

Linux Shell Remova linhas duplicadas do arquivo
- 3223
- 449
- Arnold Murray
Bash é uma das conchas mais populares e é usado por muitos usuários do Linux. Uma das grandes coisas que você pode fazer com o Bash é removida linhas duplicadas de arquivos. É uma ótima maneira de organizar um arquivo e torná -lo mais limpo e mais organizado. Isso pode ser feito com um comando simples no shell da festa.
Tudo que você precisa fazer é digitar o comando “Classificar -u” seguido pelo nome do arquivo. Isso levará o arquivo e classificará o conteúdo e depois usará o comando “Uniq” Para remover todas as duplicatas. É uma maneira fácil e eficiente de remover linhas duplicadas de seus arquivos. Se você é um usuário do Linux, esta é uma ótima ferramenta para ter em seu arsenal. Então, da próxima vez que você precisar limpar um arquivo, experimente este comando bash e ver como funciona para você!
Removendo linhas duplicadas do arquivo
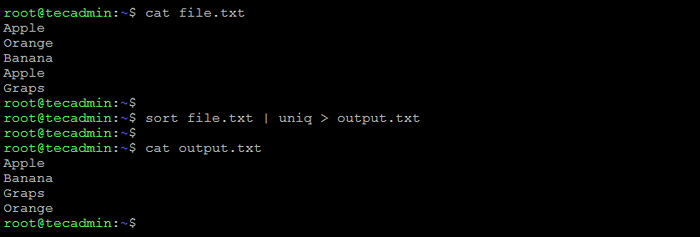
Para remover linhas duplicadas de um arquivo no bash, você pode usar os comandos de classificação e uniq.
Aqui está um exemplo de como fazer isso:
Arquivo de classificação.txt | Uniq> saída.TXT Isso vai classificar as linhas em arquivo.TXT, Remova as duplicatas e salve o resultado em um novo arquivo chamado saída.TXT.
Removendo linhas duplicadas do arquivoVocê também pode usar o -você opção do comando de classificação para alcançar o mesmo resultado:
Sort -u Arquivo.txt> saída.TXT Se você deseja remover as duplicatas no local, sem criar um novo arquivo, você pode usar o comando tee para redirecionar a saída de volta ao arquivo original:
Arquivo de classificação.txt | uniq | arquivo tee.TXT[OU]Sort -u Arquivo.txt | arquivo tee.TXT
Lembre -se de que esses comandos removerão apenas duplicatas se as linhas forem exatamente iguais. Se você deseja ignorar o espaço em branco ou as diferenças de casos, você pode usar o -eu, -b, e -f opções, respectivamente. Por exemplo:
Sort -f -u Arquivo.txt> saída.TXT Isso removerá duplicatas, ignorando as diferenças de caso.
Sort -f -b -u Arquivo.txt> saída.TXT Isso removerá duplicatas, ignorando as diferenças de casos e o espaço branco liderando/à direita.
- « Como abrir porto para uma rede específica em firewalld
- Configurando o proxy reverso nginx na frente do Apache »