

Como instalar o Spark no RHEL 8
- 5057
- 1473
- Mr. Mitchell Hansen
Apache Spark é um sistema de computação distribuído. Consiste em um mestre e um ou mais escravos, onde o mestre distribui o trabalho entre os escravos, dando a capacidade de usar nossos muitos computadores para trabalhar em uma tarefa. Pode -se adivinhar que essa é realmente uma ferramenta poderosa, onde as tarefas precisam de cálculos grandes para serem concluídos, mas podem ser divididos em pedaços menores de etapas que podem ser empurradas para os escravos para trabalhar. Depois que nosso cluster está em funcionamento, podemos escrever programas para executá -lo em Python, Java e Scala.
Neste tutorial, trabalharemos em uma única máquina que executa o Red Hat Enterprise Linux 8 e instalaremos o Spark Master e o Slave na mesma máquina, mas lembre -se de que as etapas que descrevem a configuração do escravo podem ser aplicadas a qualquer número de computadores, criando assim um cluster real que pode processar cargas de trabalho pesadas. Também adicionaremos os arquivos da unidade necessários para gerenciamento e executaremos um exemplo simples contra o cluster enviado com o pacote distribuído para garantir que nosso sistema esteja operacional.
Neste tutorial, você aprenderá:
- Como instalar o Spark Master e Slave
- Como adicionar arquivos da unidade Systemd
- Como verificar a conexão bem-sucedida do escravo mestre
- Como executar um exemplo de trabalho simples no cluster
Spark concha com pyspark. Requisitos de software e convenções usadas
| Categoria | Requisitos, convenções ou versão de software usada |
|---|---|
| Sistema | Red Hat Enterprise Linux 8 |
| Programas | Apache Spark 2.4.0 |
| Outro | Acesso privilegiado ao seu sistema Linux como raiz ou através do sudo comando. |
| Convenções | # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de sudo comando$ - Requer que os comandos do Linux sejam executados como um usuário não privilegiado regular |
Como instalar o Spark no redhat 8 instruções passo a passo
O Apache Spark é executado na JVM (Java Virtual Machine), portanto, é necessária uma instalação Java 8 que os aplicativos executam. Além disso, há várias conchas enviadas dentro do pacote, uma delas é Pyspark, Uma concha à base de Python. Para trabalhar com isso, você também precisará de Python 2 instalado e configurado.
- Para obter o URL do pacote mais recente de Spark, precisamos visitar o site do Spark Downloads. Precisamos escolher o espelho mais próximo ao nosso local e copiar o URL fornecido pelo site de download. Isso também significa que seu URL pode ser diferente do exemplo abaixo. Vamos instalar o pacote em
/optar/, Então entramos no diretório comoraiz:# CD /OPT
E alimentar o URL adquirido para
wgetPara obter o pacote:# wget https: // www-eu.apache.org/dist/spark/spark-2.4.0/Spark-2.4.0-bin-hadoop2.7.TGZ
- Vamos descompactar o tarball:
# tar -xvf Spark -2.4.0-bin-hadoop2.7.TGZ
- E crie um symblink para facilitar a lembrança de nossos caminhos nas próximas etapas:
# ln -s /opt /spark -2.4.0-bin-hadoop2.7 /Opt /Spark
- Criamos um usuário não privilegiado que executará os aplicativos, mestre e escravo:
# userAdd Spark
E defina -o como proprietário do todo
/Opt/Sparkdiretório, recursivamente:# CHOWN -R Spark: Spark /Opt /Spark*
- Nós criamos um
Systemdarquivo de unidade/etc/Systemd/System/Spark-mestre.serviçoPara o serviço mestre com o seguinte conteúdo:
cópia de[Unidade] Descrição = Apache Spark Master After = Network.Target [Service] Type = Freking User = Spark Group = Spark ExecStart =/Opt/Spark/Sbin/Start-Master.sh execstop =/opt/spark/sbin/stop-mestre.sh [install] wantedby = multiususer.alvoE também um para o serviço de escravos que será
/etc/Systemd/System/Spark-Slave.serviço.serviçoCom o conteúdo abaixo:
cópia de[Unidade] Descrição = Apache Spark Slave After = Network.Target [Service] Type = Freking User = Spark Group = Spark ExecStart =/Opt/Spark/Sbin/Start-Slave.sha faísca: // rhel8lab.LinuxConfig.org: 7077 execstop =/opt/spark/sbin/stop-slave.sh [install] wantedby = multiususer.alvoObserve o URL de faísca destacado. Isso é construído com
Spark: //: 7077, Nesse caso, a máquina de laboratório que executará o mestre tem o nome do hostRHEL8LAB.LinuxConfig.org. O nome do seu mestre será diferente. Todos os escravos devem ser capazes de resolver este nome de host e alcançar o mestre na porta especificada, que é porto7077por padrão. - Com os arquivos de serviço em vigor, precisamos perguntar
Systemdpara reler:# Systemctl Daemon-Reload
- Podemos começar nosso mestre de faísca com
Systemd:# SystemCtl Start Spark-mestre.serviço
- Para verificar nosso mestre está em execução e funcional, podemos usar o status Systemd:
# status systemctl spark-mestre.Spark-mestre de serviço.Serviço - Apache Spark Master carregado: carregado (/etc/Systemd/System/Spark -mestre.serviço; desabilitado; Preset do fornecedor: desativado) ativo: ativo (em execução) desde a sexta-feira 2019-01-11 16:30:03 CET; 53min Processo atrás: 3308 Execstop =/opt/spark/sbin/stop-mestre.SH (Code = Exitido, Status = 0/Sucesso) Processo: 3339 ExecStart =/Opt/Spark/Sbin/Start-Master.SH (Código = Exitido, Status = 0/Sucesso) PID principal: 3359 (Java) Tarefas: 27 (Limite: 12544) Memória: 219.3M CGROUP: /Sistema.fatia/mestre de faísca.Serviço 3359/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org.apache.fagulha.implantar.mestre.Mestre -Host […] 11 de janeiro 16:30:00 RHEL8LAB.LinuxConfig.Org Systemd [1]: Iniciando Apache Spark Master… 11 de janeiro 16:30:00 RHEL8LAB.LinuxConfig.Org Start-mestre.SH [3339]: Org de partida.apache.fagulha.implantar.mestre.Mestre, registrando para/opt/spark/logs/spark-spark-org.apache.fagulha.implantar.mestre.Master-1 […]
A última linha também indica o principal arquivo de log do mestre, que está no
Históricodiretório sob o diretório base do Spark,/Opt/Sparkno nosso caso. Ao analisar este arquivo, devemos ver uma linha no final semelhante ao exemplo abaixo:2019-01-11 14:45:28 Informações Mestre: 54-Fui eleito líder! Novo estado: vivo
Também devemos encontrar uma linha que nos diga onde a interface principal está ouvindo:
2019-01-11 16:30:03 Informações Utils: 54-Começou com sucesso o serviço 'MasterUi' na porta 8080
Se apontarmos um navegador para a porta da máquina host
8080, Devemos ver a página de status do mestre, sem trabalhadores anexados no momento.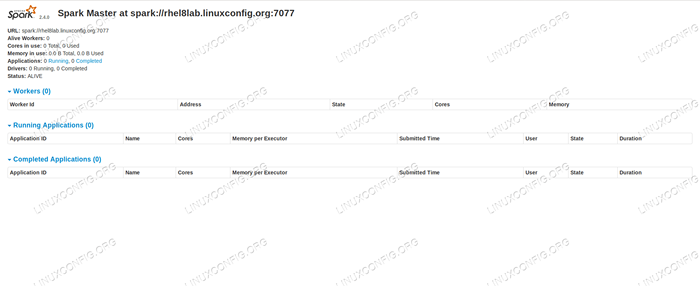 Página de status mestre de faísca sem trabalhadores em anexo.
Página de status mestre de faísca sem trabalhadores em anexo. Observe a linha URL na página de status do Spark Master. Este é o mesmo URL que precisamos usar para o arquivo de unidade de todos os escravos em que criamos
Etapa 5.
Se recebermos uma mensagem de erro de "conexão recusada" no navegador, provavelmente precisamos abrir a porta no firewall:# firewall-cmd-zone = public --add-port = 8080/tcp-sucesso de sucesso # firewall-cmd-sucesso
- Nosso mestre está correndo, vamos anexar um escravo a ele. Começamos o serviço de escravos:
# SystemCtl Start Spark-Slave.serviço
- Podemos verificar se nosso escravo está funcionando com o Systemd:
# status Systemctl Spark-Slave.serviço de faísca de serviço.Serviço - Apache Spark Slave carregado: Carregado (/etc/Systemd/System/Spark -Slave.serviço; desabilitado; Preset do fornecedor: desativado) Ativo: ativo (em execução) desde a sexta-feira 2019-01-11 16:31:41 CET; 1h 3min Process: 3515 Execstop =/Opt/Spark/Sbin/Stop-Slave.SH (Code = EXITED, STATUS = 0/SUCCESSO) Processo: 3537 ExecStart =/Opt/Spark/Sbin/Start-Slave.sha faísca: // rhel8lab.LinuxConfig.Org: 7077 (Código = EXITADO, STATUS = 0/SUCCESSO) PID PRINCIPAL: 3554 (Java) Tarefas: 26 (Limite: 12544) Memória: 176.1M CGROUP: /Sistema.Fatia/Spark-Slave.Serviço 3554/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org.apache.fagulha.implantar.trabalhador.Trabalhador […] 11 de janeiro 16:31:39 RHEL8LAB.LinuxConfig.Org Systemd [1]: Iniciando Apache Spark Slave… 11 de janeiro 16:31:39 RHEL8LAB.LinuxConfig.Org Start-Slave.SH [3537]: Org de partida.apache.fagulha.implantar.trabalhador.Trabalhador, registrando para/opt/spark/logs/spark-spar […]
Esta saída também fornece o caminho para o arquivo de log do escravo (ou trabalhador), que estará no mesmo diretório, com "trabalhador" em seu nome. Ao verificar esse arquivo, devemos ver algo semelhante à saída abaixo:
2019-01-11 14:52:23 Informações Trabalhador: 54-Conectando-se ao Master Rhel8Lab.LinuxConfig.Org: 7077… 2019-01-11 14:52:23 Info Contexthandler: 781-Iniciado o.s.j.s.ServletContexthandler@62059f4a /metrics/json, null, disponível,@spark 2019-01-11 14:52:23 Info TransportClientFactory: 267-criou com sucesso a conexão com RHEL8LAB.LinuxConfig.org/10.0.2.15: 7077 Após 58 ms (0 ms gastos em bootstraps) 2019-01-11 14:52:24 Informações Trabalhador: 54-Registrado com sucesso com mestre Spark: // rhel8lab.LinuxConfig.Org: 7077
Isso indica que o trabalhador está conectado com sucesso ao mestre. Neste mesmo arquivo de log, encontraremos uma linha que nos diga o URL em que o trabalhador está ouvindo:
01/01/2019.0.0.0, e começou em http: // rhel8lab.LinuxConfig.Org: 8081
Podemos apontar nosso navegador para a página de status do trabalhador, onde o mestre está listado.
 Página de status do trabalhador Spark, conectado ao mestre.
Página de status do trabalhador Spark, conectado ao mestre.
No arquivo de log do mestre, uma linha de verificação deve aparecer:
2019-01-11 14:52:24 Informações Mestre: 54-Trabalhador de registro 10.0.2.15: 40815 com 2 núcleos, 1024.0 MB RAM
Se recarregarmos a página de status do mestre agora, o trabalhador também deve aparecer lá, com um link para sua página de status.
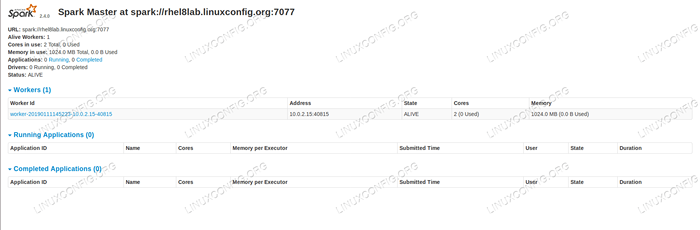 Página de status mestre de faísca com um trabalhador anexado.
Página de status mestre de faísca com um trabalhador anexado. Essas fontes verificam que nosso cluster está anexado e pronto para trabalhar.
- Para executar uma tarefa simples no cluster, executamos um dos exemplos enviados com o pacote que baixamos. Considere o seguinte arquivo de texto simples
/opt/spark/teste.arquivo:
cópia delinha1 word1 word2 word3 linha2 word1 line3 word1 word2 word3 word4Vamos executar o
WordCount.pyexemplo disso que contará a ocorrência de cada palavra no arquivo. Podemos usar ofagulhaUsuário, nãoraizprivilégios necessários.$/opt/spark/bin/spark-submit/opt/spark/exemplos/src/main/python/wordcount.py/opt/spark/teste.Arquivo 2019-01-11 15:56:57 Informações SparkContext: 54-Pedido enviado: PythonwordCount 2019-01-11 15:56:57 Info SecurityManager: 54-Alterando o View ACLs para: Spark 2019-01-11 15:56: 57 Info SecurityManager: 54 - Alterando Modificar ACLs para: Spark […]
À medida que a tarefa é executada, uma saída longa é fornecida. Perto do final da saída, o resultado é mostrado, o cluster calcula as informações necessárias:
2019-01-11 15:57:05 Informações Dagscheduler: 54-Trabalho 0 Concluído: Colete em/opt/spark/exemplos/src/main/python/wordcount.Py: 40, levou 1.619928 s Linha3: 1 Linha2: 1 Linha 1: 1 Word4: 1 Word1: 3 Word3: 2 Word2: 2 […]
Com isso, vimos nossa faísca do Apache em ação. Nós de escravos adicionais podem ser instalados e anexados para escalar o poder de computação de nosso cluster.
Tutoriais do Linux relacionados:
- Como criar um cluster Kubernetes
- Oracle Java Instalação no Ubuntu 20.04 fossa focal linux
- Coisas para instalar no Ubuntu 20.04
- Como instalar Java no Manjaro Linux
- Linux: Instale Java
- Como instalar Kubernetes no Ubuntu 20.04 fossa focal linux
- Como instalar Kubernetes no Ubuntu 22.04 Jellyfish…
- Ubuntu 20.04 Hadoop
- Uma introdução à automação, ferramentas e técnicas do Linux
- Ubuntu 20.04 WordPress com instalação do Apache