

LFCs como usar o comando GNU 'sed' para criar, editar e manipular arquivos no Linux - Parte 1

- 4000
- 565
- Randal Kuhlman
A Fundação Linux anunciou o LFCs (Linux Foundation Certified Sysadmin) Certificação, um novo programa que visa ajudar indivíduos em todo o mundo a serem certificados em tarefas básicas para intermediários de administração do sistema para sistemas Linux. Isso inclui o suporte a sistemas e serviços de corrida, juntamente com a solução de problemas e a análise em primeira mão, e a tomada de decisão inteligente para escalar problemas para as equipes de engenharia.
 Linux Foundation Certified Sysadmin - Parte 1
Linux Foundation Certified Sysadmin - Parte 1 Assista ao seguinte vídeo que demonstra sobre o programa de certificação Linux Foundation.
A série será intitulada Preparação para o LFCs (Linux Foundation Certified Sysadmin) Peças 1 através 10 e cubra os seguintes tópicos para Ubuntu, Centos e OpenSUSE:
Parte 1: Como usar o comando GNU 'sed' para criar, editar e manipular arquivos no Linux Parte 2: Como instalar e usar o VI/M como um editor de texto completo Parte 3: Arquivando arquivos/diretórios e encontrar arquivos no sistema de arquivos Parte 4: Particionando dispositivos de armazenamento, formatação de sistemas de arquivos e configuração de partição de troca Parte 5: Mount/desmontar os sistemas de arquivos Local and Network (Samba & NFS) no Linux Parte 6: Montagem de partições como dispositivos RAID - Criando e gerenciando backups do sistema Parte 7: Gerenciando o processo de inicialização e serviços de inicialização do sistema (Sysvinit, Systemd e Upstart Parte 8: Gerenciando usuários e grupos, permissões e atributos e permitindo acesso a sudo em contas Parte 9: Gerenciamento de pacotes Linux com yum, rpm, apt, dpkg, aptidão e zypper Parte 10: Aprender script básico de shell e solução de problemas do sistema de arquivosImportante: Devido a alterações nos requisitos de certificação LFCS efetivos Fevereiro. 2, 2016, Estamos incluindo os seguintes tópicos necessários para a série LFCS publicada aqui. Para se preparar para este exame, você é altamente encorajado a usar a série LFCE também.
Parte 11: Como gerenciar e criar comandos LVM usando VGCreate, Lvcreate e Lvextend Parte 12: Como explorar o Linux com documentações e ferramentas de ajuda instalada Parte 13: Como configurar e solucionar problemas de grande carga unificada (grub) Parte 14: Monitorar o uso de recursos do Linux Processa e definir limites de processo por usuário Parte 15: Como definir ou modificar parâmetros de tempo de execução do kernel em sistemas Linux Parte 16: Como definir listas de controle de acesso (ACLs) e cotas de disco para usuários e grupos Parte 17: Como instalar o Cygwin, um ambiente de linha de comando do tipo Linux para Windows Parte 18: Um guia final para configurar o servidor FTP para permitir logins anônimos Parte 19: Configure um servidor DNS de cache recursivo básico e configure zonas para domínio Parte 20: Implementando controle de acesso obrigatório com Selinux ou Apparmor no LinuxEste post é parte 1 de um Série 20-Tutorial, que abrangem os domínios e competências necessários necessários para o LFCs Exame de certificação. Dito isto, aceite seu terminal e vamos começar.
Processando fluxos de texto no Linux
Linux trata a entrada e a saída de programas como fluxos (ou sequências) de caracteres. Para começar a entender o redirecionamento e os tubos, devemos primeiro entender os três tipos mais importantes de fluxos de E/S (entrada e saída), que são de fato arquivos especiais (por convenção no Unix e Linux, fluxos de dados e periféricos ou arquivos de dispositivo, também são tratados como arquivos comuns).
A diferença entre > (operador de redirecionamento) e | (Operador de pipeline) é que, embora o primeiro conecte um comando com um arquivo, este último conecta a saída de um comando com outro comando.
# comando> arquivo # comando1 | Command2
Como o operador de redirecionamento cria ou substitui os arquivos silenciosamente, devemos usá -lo com extrema cautela e nunca confundi -lo com um pipeline. Uma vantagem dos tubos nos sistemas Linux e Unix é que não há arquivo intermediário envolvido com um tubo - o stdout do primeiro comando não é gravado em um arquivo e depois lido pelo segundo comando.
Para os seguintes exercícios de prática, usaremos o poema “Uma criança feliz”(Autor anônimo).
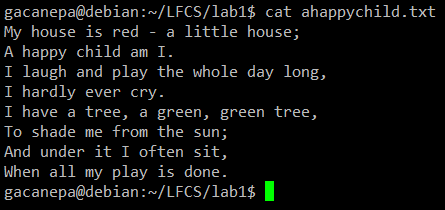 Exemplo de comando CAT
Exemplo de comando CAT Usando sed
O nome sed é curto para editor de fluxo. Para aqueles que não estão familiarizados com o termo, um editor de fluxo é usado para executar transformações básicas de texto em um fluxo de entrada (um arquivo ou entrada de um pipeline).
O uso mais básico (e popular) do SED é a substituição dos personagens. Começaremos alterando todas as ocorrências da minúscula y para maiúsculas Y e redirecionar a saída para AhappyChild2.TXT. O g O sinalizador indica que o SED deve executar a substituição para todas as instâncias de termo em todas as linhas de arquivo. Se essa bandeira for omitida, o SED substituirá apenas a primeira ocorrência de termo em cada linha.
Sintaxe básica:
# sed 's/termo/substituição/flag' arquivo
Nosso exemplo:
# sed 's/y/y/g' ahappychild.txt> AhappyChild2.TXT
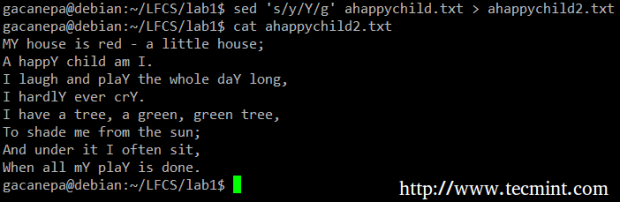 Exemplo de comando sed
Exemplo de comando sed Você deseja procurar ou substituir um personagem especial (como /, \, &) você precisa escapar dele, no termo ou em cordas de reposição, com uma barra para trás.
Por exemplo, substituiremos a palavra e por um ampera e. Ao mesmo tempo, substituiremos a palavra EU com Você Quando o primeiro é encontrado no início de uma linha.
# sed 's/e/\ &/g; s/^i/você/g'.TXT
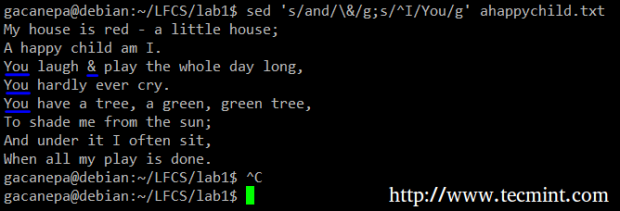 sed substitua string
sed substitua string No comando acima, um ^ (Caret Sign) é uma expressão regular bem conhecida que é usada para representar o início de uma linha.
Como você pode ver, podemos combinar dois ou mais comandos de substituição (e usar expressões regulares dentro deles) separando -os com um semicolon e envolvendo o set em citações únicas.
Outro uso de sed está mostrando (ou excluindo) uma parte escolhida de um arquivo. No exemplo seguinte, exibiremos as 5 primeiras linhas de /var/log/mensagens de 8 de junho.
# sed -n '/^8 de junho/p'/var/log/mensagens | sed -n 1,5p
Observe que, por padrão, sed imprime todas as linhas. Podemos substituir esse comportamento pelo -n opção e depois diga a sed para imprimir (indicado por p) apenas a parte do arquivo (ou o tubo) que corresponde ao padrão (8 de junho no início da linha no primeiro caso e linhas 1 a 5 inclusive no segundo caso).
Por fim, pode ser útil ao inspecionar scripts ou arquivos de configuração para inspecionar o próprio código e deixar de fora comentários. O seguinte sed uma linha exclui (d) linhas em branco ou aquelas que começam com # (o | o personagem indica um booleano ou entre as duas expressões regulares).
# sed '/^# \ |^$/d' apache2.conf
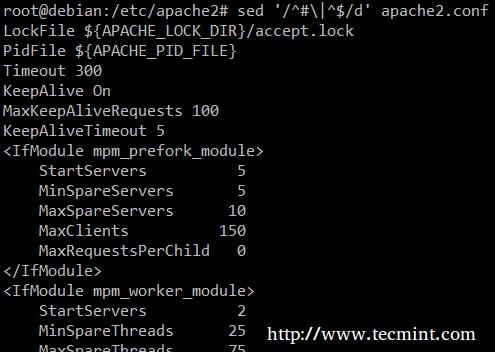 String de fósforo sed
String de fósforo sed comando uniq
O Uniq O comando nos permite relatar ou remover linhas duplicadas em um arquivo, escrevendo para stdout por padrão. Devemos observar que Uniq não detecta linhas repetidas, a menos que sejam adjacentes. Por isso, Uniq é comumente usado junto com um anterior organizar (que é usado para classificar linhas de arquivos de texto). Por padrão, organizar leva o primeiro campo (separado por espaços) como campo -chave. Para especificar um campo chave diferente, precisamos usar o -k opção.
Exemplos
O du -sch/path/to/diretório/* O comando retorna o uso do espaço em disco por subdiretos e arquivos no diretório especificado em formato legível por humanos (também mostra um diretório total) e não solicita a saída por tamanho, mas por subdiretório e nome do arquivo. Podemos usar o seguinte comando para classificar por tamanho.
# du -sch /var /* | classificar -h
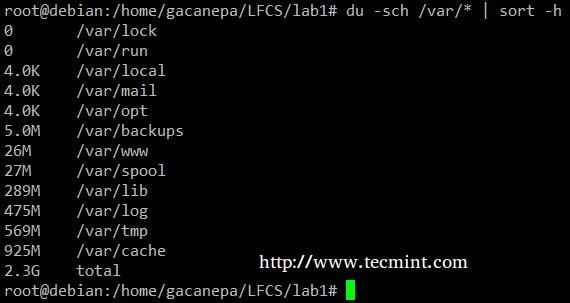 classificar exemplo de comando
classificar exemplo de comando Você pode contar o número de eventos em um log por data, dizendo Uniq Para realizar a comparação usando os 6 primeiros caracteres (-w 6) de cada linha (onde a data é especificada) e prefixando cada linha de saída pelo número de ocorrências (-c) com o seguinte comando.
# gato/var/log/e -mail.log | uniq -c -w 6
 Contar números no arquivo
Contar números no arquivo Finalmente, você pode combinar organizar e Uniq (como eles geralmente são). Considere o seguinte arquivo com uma lista de doadores, data de doação e valor. Suponha que queremos saber quantos doadores únicos existem. Usaremos o seguinte comando para cortar o primeiro campo (os campos são delimitados por um cólon), classificar pelo nome e remover linhas duplicadas.
# gato sortuniq.txt | corte -d: -f1 | classificar | Uniq
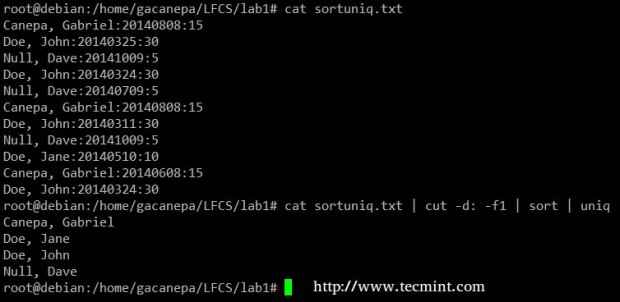 Encontre registros exclusivos no arquivo
Encontre registros exclusivos no arquivo Leia também: 13 Exemplos de comando “CAT”
Comando Grep
grep Pesquisa arquivos de texto ou (saída de comando) para a ocorrência de uma expressão regular especificada e produz qualquer linha que contenha uma correspondência com saída padrão.
Exemplos
Exibir as informações de /etc/passwd Para o usuário Gacanepa, ignorando o caso.
# grep -i gacanepa /etc /passwd
 Exemplo de comando grep
Exemplo de comando grep Mostrar todo o conteúdo de /etc cujo nome começa com rc seguido por qualquer número único.
# ls -l /etc | Grep RC [0-9]
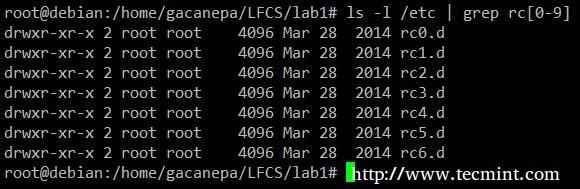 Liste o conteúdo usando Grep
Liste o conteúdo usando Grep Leia também: 12 Exemplos de comando “Grep”
Uso do comando TR
O tr O comando pode ser usado para traduzir (alterar) ou excluir caracteres do stdin e escrever o resultado para stdout.
Exemplos
Altere tudo em minúsculas para maiúsculas no Sortuniq.arquivo txt.
# gato sortuniq.txt | TR [: Lower:] [: Upper:]
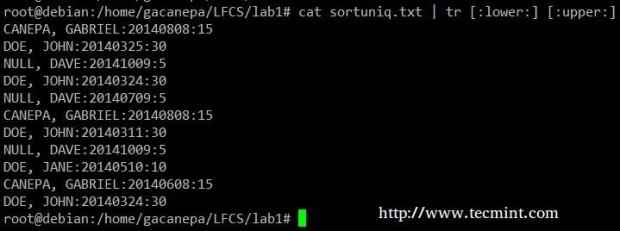 Classificar seqüências de caracteres no arquivo
Classificar seqüências de caracteres no arquivo Aperte o delimitador na saída de ls -l para apenas um espaço.
# ls -l | tr -s "
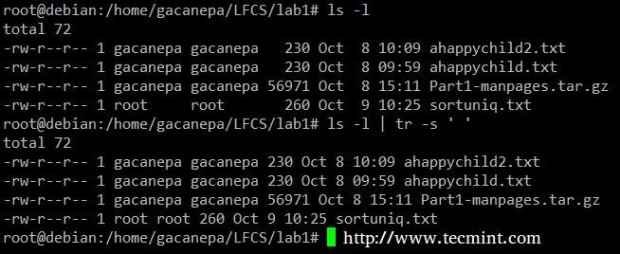 Delimitador de aperto
Delimitador de aperto Corte o uso do comando
O corte O comando extrai partes das linhas de entrada (de stdin ou arquivos) e exibe o resultado na saída padrão, com base no número de bytes (-b opção), caracteres (-c), ou campos (-f). Neste último caso (baseado em campos), o separador de campo padrão é uma guia, mas um delimitador diferente pode ser especificado usando o -d opção.
Exemplos
Extraia as contas de usuário e os conchos padrão atribuídos a eles de /etc/passwd (o -d a opção nos permite especificar o delimitador de campo e o -f Switch indica qual (s) campo (s) será extraído.
# gato /etc /passwd | corte -d: -f1,7
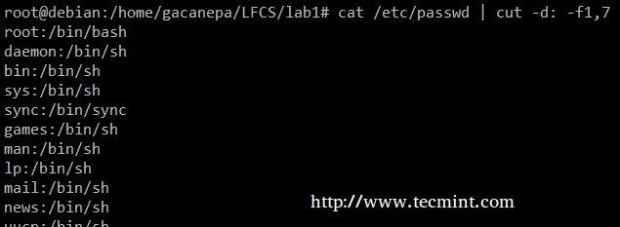 Extraia contas de usuário
Extraia contas de usuário Resumindo, criaremos um fluxo de texto que consiste no primeiro e terceiro arquivos não em branco da saída do durar comando. Nós vamos usar grep Como primeiro filtro a verificar se há sessões de usuário Gacanepa, Em seguida, aperte os delimitadores para apenas um espaço (tr -s"). Em seguida, extrairemos o primeiro e o terceiro campos com corte, e finalmente classificar pelo segundo campo (endereços IP neste caso) mostrando exclusivos.
# último | grep gacanepa | tr -s "| corte -d" -f1,3 | classificar -k2 | Uniq
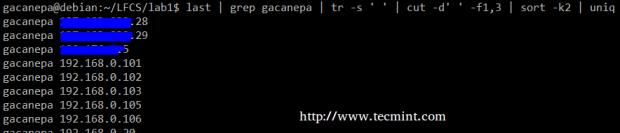 Último exemplo de comando
Último exemplo de comando O comando acima mostra como vários comandos e tubos podem ser combinados para obter dados filtrados de acordo com nossos desejos. Sinta -se à vontade para executá -lo por peças, para ajudá -lo a ver a saída que é pipelada de um comando para o próximo (essa pode ser uma ótima experiência de aprendizado, a propósito!).
Resumo
Embora este exemplo (junto com o restante dos exemplos no tutorial atual) possa não parecer muito útil à primeira vista, eles são um bom ponto de partida para começar a experimentar comandos usados para criar, editar e manipular arquivos do Linux linha de comando. Sinta -se à vontade para deixar suas perguntas e comentários abaixo - eles serão muito apreciados!
Links de referência
- Sobre os LFCs
- Por que obter uma certificação Linux Foundation?
- Registre -se para o exame LFCS
- « LFCs como instalar e usar o VI/VIM como um editor de texto completo - Parte 2
- WPScan - um scanner de vulnerabilidade do WordPress de caixa preta »