

Como instalar o hadoop single node cluster (pseudonode) no CentOS 7

- 2228
- 693
- Loren Botsford
Hadoop é uma estrutura de código aberto que é amplamente usado para lidar com Bigdata. A maioria dos BigData/Analytics de dados Os projetos estão sendo construídos em cima do Hadoop Eco-System. Consiste em duas camadas, uma é para Armazenando dados e outro é para Processando dados.
Armazenar será resolvido por seu próprio sistema de arquivos chamado HDFS (Hadoop distribuiu o sistema de arquivos) e Em processamento será resolvido por FIO (Ainda outro negociador de recursos). MapReduce é o mecanismo de processamento padrão do Hadoop Eco-System.
Este artigo descreve o processo para instalar o Pseudonode instalação de Hadoop, onde todos os Daemons (JVMS) estará correndo Nó único Cluster ligado CENTOS 7.
Isso é principalmente para iniciantes para aprender Hadoop. Em tempo real, Hadoop será instalado como um cluster multinodo, onde os dados serão distribuídos entre os servidores como blocos e o trabalho será executado de maneira paralela.
Pré -requisitos
- Uma instalação mínima do servidor CentOS 7.
- Java v1.8 liberação.
- Hadoop 2.x liberação estável.
Nesta página
- Como instalar Java no CentOS 7
- Configure o login sem senha no CentOS 7
- Como instalar o Hadoop Single Node no CentOS 7
- Como configurar o Hadoop no CentOS 7
- Formatando o sistema de arquivos HDFS através do Namenode
Instalando Java no CentOS 7
1. Hadoop é um ecossistema que é composto por Java. Nós precisamos Java instalado em nosso sistema obrigatoriamente para instalar Hadoop.
# yum install java-1.8.0-openjdk
2. Em seguida, verifique a versão instalada de Java no sistema.
# java -version
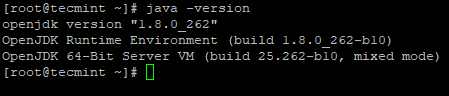 verifique a versão do Java
verifique a versão do Java Configure o login sem senha no CentOS 7
Precisamos ter o SSH configurado em nossa máquina, Hadoop gerenciará nós com o uso de Ssh. Nó mestre usa Ssh conexão para conectar seus nós de escravos e executar operação como iniciar e parar.
Precisamos configurar ssh sem senha para que o mestre possa se comunicar com os escravos usando ssh sem uma senha. Caso contrário, para cada estabelecimento de conexão, precisa inserir a senha.
Neste nó único, Mestre Serviços (Namenode, Namenode secundário & Gerente de Recursos) e Escravo Serviços (DataNode & NodeManager) estará funcionando como separado JVMS. Mesmo sendo o nó Singe, precisamos ter ssh sem senha para fazer Mestre comunicar Escravo sem autenticação.
3. Configure um login SSH sem senha usando os seguintes comandos no servidor.
# ssh-keygen # ssh-copy-id -i localhost
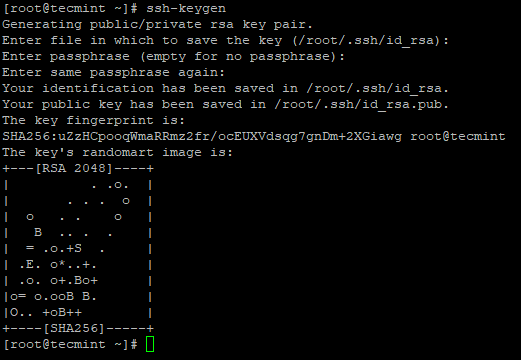 Crie SSH Keygen no CentOS 7
Crie SSH Keygen no CentOS 7 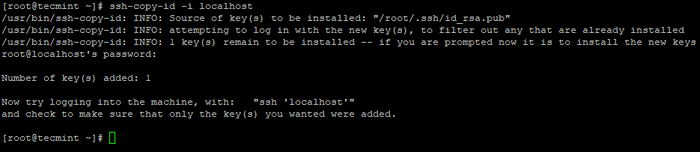 Copie a chave SSH para o CentOS 7
Copie a chave SSH para o CentOS 7 4. Depois de configurar o login SSH sem senha, tente fazer o login novamente, você estará conectado sem uma senha.
# ssh localhost
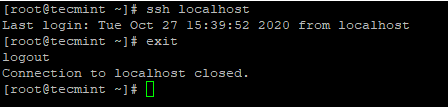 SSH LOGINLENTES DE SENHANDA PARA CENTOS 7
SSH LOGINLENTES DE SENHANDA PARA CENTOS 7 Instalando o Hadoop no CentOS 7
5. Vá para o site Apache Hadoop e faça o download do lançamento estável do Hadoop usando o seguinte comando wget.
# wget https: // arquivo.apache.org/dist/hadoop/core/hadoop-2.10.1/Hadoop-2.10.1.alcatrão.gz # tar xvpzf hadoop-2.10.1.alcatrão.gz
6. Em seguida, adicione o Hadoop Variáveis de ambiente em ~/.Bashrc arquivo como mostrado.
Hadoop_prefix =/root/hadoop-2.10.1 caminho = $ PATH: $ HADOOP_PREFIX/BIN PATH JAVA_HOME HADOOP_PREFIX
7. Depois de adicionar variáveis de ambiente a ~/.Bashrc O arquivo, obtenha o arquivo e verifique o Hadoop executando os seguintes comandos.
# fonte ~///.BASHRC # CD $ HADOOP_PREFIX # BIN/HADOOP Versão
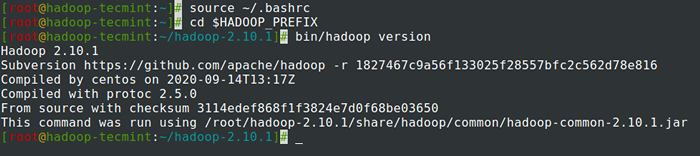 Verifique a versão Hadoop no CentOS 7
Verifique a versão Hadoop no CentOS 7 Configurando o Hadoop no CentOS 7
Precisamos configurar abaixo os arquivos de configuração do Hadoop para caber em sua máquina. Em Hadoop, Cada serviço tem seu próprio número de porta e seu próprio diretório para armazenar os dados.
- Arquivos de configuração do Hadoop - Core -Site.XML, Site HDFS.XML, MapRed-Site.XML & YARN-SITE.xml
8. Primeiro, precisamos atualizar Java_home e Hadoop caminho no Hadoop-env.sh arquivo como mostrado.
# CD $ hadoop_prefix/etc/hadoop # vi hadoop-env.sh
Digite a seguinte linha no início do arquivo.
exportar java_home =/usr/lib/jvm/java-1.8.0/jre export hadoop_prefix =/root/hadoop-2.10.1
9. Em seguida, modifique o Site do núcleo.xml arquivo.
# CD $ hadoop_prefix/etc/hadoop # VI Site Core.xml
Cole a seguir entre tags como mostrado.
fs.Defaultfs hdfs: // localhost: 9000
10. Crie os diretórios abaixo em Tecmint diretório inicial do usuário, que será usado para Nn e Dn armazenar.
# mkdir -p/home/tecmint/hdata/ # mkdir -p/home/tecmint/hdata/data # mkdir -p/home/tecmint/hdata/nome
10. Em seguida, modifique o Site HDFS.xml arquivo.
# CD $ Hadoop_prefix/etc/Hadoop # VI HDFS-SITE.xml
Cole a seguir entre tags como mostrado.
dfs.Replicação 1 DFS.Namenode.nome.Dir/Home/Tecmint/Hdata/Nome DFS .DataNode.dados.Dir Home/Tecmint/Hdata/Dados
11. Novamente, modifique o MapRed-site.xml arquivo.
# CD $ Hadoop_prefix/etc/hadoop # CP MAPRED-SITE.xml.Modelo MAPRED-SITE.XML # VI MapRed-Site.xml
Cole a seguir entre tags como mostrado.
MapReduce.estrutura.Nome Yarn
12. Por fim, modifique o Site de fio.xml arquivo.
# CD $ Hadoop_prefix/etc/hadoop # VI Yarn-site.xml
Cole a seguir entre tags como mostrado.
fio.NodeManager.Aux-Services mapReduce_shuffle
Formatando o sistema de arquivos HDFS através do Namenode
13. Antes de iniciar o Conjunto, Precisamos formatar o Hadoop nn em nosso sistema local onde foi instalado. Geralmente, isso será feito no estágio inicial antes de iniciar o cluster pela primeira vez.
Formatando o Nn causará perda de dados no NN Metastore, por isso temos que ser mais cautelosos, não devemos formatar Nn Enquanto o cluster está em execução, a menos que seja necessário intencionalmente.
# CD $ Hadoop_prefix # bin/hadoop namenode -format
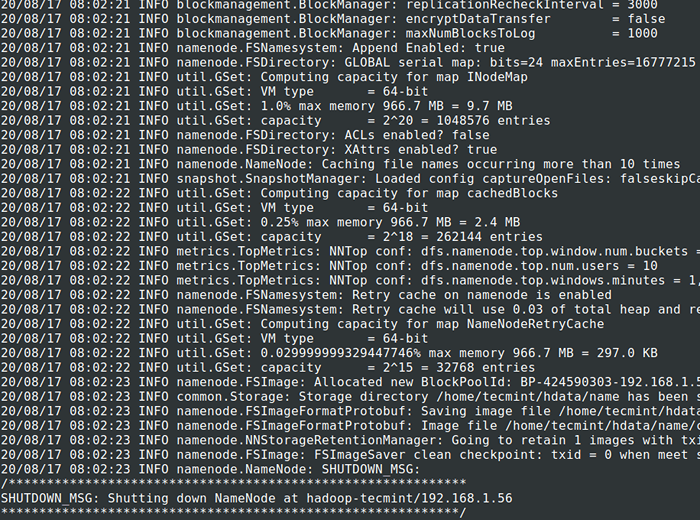 Formato HDFS FileSystem
Formato HDFS FileSystem 14. Começar Namenode Daemon e DataNode Daemon: (porta 50070).
# CD $ HADOOP_PREFIX # SBIN/START-DFS.sh
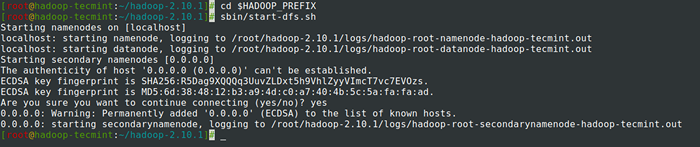 Inicie o Namenode e DataNode Daemon
Inicie o Namenode e DataNode Daemon 15. Começar Gerente de Recursos Daemon e NodeManager Daemon: (porta 8088).
# sbin/start-yarn.sh
 Iniciar o ResourceManager e o Nodemanager Daemon
Iniciar o ResourceManager e o Nodemanager Daemon 16. Para parar todos os serviços.
# sbin/stop-dfs.sh # sbin/stop-dfs.sh
Resumo
Resumo
Neste artigo, passamos pelo processo passo a passo para configurar Pseudonode Hadoop (Nó único) Conjunto. Se você tiver conhecimento básico do Linux e seguir estas etapas, o cluster estará em 40 minutos.
Isso pode ser muito útil para o iniciante começar a aprender e praticar Hadoop ou esta versão de baunilha de Hadoop pode ser usado para fins de desenvolvimento. Se queremos ter um cluster em tempo real, precisamos de pelo menos três servidores físicos em mãos ou ter que provisionar a nuvem para ter vários servidores.
- « Configurando pré -requisitos do Hadoop e endurecimento de segurança - Parte 2
- O que é MongoDB? Como funciona o MongoDB? »