop através do firewall:
firewall-cmd --permanent --add-port = 9870/tcpfirewall-cmd --permanent --Ad-port = 8088/tcp
Em seguida, recarregue o serviço Firewalld para aplicar as alterações:
Firewall-CMD--Reload Etapa 8 - Access Hadoop Namenode e Recursion Manager
Para acessar o Namenode, abra seu navegador da web e visite o URL http: // yourserver-iip: 9870. Você deve ver a seguinte tela:
http: // hadoop.Tecadmin.NET: 9870
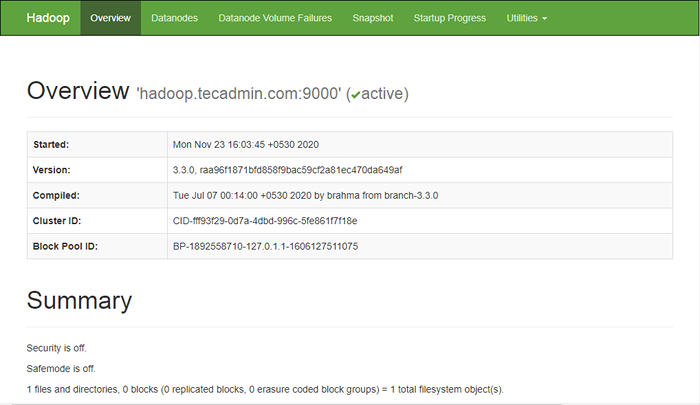
Para acessar o gerenciamento de recursos, abra seu navegador da web e visite o URL http: // yourserver-iip: 8088. Você deve ver a seguinte tela:
http: // hadoop.Tecadmin.NET: 8088
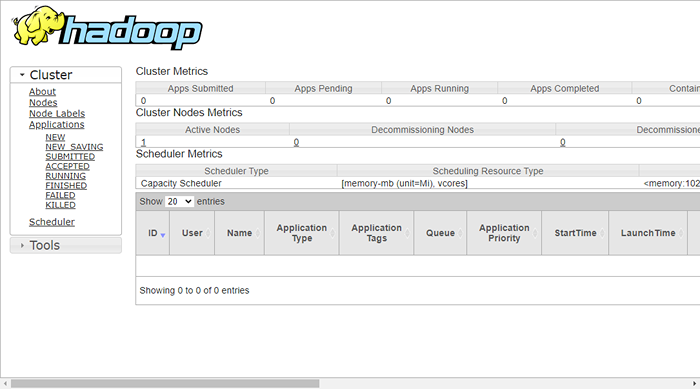
Etapa 9 - Verifique o cluster Hadoop
Neste ponto, o cluster Hadoop está instalado e configurado. Em seguida, criaremos alguns diretórios no sistema de arquivos HDFS para testar o Hadoop.
Vamos criar alguns diretórios no sistema de arquivos HDFS usando o seguinte comando:
hdfs dfs -mkdir /test1hdfs dfs -mkdir /logs
Em seguida, execute o seguinte comando para listar o diretório acima:
hdfs dfs -ls / Você deve obter a seguinte saída:
Encontrado 3 itens drwxr-xr-x-supergrupo Hadoop 0 2020-11-23 10:56 /logs drwxr-xr-x-hadoop supergrupo 0 2020-11-23 10:51 /test1
Além disso, coloque alguns arquivos no sistema de arquivos Hadoop. Para o exemplo, colocando arquivos de log da máquina host no sistema de arquivos Hadoop.
hdfs dfs -put/var/log/*/logs/ Você também pode verificar os arquivos e diretórios acima na interface da web Hadoop Namenode.
Vá para a interface da Web Namenode, clique nos utilitários => Navegue no sistema de arquivos. Você deve ver seus diretórios que você criou no início da tela a seguir:
http: // hadoop.Tecadmin.NET: 9870/Explorer.html
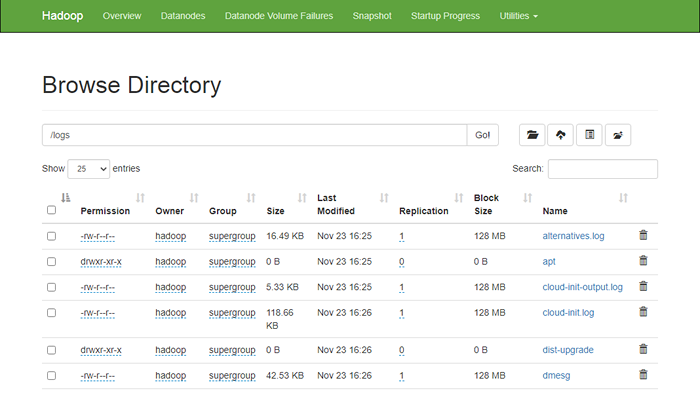
Etapa 10 - Stop Hadoop Cluster
Você também pode interromper o serviço de namenode e fios Hadoop a qualquer momento executando o Stop-dfs.sh e Stop-yarn.sh Script como usuário do Hadoop.
Para impedir o serviço Hadoop Namenode, execute o seguinte comando como usuário do Hadoop:
Stop-dfs.sh Para interromper o serviço do Hadoop Resource Manager, execute o seguinte comando:
Stop-yarn.sh Conclusão
Este tutorial explicou a você um tutorial passo a passo para instalar e configurar o Hadoop no Ubuntu 20.04 Sistema Linux.