

Introdução ao Python Web Rasping e The Beautiful Soup Library
- 2414
- 309
- Loren Botsford
Objetivo
Aprendendo a extrair informações de uma página HTML usando Python e a bela Biblioteca de Sopa.
Requisitos
- Compreensão do básico da programação de Python e de objetos
Convenções
- # - exige que o comando linux seja executado com privilégios de raiz também
diretamente como usuário root ou por uso desudocomando - $ - Dado o comando Linux a ser executado como um usuário não privilegiado regular
Introdução
A raspagem na web é uma técnica que consiste na extração de dados de um site através do uso de software dedicado. Neste tutorial, veremos como realizar uma raspagem básica da web usando Python e a bela Biblioteca de Sopa. Nós vamos usar Python3 Visando a página inicial de Rotten Tomatoes, o famoso agregador de críticas e notícias para filmes e programas de TV, como fonte de informação para o nosso exercício.
Instalação da bela Biblioteca de Sopa
Para realizar nossa raspagem, usaremos a bela biblioteca de Python, portanto, a primeira coisa que precisamos fazer é instalá -la. A biblioteca está disponível nos repositórios de todas as principais distribuições GNU \ Linux; portanto, podemos instalá -lo usando nosso gerenciador de pacotes favorito ou usando pip, A maneira nativa do Python para instalar pacotes.
Se o uso do gerenciador de pacotes de distribuição for preferido e estamos usando o Fedora:
$ sudo dnf install python3-beautifulsoup4
No Debian e seus derivados, o pacote é chamado BeautifulSoup4:
$ sudo apt-get install BeautifulSoup4
No Archilinux, podemos instalá -lo via Pacman:
$ sudo pacman -s python -beatufilusoup4
Se queremos usar pip, Em vez disso, podemos simplesmente correr:
$ PIP3 Instalação -User BeautifulSoup4
Executando o comando acima com o --do utilizador Flag, instalaremos a versão mais recente da bela biblioteca de sopa apenas para o nosso usuário, portanto, não é necessária permissões de raiz. É claro que você pode decidir usar o PIP para instalar o pacote globalmente, mas pessoalmente eu prefiro instalações por usuários quando não estiver usando o gerenciador de pacotes de distribuição.
O objeto de belo grupo
Vamos começar: a primeira coisa que queremos fazer é criar um objeto de belo grupo. O construtor de belas grupos aceita um corda ou um identificador de arquivo como seu primeiro argumento. O último é o que nos interessa: temos o URL da página que queremos raspar, portanto usaremos o urlopen Método do urllib.solicitar Biblioteca (instalada por padrão): Este método retorna um objeto semelhante a um arquivo:
do BS4 Import BeautifulSoup de Urllib.Solicite Urlopen de importação com Urlopen ('http: // www.tomates podres.com ') como página inicial: sopa = beautifulSoup (página inicial) Neste ponto, nossa sopa está pronta: o sopa objeto representa o documento na íntegra. Podemos começar a navegar e extrair os dados que queremos usar os métodos e propriedades internos. Por exemplo, digamos que queremos extrair todos os links contidos na página: sabemos que os links são representados pelo a tag em html e o link real está contido no Href atributo da tag, para que possamos usar o encontrar tudo Método do objeto que acabamos de construir para realizar nossa tarefa:
para link na sopa.find_all ('a'): print (link.get ('href')) Usando o encontrar tudo método e especificação a Como o primeiro argumento, que é o nome da tag, pesquisamos todos os links na página. Para cada link, recuperamos e imprimimos o valor do Href atributo. Em BeautifulSoup, os atributos de um elemento são armazenados em um dicionário, portanto, recuperá -los é muito fácil. Nesse caso, usamos o pegar Método, mas poderíamos ter acessado o valor do atributo href, mesmo com a seguinte sintaxe: link ['href']. O próprio atributo completo dicionário está contido no attrs propriedade do elemento. O código acima produzirá o seguinte resultado:
[…] Https: // editorial.tomates podres.com/https: // editorial.tomates podres.com/24 frames/https: // editorial.tomates podres.com/binge-guide/https: // editorial.tomates podres.com/box-office-guru/https: // editorial.tomates podres.com/críticos-consenso/https: // editorial.tomates podres.com/cinco favoritos filmes/https: // editorial.tomates podres.com/agora streaming/https: // editorial.tomates podres.com/parental-guidância/https: // editorial.tomates podres.COM/RED-CARPET-ROUNDUP/HTTPS: // Editorial.tomates podres.com/rt-on-dvd/https: // editorial.tomates podres.com/the-simpsons-decade/https: // editorial.tomates podres.com/subcult/https: // editorial.tomates podres.com/Tech-Talk/https: // editorial.tomates podres.com/ total-recall/ […]
A lista é muito mais longa: o exposto acima é apenas um extrato da saída, mas oferece uma ideia. O encontrar tudo Método retorna tudo Marcação objetos que correspondem ao filtro especificado. No nosso caso, acabamos de especificar o nome da tag que deve ser correspondente e nenhum outro critério, para que todos os links sejam retornados: veremos em um momento como restringir ainda mais nossa pesquisa.
Um caso de teste: recuperando todos os títulos de “bilheteria superior”
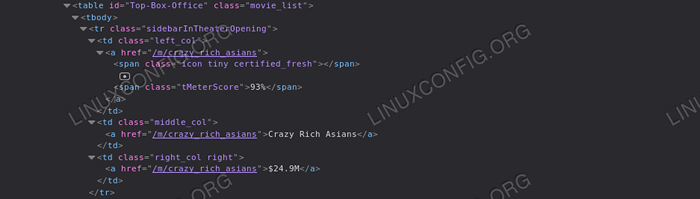
Vamos realizar uma raspagem mais restrita. Digamos que queremos recuperar todos os títulos dos filmes que aparecem na seção "Top Box Office" da página inicial do Rotten Tomatoes. A primeira coisa que queremos fazer é analisar a página html para essa seção: fazendo isso, podemos observar que o elemento que precisamos está todos contidos dentro de um mesa elemento com o "top-box-office" eu ia:
Top Box Office Também podemos observar que cada linha da tabela possui informações sobre um filme: as pontuações do título estão contidas como texto dentro de um período Elemento com a classe “tmeterscore” dentro da primeira célula da linha, enquanto a string representando o título do filme está contida na segunda célula, como o texto do a marcação. Finalmente, a última célula contém um link com o texto que representa os resultados das bilheterias do filme. Com essas referências, podemos recuperar facilmente todos os dados que queremos:
do BS4 Import BeautifulSoup de Urllib.Solicite Urlopen de importação com Urlopen ('https: // www.tomates podres.com ') como página inicial: sopa = beautifulSoup (página inicial.leia (), 'html.Parser ') # Primeiro, usamos o método de localização para recuperar a tabela com o ID' Top-Box-Office 'top_box_office_table = sopa.LINDO ('TABLE', 'ID': 'Top-box-office') # do que iteramos em cada linha e extraímos informações de filmes para linha em top_box_office_table.Find_all ('tr'): células = linha.find_all ('td') title = células [1].encontre um').get_text () dinheiro = células [2].encontre um').get_text () pontuação = linha.encontre ('span', 'class': 'tmeterscore').get_text () print ('0 - 1 (tomatômetro: 2)'.formato (título, dinheiro, pontuação)) O código acima produzirá o seguinte resultado:
Asiáticas ricas loucas - US $ 24.9m (tomatômetro: 93%) O MEG - $ 12.9m (tomatômetro: 46%) Os assassinatos do happytime - \ $ 9.6m (tomatômetro: 22%) Missão: Impossível - Fallout - $ 8.2m (tomatômetro: 97%) Milha 22 - $ 6.5m (tomatômetro: 20%) Christopher Robin - $ 6.4m (tomatômetro: 70%) Alpha - $ 6.1m (tomatômetro: 83%) Blackkklansman - US $ 5.2m (tomatômetro: 95%) Slender Man - $ 2.9m (tomatômetro: 7%) A.X.eu. -- $ 2.8m (tomatômetro: 29%)
Introduzimos alguns novos elementos, vamos vê -los. A primeira coisa que fizemos é recuperar o mesa com ID 'de primeira linha', usando o encontrar método. Este método funciona de maneira semelhante a encontrar tudo, Mas enquanto o último retorna uma lista que contém as partidas encontradas ou está vazia se não houver correspondência, os primeiros retornos sempre o primeiro resultado ou Nenhum Se um elemento com os critérios especificados não for encontrado.
O primeiro elemento fornecido ao encontrar O método é o nome da tag a ser considerada na busca, neste caso mesa. Como segundo argumento, passamos um dicionário no qual cada chave representa um atributo da tag com seu valor correspondente. Os pares de valor-chave fornecidos no dicionário representa os critérios que devem ser satisfeitos para que nossa pesquisa produza uma correspondência. Nesse caso, procuramos o eu ia atributo com valor de “caixa superior”. Observe que desde cada eu ia Deve ser único em uma página HTML, poderíamos ter omitido o nome da tag e usar esta sintaxe alternativa:
top_box_office_table = sopa.encontre (id = 'top-box-office') Depois que recuperamos nossa mesa Marcação objeto, usamos o encontrar tudo método para encontrar todas as linhas e iterar sobre eles. Para recuperar os outros elementos, usamos os mesmos princípios. Também usamos um novo método, get_text: ele retorna apenas a parte do texto contida em uma tag, ou se nenhuma for especificada em toda a página. Por exemplo, sabendo que a porcentagem de pontuação do filme é representada pelo texto contido no período elemento com o tmeterscore classe, usamos o get_text método no elemento para recuperá -lo.
Neste exemplo, acabamos de exibir os dados recuperados com uma formatação muito simples, mas em um cenário do mundo real, poderíamos querer realizar mais manipulações ou armazená-lo em um banco de dados.
Conclusões
Neste tutorial, acabamos de arranhar a superfície do que podemos fazer usando Python e Beautiful Soup Library para realizar raspagem na web. A biblioteca contém muitos métodos que você pode usar para uma pesquisa mais refinada ou para navegar melhor na página: para isso, recomendo fortemente consultar os documentos oficiais muito bem escritos.
Tutoriais do Linux relacionados:
- Coisas para instalar no Ubuntu 20.04
- Uma introdução à automação, ferramentas e técnicas do Linux
- Coisas para fazer depois de instalar o Ubuntu 20.04 fossa focal linux
- Mastering Bash Script Loops
- Mint 20: Melhor que o Ubuntu e o Microsoft Windows?
- Comandos Linux: os 20 comandos mais importantes que você precisa para…
- Comandos básicos do Linux
- Como construir um aplicativo Tknter usando um objeto orientado…
- Ubuntu 20.04 WordPress com instalação do Apache
- Como montar a imagem ISO no Linux