

Introdução ao Glusterfs (sistema de arquivos) e instalação no RHEL/CENTOS e FEDORA

- 5102
- 178
- Mrs. Christopher Okuneva
Estamos vivendo em um mundo onde os dados estão crescendo de uma maneira imprevisível e é nossa necessidade de armazenar esses dados, seja estruturado ou não estruturado, de maneira eficiente. Os sistemas de computação distribuídos oferecem uma ampla variedade de vantagens sobre os sistemas de computação centralizados. Aqui os dados são armazenados de maneira distribuída com vários nós como servidores.
Armazenamento Glusterfs O conceito de um servidor de metadados não é mais necessário em um sistema de arquivos distribuído. Em sistemas de arquivos distribuídos, ele oferece um ponto de visualização comum de todos os arquivos separados entre diferentes servidores. Arquivos/diretórios nesses servidores de armazenamento são acessados de maneiras normais.
Por exemplo, as permissões para arquivos/diretórios podem ser definidas como no modelo de permissão do sistema usual, i i.e. o proprietário, o grupo e outros. O acesso ao sistema de arquivos depende basicamente de como o protocolo específico foi projetado para funcionar no mesmo.
O que é Glusterfs?
Glusterfs é um sistema de arquivos distribuído definido para ser usado no espaço do usuário, eu.e. Sistema de arquivos no espaço do usuário (FUSÍVEL). É um sistema de arquivos baseado em software que explica seu próprio recurso de flexibilidade.
Veja a figura a seguir, que representa esquematicamente a posição de Glusterfs em um modelo hierárquico. Por padrão, o protocolo TCP será usado por Glusterfs.
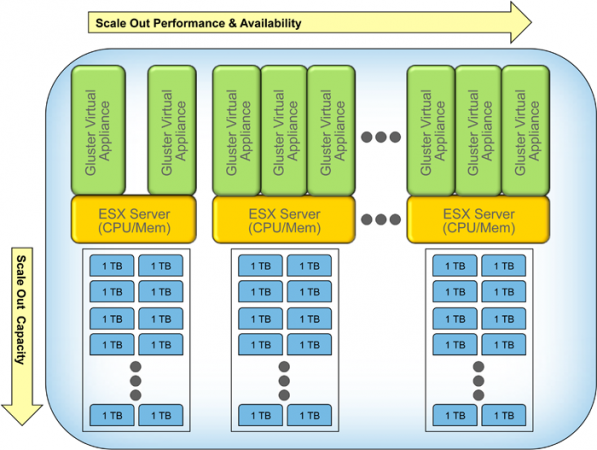 Design de Glusterfs
Design de Glusterfs Vantagens para Glusterfs
- Inovação - Ele elimina os metadados e pode melhorar dramticamente o desempenho que nos ajudará a unificar dados e objetos.
- Elasticidade - Adaptado ao crescimento e redução do tamanho dos dados.
- Escala linearmente - Tem disponibilidade para petabytes e além.
- Simplicidade - É fácil de gerenciar e independente do kernel enquanto executa no espaço do usuário.
O que torna o gluster excelente, entre outros sistemas de arquivos distribuídos?
- Vendável - Ausência de um servidor de metadados fornece um sistema de arquivos mais rápido.
- Acessível - Ele implanta em hardware de commodity.
- Flexível - Como eu disse anteriormente, Glusterfs é um sistema de arquivos apenas de software. Aqui os dados são armazenados em sistemas de arquivos nativos como ext4, xfs etc.
- Código aberto - Atualmente, o Glusterfs é mantido pela Red Hat Inc, uma empresa de código aberto de bilhões de dólares, como parte do Red Hat Storage.
Conceitos de armazenamento em Glusterfs
- Tijolo - Brick é basicamente qualquer diretório que deve ser compartilhado entre o pool de armazenamento confiável.
- Pool de armazenamento confiável - é uma coleção desses arquivos/diretórios compartilhados, que são baseados no protocolo projetado.
- Bloquear armazenamento - São dispositivos através dos quais os dados estão sendo movidos através de sistemas na forma de blocos.
- Conjunto - No Red Hat Storage, o cluster e o conjunto de armazenamento confiável transmitem o mesmo significado de colaboração de servidores de armazenamento com base em um protocolo definido.
- Sistema de arquivos distribuído - Um sistema de arquivos no qual os dados estão espalhados por diferentes nós onde os usuários podem acessar o arquivo sem saber o local real do arquivo. O usuário não experimenta a sensação de acesso remoto.
- FUSÍVEL - É um módulo de kernel carregável que permite aos usuários criar sistemas de arquivos acima do kernel sem envolver nenhum código do kernel.
- Glusterd - Glusterd é o daemon de gerenciamento Glusterfs, que é a espinha dorsal do sistema de arquivos que estará em execução o tempo todo sempre que os servidores estiverem em estado ativo.
- Posix - A interface do sistema operacional portátil (POSIX) é a família de padrões definidos pelo IEEE como uma solução para a compatibilidade entre os variantes UNIX na forma de uma interface programável de aplicativo (API).
- ATAQUE - A variedade redundante de discos independentes (RAID) é uma tecnologia que oferece maior confiabilidade de armazenamento através da redundância.
- Subvolume - Um tijolo depois de ser processado pelo menos em um tradutor.
- Tradutor - Um tradutor é aquele pedaço de código que executa as ações básicas iniciadas pelo usuário a partir do ponto de montagem. Ele conecta um ou mais sub -volumes.
- Volume - A Volumes é uma coleção lógica de tijolos. Todas as operações são baseadas nos diferentes tipos de volumes criados pelo usuário.
Diferentes tipos de volumes
Representações de diferentes tipos de volumes e combinações entre esses tipos básicos de volume também são permitidos, como mostrado abaixo.
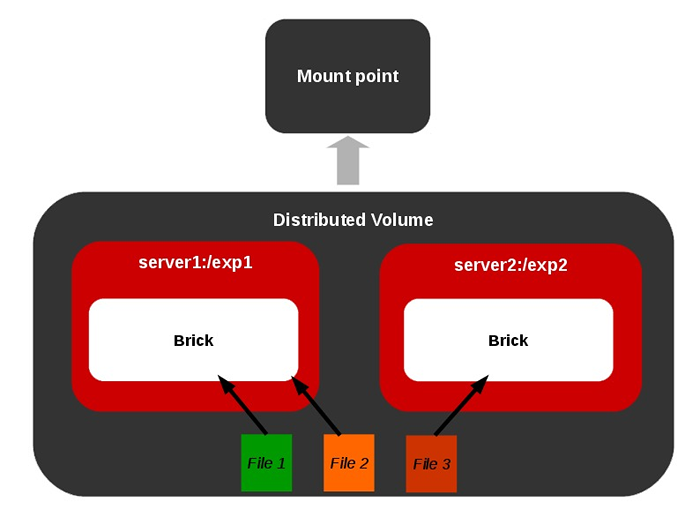 Volume distribuído
Volume distribuído 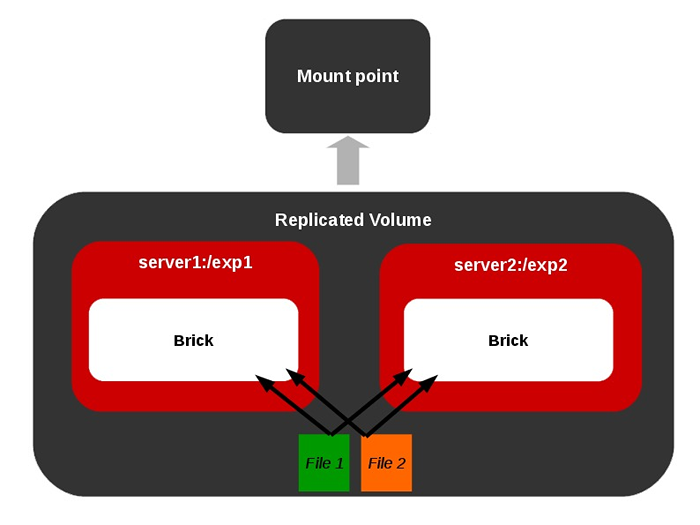 Volume replicado
Volume replicado 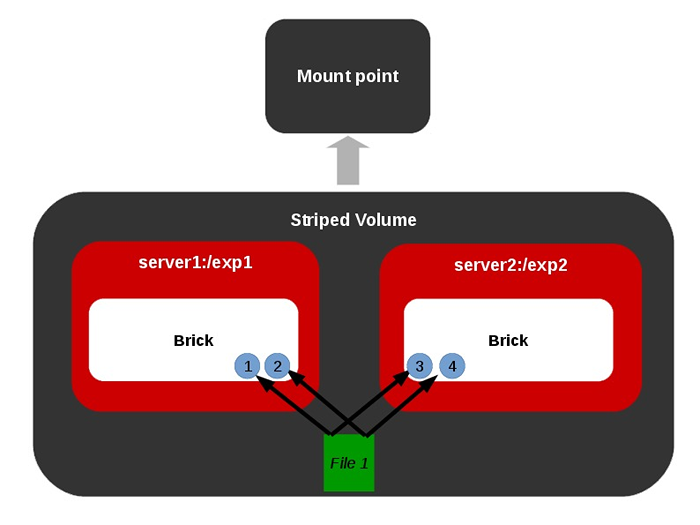 Volume listrado
Volume listrado Volume replicado distribuído
Representação de um volume replicado distribuído.
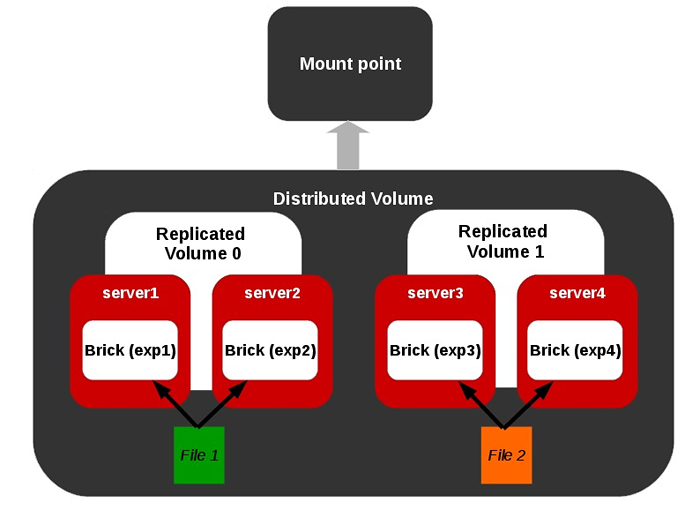 Volume replicado distribuído
Volume replicado distribuído Instalação de Glusterfs em Rhel/Centos e Fedora
Neste artigo, estaremos instalando e configurando o Glusterfs pela primeira vez para uma alta disponibilidade de armazenamento. Para isso, estamos levando dois servidores para criar volumes e replicar dados entre eles.
Etapa: 1 tenho pelo menos dois nós
- Instalar CENTOS 6.5 (ou qualquer outro sistema operacional) em dois nós.
- Defina nomes de host denominados “servidor1" e "Server2““.
- Uma conexão de rede de trabalho.
- Disco de armazenamento em ambos os nós chamados “/dados/tijolo““.
Etapa 2: Ativar repositório Epel e Glusterfs
Antes de instalar Glusterfs em ambos os servidores, precisamos ativar EPEL e Glusterfs Repositórios para satisfazer dependências externas. Use o link a seguir para instalar e ativar o repositório EPEL nos dois sistemas.
- Como ativar o repositório EPEL em Rhel/Centos
Em seguida, precisamos ativar o repositório Glusterfs em ambos os servidores.
# wget -p /etc /yum.Repos.d http: // download.gluster.org/pub/gluster/glusterfs/mais recente/epel.Repo/Glusterfs -epel.repo
Etapa 3: Instalando Glusterfs
Instale o software em ambos os servidores.
# yum install glusterfs-server
Inicie o daemon de gerenciamento Glusterfs.
# Service Glusterd Start
Agora verifique o status do daemon.
# status de serviço Glusterd
Saída de amostra
Serviço Glusterd Start Service Glusterd Status Glusterd.Serviço - LSB: servidor Glusterfs carregado: carregado (/etc/rc.d/init.D/Glusterd) ativo: ativo (em execução) desde segunda -feira, 13 de agosto de 2012 13:02:11 -0700; 2s atrás do processo: 19254 ExecStart =/etc/rc.d/init.D/Glusterd Start (Code = EXITED, STATUS = 0/SUCCESSO) CGROUP: Nome = Systemd:/System/Glusterd.Serviço ├ 19260/usr/sbin/glusterd -p/run/glusterd.pid ├ 19304/usr/sbin/glusterfsd --xlator-opção georep-server.Ouça -se -port = 24009 -s localhost… └ 19309/usr/sbin/glusterfs -f/var/lib/glusterd/nfs/nfs -server.Vol -p/var/lib/glusterd/…
Etapa 4: Configure o Selinux e iptables
Abrir '/etc/sysconfig/Selinux'e mude o Selinux para qualquer umpermissivo" ou "desabilitado”Modo em ambos os servidores. Salve e feche o arquivo.
# Este arquivo controla o estado de Selinux no sistema. # Selinux = pode levar um desses três valores: # aplicação - a Política de Segurança do Selinux é aplicada. # Permissivo - Selinux impressa avisos em vez de aplicar. # desativado - nenhuma política de Selinux é carregada. Selinux = desativado # SelinuxType = pode levar um desses dois valores: # direcionado - processos direcionados são protegidos, # MLS - Proteção de segurança de vários níveis. SelinuxType = direcionado
Em seguida, lave os iptables nos dois nós ou precisam permitir o acesso ao outro nó via iptables.
# iptables -f
Etapa 5: Configure o pool confiável
Execute o seguinte comando em 'Servidor1'.
Gluster Peer Prove Server2
Execute o seguinte comando em 'Server2'.
Gluster Peer Probe Server1
Observação: Depois que este pool estiver conectado, apenas usuários confiáveis podem investigar novos servidores neste pool.
Etapa 6: Configure um volume Glusterfs
Nos dois servidor1 e Server2.
# mkdir/dados/tijolo/gv0
Crie um volume em um único servidor e inicie o volume. Aqui eu peguei 'Servidor1'.
# Gluster Volume Create GV0 Replica 2 Server1:/Data/Brick1/GV0 Server2:/Data/Brick1/GV0 # Gluster Volume Iniciar GV0
Em seguida, confirme o status do volume.
# Informações de volume de brilho
Observação: Se o volume no caso não for iniciado, as mensagens de erro serão registradas em '/var/log/glusterfs'em um ou em ambos os servidores.
Etapa 7: Verifique o volume Glusterfs
Monte o volume para um diretório abaixo '/mnt'.
# Mount -t Glusterfs Server1: /GV0 /MNT
Agora você pode criar, editar arquivos no ponto de montagem como uma única visão do sistema de arquivos.
Recursos de Glusterfs
- Auto cura - Se algum dos tijolos em um volume replicado estiver inativo e os usuários modificarem os arquivos dentro do outro tijolo, o daemon automático de auto-cura entrará em ação assim que o tijolo chegar na próxima vez e as transações ocorreram durante o tempo de inatividade for sincronizado de acordo.
- Reequilíbrio - Se adicionarmos um novo tijolo a um volume existente, onde uma grande quantidade de dados residia anteriormente, podemos realizar uma operação de reequilíbrio para distribuir os dados entre todos os tijolos, incluindo o recém -adicionado tijolo.
- Replicação geográfica - Ele fornece backups de dados para recuperação de desastres. Aí vem o conceito de volumes de mestre e escravo. De modo que se o mestre estiver baixo, todos os dados podem ser acessados por escravo. Este recurso é usado para sincronizar dados entre servidores geograficamente separados. A inicialização de uma sessão de replicação geo requer uma série de comandos gluster.
Aqui está a seguinte captura de tela que mostra o módulo de replicação geográfica.
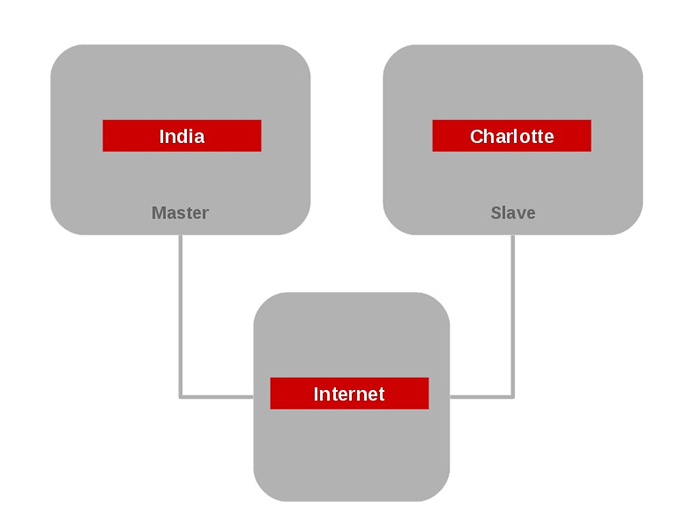 Replicação geográfica
Replicação geográfica Links de referência
Glusterfs Página inicial
É isso por agora!. Mantenha-se atualizado para a descrição detalhada sobre recursos como auto-curas e re-equilíbrio, replicação geográfica, etc. nos meus próximos artigos.
- « nsnake Um clone do antigo jogo de cobra clássico - jogo no terminal Linux
- 10 perguntas e respostas da entrevista em vários comandos no Linux »