

Como configurar o Hadoop no Ubuntu 18.04 e 16.04 LTS

- 4228
- 303
- Wendell Legros
Apache Hadoop 3.1 têm melhorias perceptíveis de muitas correções de bugs em relação ao estável 3 anterior.0 liberações. Esta versão tem muitas melhorias no HDFS e MapReduce. Este tutorial ajudará você a instalar e configurar o Hadoop 3.1.2 Cluster de um nó único no Ubuntu 18.04, 16.04 Sistemas LTS e Linuxmint. Este artigo foi testado com o Ubuntu 18.04 LTS.
Etapa 1 - Pré -requisidades
Java é o principal requisito para executar o Hadoop em qualquer sistema, portanto, verifique se Java instalou em seu sistema usando o seguinte comando. Se você não tiver Java instalado no seu sistema, use um dos seguintes links para instalá -lo primeiro.
- Instale o Oracle Java 11 no Ubuntu 18.04 LTS (Bionic)
- Instale o Oracle Java 11 no Ubuntu 16.04 LTS (Xenial)
Etapa 2 - Crie usuário para Haddop
Recomendamos criar uma conta normal (nem raiz) para o Hadoop Working. Para criar uma conta usando o seguinte comando.
Adduser Hadoop
Depois de criar a conta, também é necessário configurar o SSH baseado em chaves para sua própria conta. Para fazer isso, use execute os seguintes comandos.
su -hadoop ssh -keygen -t rsa -p "-f ~//.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~///.ssh/autorizado_keys chmod 0600 ~//.ssh/autorizado_keys
Agora, ssh para localhost com o usuário do Hadoop. Isso não deve pedir a senha, mas a primeira vez que solicitará a adição de RSA à lista de hosts conhecidos.
Saída de localhost ssh
Etapa 3 - Download do Hadoop Source Archive
Nesta etapa, faça o download do Hadoop 3.1 arquivo de arquivo de origem usando o comando abaixo. Você também pode selecionar o espelho de download alternativo para aumentar a velocidade de download.
cd ~ wget http: // www-eu.apache.org/dist/hadoop/Common/hadoop-3.1.2/Hadoop-3.1.2.alcatrão.gz tar xzf hadoop-3.1.2.alcatrão.GZ MV Hadoop-3.1.2 Hadoop
Etapa 4 - Configure o modo pseudo -distribuído Hadoop
4.1. Configurar variáveis de ambiente Hadoop
Configure as variáveis de ambiente usadas pelo Hadoop. Editar ~/.Bashrc arquivo e anexar os seguintes valores no final do arquivo.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$ Hadoop_home/sbin: $ hadoop_home/bin
Em seguida, aplique as alterações no ambiente de corrida atual
fonte ~///.Bashrc
Agora edite $ Hadoop_home/etc/hadoop/hadoop-env.sh arquivo e definir Java_home variável de ambiente. Altere o caminho Java conforme a instalação em seu sistema. Este caminho pode variar de acordo com a versão do sistema operacional e a fonte de instalação. Portanto, verifique se você está usando o caminho correto.
vim $ hadoop_home/etc/hadoop/hadoop-env.sh
Atualizar abaixo a entrada:
exportar java_home =/usr/lib/jvm/java-11-oracle
4.2. Configure arquivos de configuração do Hadoop
O Hadoop possui muitos arquivos de configuração, que precisam configurar conforme os requisitos da sua infraestrutura Hadoop. Vamos começar com a configuração com a configuração básica do cluster de nós únicos hadoop. Primeiro, navegue para o local abaixo
CD $ hadoop_home/etc/hadoop
Edite o local do núcleo.xml
fs.padrão.nome hdfs: // localhost: 9000
Edite HDFS-Site.xml
dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode
Editar o MapRed-Site.xml
MapReduce.estrutura.Nome Yarn
Edite o local do fio.xml
fio.NodeManager.Aux-Services mapReduce_shuffle
4.3. Formato namenode
Agora formate o namenode usando o seguinte comando, verifique se o diretório de armazenamento está
HDFS Namenode -Format
Saída de amostra:
Aviso:/home/hadoop/hadoop/logs não existe. Criando. 2018-05-02 17: 52: 09.678 Informações Namenode.Namenode: startup_msg: /*********************************************** ***************.0.1.1 startup_msg: args = [-format] startup_msg: versão = 3.1.2… 2018-05-02 17: 52: 13.717 Info Common.Armazenamento: Diretório de Armazenamento/Home/Hadoop/Hadoopdata/HDFS/Namenode foi formatado com sucesso. 2018-05-02 17: 52: 13.806 Informações Namenode.FSImageFormatProtoBuf: Salvando o arquivo de imagem/home/hadoop/hadoopdata/hdfs/namenode/current/fsImage.CKPT_0000000000000000000 Usando sem compactação 2018-05-02 17: 52: 14.161 Informações Namenode.FSImageFormatProtoBuf: File/Home/Hadoop/Hadoopdata/HDFS/Namenode/Current/FSImage.ckpt_0000000000000000000 do tamanho 391 bytes salvos em 0 segundos . 2018-05-02 17: 52: 14.224 Informações Namenode.NnstorageretentionManager: vai reter 1 imagens com txid> = 0 2018-05-02 17: 52: 14.282 Informações Namenode.Namenode: Shutdown_msg: /*********************************************** *************** Shutdown_msg: Desligando o Namenode em Tecadmin/127.0.1.1 *************************************************** ***********/
Etapa 5 - Iniciar o Hadoop Cluster
Vamos começar seu cluster Hadoop usando os scripts fornecem pelo Hadoop. Basta navegar para o seu diretório $ hadoop_home/sbin e executar scripts um por um.
CD $ hadoop_home/sbin/
Agora execute start-dfs.sh roteiro.
./start-dfs.sh
Então execute Start-yarn.sh roteiro.
./Start-yarn.sh
Etapa 6 - Acesse serviços Hadoop em navegador
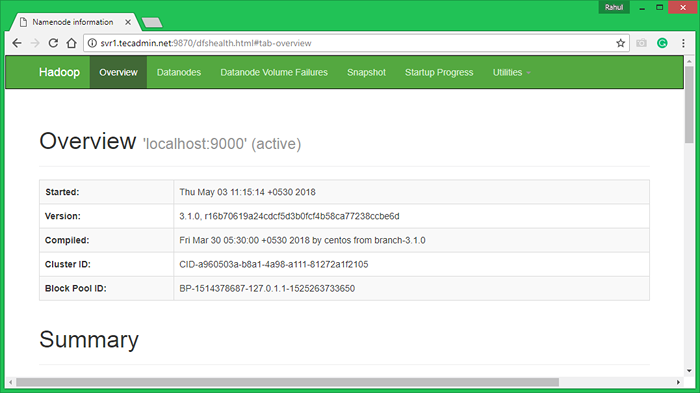
Hadoop Namenode começou na porta padrão 9870. Acesse seu servidor na porta 9870 em seu navegador favorito.
http: // svr1.Tecadmin.rede: 9870/
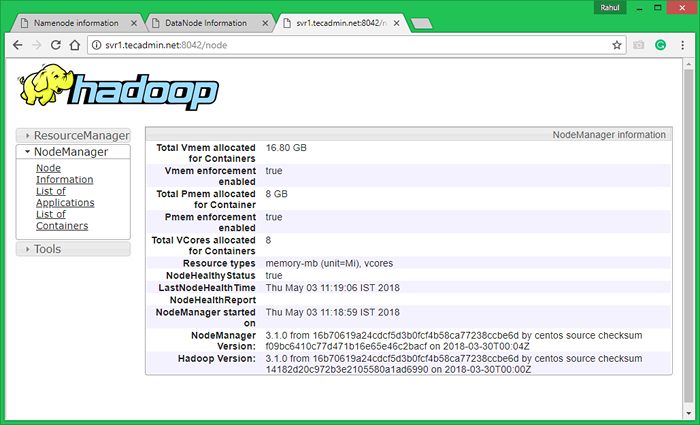
Agora acesse a porta 8042 para obter as informações sobre o cluster e todos os aplicativos
http: // svr1.Tecadmin.rede: 8042/
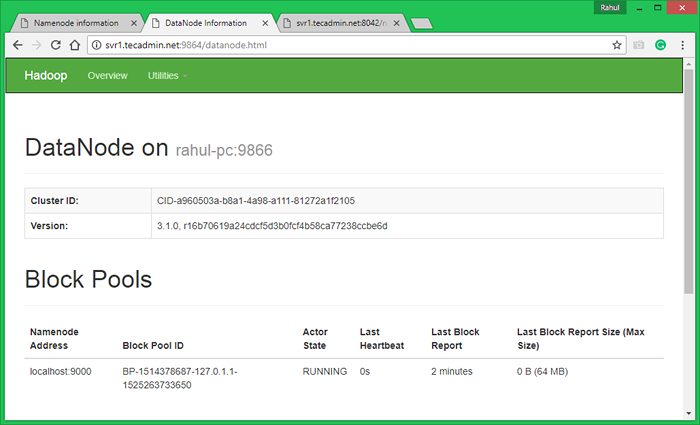
Porta de acesso 9864 para obter detalhes sobre o seu nó Hadoop.
http: // svr1.Tecadmin.rede: 9864/
Etapa 7 - Teste a configuração do nó único Hadoop
7.1. Faça os diretórios HDFS necessários usando os seguintes comandos.
bin/hdfs dfs -mkdir/usuário bin/hdfs dfs -mkdir/user/hadoop
7.2. Copie todos os arquivos do sistema de arquivos locais/var/log/httpd para o sistema de arquivos distribuído Hadoop usando o comando abaixo
BIN/HDFS DFS -PUT/VAR/LOG/APACHE2 LOGS
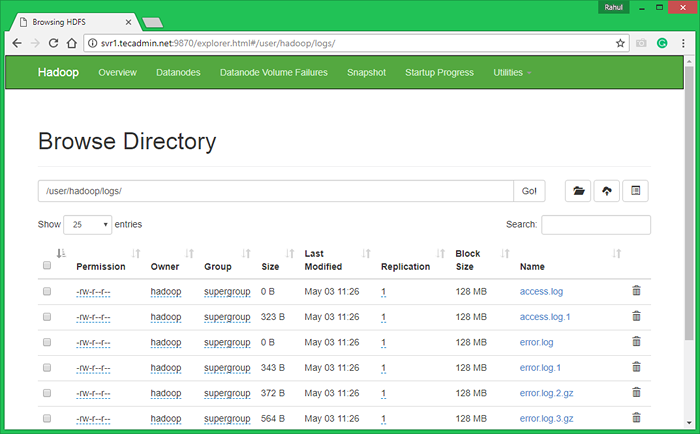
7.3. Procure o sistema de arquivos distribuído Hadoop, abrindo abaixo do URL no navegador. Você verá uma pasta Apache2 na lista. Clique no nome da pasta para abrir e você encontrará todos os arquivos de log lá.
http: // svr1.Tecadmin.NET: 9870/Explorer.html#/user/hadoop/logs/
7.4 - Agora copie o diretório de logs para o sistema de arquivos distribuído Hadoop para o sistema de arquivos local.
bin/hdfs dfs -get logs/tmp/logs ls -l/tmp/logs/
Você também pode verificar este tutorial para executar o WordCount MapReduce Job Exemplo usando a linha de comando.
- « Como detectar o ambiente da área de trabalho na linha de comando Linux
- Como baixar e fazer upload de arquivos com comando sftp »