

Como instalar o Hadoop no RHEL 8 / CENTOS 8 Linux
- 2656
- 6
- Randal Kuhlman
Apache Hadoop é uma estrutura de código aberto usado para armazenamento distribuído, bem como processamento distribuído de big data em grupos de computadores que são executados em commodity hardwares. O Hadoop armazena dados no Hadoop Distributed File System (HDFS) e o processamento desses dados é feito usando o MapReduce. O YARN fornece API para solicitar e alocar recursos no cluster Hadoop.
A estrutura do Apache Hadoop é composta pelos seguintes módulos:
- Hadoop comum
- Sistema de arquivos distribuído Hadoop (HDFS)
- FIO
- MapReduce
Este artigo explica como instalar o Hadoop versão 2 no Rhel 8 ou no CentOS 8. Instalaremos o HDFS (Namenode e DataNode), Yarn, MapReduce no cluster de um nó único no modo pseudo distribuído, que é distribuído simulação em uma única máquina. Cada daemon Hadoop, como HDFs, fios, MapReduce etc. será executado como um processo Java separado/individual.
Neste tutorial, você aprenderá:
- Como adicionar usuários para o ambiente Hadoop
- Como instalar e configurar o Oracle JDK
- Como configurar ssh sem senha
- Como instalar o Hadoop e configurar os arquivos XML relacionados necessários
- Como começar o cluster Hadoop
- Como acessar o Namenode e o ResourceManager Web UI
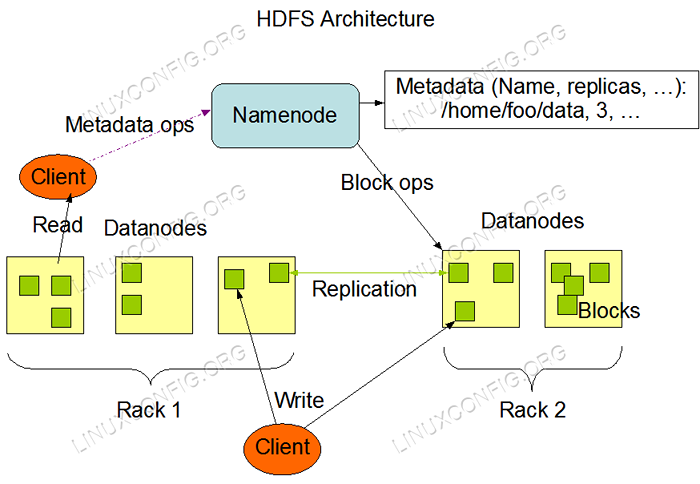
Arquitetura HDFS. Requisitos de software e convenções usadas
| Categoria | Requisitos, convenções ou versão de software usada |
|---|---|
| Sistema | RHEL 8 / CENTOS 8 |
| Programas | Hadoop 2.8.5, Oracle JDK 1.8 |
| Outro | Acesso privilegiado ao seu sistema Linux como raiz ou através do sudo comando. |
| Convenções | # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de sudo comando$ - Requer que os comandos do Linux sejam executados como um usuário não privilegiado regular |
Adicione usuários para o Hadoop Environment
Crie o novo usuário e grupo usando o comando:
# userAdd hadoop # passwd hadoop
[root@hadoop ~]# userAdd hadoop [root@hadoop ~]# passwd hadoop alterando senha para o usuário hadoop. Nova senha: reddeme a nova senha: Passwd: todos os tokens de autenticação atualizados com sucesso. [root@hadoop ~]# cat /etc /passwd | Grep Hadoop Hadoop: X: 1000: 1000 ::/Home/Hadoop:/bin/Bash
Instale e configure o Oracle JDK
Baixe e instale o JDK-8U202-Linux-X64.Pacote oficial de RPM para instalar o Oracle JDK.
[root@hadoop ~]# rpm -ivh jdk-8u202-linux-x64.Aviso de RPM: JDK-8U202-Linux-X64.RPM: Cabeçalho V3 RSA/SHA256 Assinatura, ID da chave EC551F03: Não verificando… ###################################### 100%] Preparando… ################################## [100%] atualização / instalação… 1: jdk1.8-2000: 1.8.0_202-FCS ################################## [100%] Descongelando arquivos JAR… Ferramentas.jarra… plugin.Jar ... Javaws.jar ... implante.Jar… rt.jarra ... JSSE.jarra ... charsets.jar ... localedata.jarra ..
Após a instalação para verificar se o Java foi configurado com sucesso, execute os seguintes comandos:
[root@hadoop ~]# java -version java versão "1.8.0_202 "Java (TM) SE Ambiente de tempo de execução (Build 1.8.0_202-B08) Java Hotspot (TM) de 64 bits VM (Build 25.202-B08, modo misto) [root@hadoop ~]# update-alternatives-Config java Há 1 programa que fornece 'java'. Comando de seleção ----------------------------------------------- * + 1/usr/java/jdk1.8.0_202-AMD64/JRE/BIN/Java
Configure ssh sem senha
Instale o servidor SSH aberto e o Open SSH Client ou, se já instalado, ele listará os pacotes abaixo.
[root@hadoop ~]# rpm -qa | Grep OpenSsh* OpenSsh-Server-7.8p1-3.EL8.x86_64 OpenSSL-LIBS-1.1.1-6.EL8.x86_64 OpenSSL-1.1.1-6.EL8.x86_64 OpenSsh-clients-7.8p1-3.EL8.x86_64 OpenSsh-7.8p1-3.EL8.x86_64 OpenSSL-PKCS11-0.4.8-2.EL8.x86_64
Gerar pares de chave pública e privada com o seguinte comando. O terminal solicitará a entrada do nome do arquivo. Imprensa DIGITAR e prossiga. Depois disso, copie o formulário das chaves públicas id_rsa.bar para Autorizado_keys.
$ ssh -keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~///.ssh/autorizado_keys $ chmod 640 ~/.ssh/autorizado_keys
[hadoop@hadoop ~] $ ssh -keygen -t rsa gerando par public/privado RSA par. Digite o arquivo para salvar a chave (/home/hadoop/.ssh/id_rsa): diretório criado '/home/hadoop/.ssh '. Digite a senha (vazia sem senha): Digite a mesma senha novamente: Sua identificação foi salva em/home/hadoop/.ssh/id_rsa. Sua chave pública foi salva em/home/hadoop/.ssh/id_rsa.bar. A principal impressão digital é: sha256: h+llpkajjdd7b0f0je/nfjrp5/fuejswmmzpjfxoelg [email protected] de areia.com a imagem Randomart da chave é: +--- [RSA 2048] ---- +|… ++*o .O | | O… +.O.+o.+| | +… * +Oo == | | . o . E .oo | | . = .S.* o | | . o.O = O | |… O | | .o. | | o+. | + ---- [sha256] -----+ [hadoop@hadoop ~] $ cat ~//.ssh/id_rsa.pub >> ~///.ssh/autorizado_keys [hadoop@hadoop ~] $ chmod 640 ~//.ssh/autorizado_keys
Verifique a configuração SSH sem senha com o comando:
$ ssh
[hadoop@hadoop ~] $ ssh hadoop.caixa de areia.com console da web: https: // hadoop.caixa de areia.com: 9090/ou https: // 192.168.1.108: 9090/ Último login: Sáb 13 de abril 12:09:55 2019 [Hadoop@Hadoop ~] $
Instale o Hadoop e configure arquivos XML relacionados
Baixar e extrair o Hadoop 2.8.5 Do site oficial do Apache.
# wget https: // arquivo.apache.org/dist/hadoop/comum/hadoop-2.8.5/Hadoop-2.8.5.alcatrão.gz # tar -xzvf hadoop -2.8.5.alcatrão.gz
[root@rhel8-sandbox ~]# wget https: // arquivamento.apache.org/dist/hadoop/comum/hadoop-2.8.5/Hadoop-2.8.5.alcatrão.GZ --2019-04-13 11: 14: 03-- https: // arquivo.apache.org/dist/hadoop/comum/hadoop-2.8.5/Hadoop-2.8.5.alcatrão.GZ Resolvando Arquivo.apache.org (arquivo.apache.org)… 163.172.17.199 conectando ao arquivo.apache.org (arquivo.apache.org) | 163.172.17.199 |: 443… conectado. Solicitação HTTP enviada, Aguardando resposta… 200 OK Comprimento: 246543928 (235m) [Application/X-Gzip] Salvando para: 'Hadoop-2.8.5.alcatrão.gz 'Hadoop-2.8.5.alcatrão.gz 100%[================================================ =======================================>] 235.12m 1.47MB/S em 2m 53s 2019-04-13 11:16:57 (1.36 mb/s) - 'Hadoop -2.8.5.alcatrão.GZ 'salvo [246543928/246543928]
Configurando as variáveis de ambiente
Editar o Bashrc Para o usuário do Hadoop através da configuração das seguintes variáveis de ambiente Hadoop:
exportar hadoop_home =/home/hadoop/hadoop-2.8.5 exportar hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home exportar yarn_home = $ hadoop_home hadaop_common_lib_native_nativo exportar Hadoop_Opts = "-Djava.biblioteca.caminho = $ hadoop_home/lib/nativo " Fonte do .Bashrc Na sessão de login atual.
$ fonte ~//.Bashrc
Editar o Hadoop-env.sh arquivo que está em /etc/hadoop Dentro do diretório de instalação do Hadoop, faça as seguintes alterações e verifique se você deseja alterar outras configurações.
exportar java_home = $ java_home:-"/usr/java/jdk1.8.0_202-AMD64 " Exportar hadoop_conf_dir = $ hadoop_conf_dir:-"/home/hadoop/hadoop-2.8.5/etc/hadoop " Alterações de configuração no local do núcleo.Arquivo XML
Editar o Site do núcleo.xml com vim ou você pode usar qualquer um dos editores. O arquivo está sob /etc/hadoop dentro Hadoop diretório doméstico e adicione as seguintes entradas.
fs.Defaultfs hdfs: // hadoop.caixa de areia.com: 9000 Hadoop.TMP.dir /home/hadoop/hadooptmpdata Além disso, crie o diretório em Hadoop Pasta em casa.
$ mkdir hadooptmpdata
Alterações de configuração no site HDFS.Arquivo XML
Editar o Site HDFS.xml que está presente no mesmo local I.e /etc/hadoop dentro Hadoop diretório de instalação e criar o Namenode/datanode diretórios abaixo Hadoop diretório inicial do usuário.
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/datanode
dfs.replicação 1 dfs.nome.dir Arquivo: /// home/hadoop/hdfs/namenode dfs.dados.dir Arquivo: /// home/hadoop/hdfs/dataNode Alterações de configuração no MapRed-Site.Arquivo XML
Copie o MapRed-site.xml de MapRed-site.xml.modelo usando cp comando e depois edite o MapRed-site.xml colocado em /etc/hadoop sob Hadoop Diretório de instilação com as seguintes mudanças.
$ CP MapRed-Site.xml.Modelo MAPRED-SITE.xml
MapReduce.estrutura.nome fio Alterações de configuração no local do fio.Arquivo XML
Editar Site de fio.xml com as seguintes entradas.
MapReduceyarn.NodeManager.Aux-Services mapReduce_shuffle Iniciando o cluster Hadoop
Formate o Namenode antes de usá -lo pela primeira vez. Como o usuário do Hadoop execute o comando abaixo para formatar o namenode.
$ hdfs namenode -format
[hadoop@hadoop ~] $ hdfs namenode -format 19/04/13 11:54:10 Info Namenode.Namenode: startup_msg: /*********************************************** *************** Startup_MSG: Iniciando Namenode startup_msg: user = hadoop startup_msg: host = hadoop.caixa de areia.com/192.168.1.108 startup_msg: args = [-format] startup_msg: versão = 2.8.5 19/04/13 11:54:17 Info NameNode.FSNamesystem: dfs.Namenode.modo de segurança.limiar-PCT = 0.9990000128746033 19/04/13 11:54:17 Info NameNode.FSNamesystem: dfs.Namenode.modo de segurança.min.datanodes = 0 19/04/13 11:54:17 Info NameNode.FSNamesystem: dfs.Namenode.modo de segurança.Extensão = 30000 19/04/13 11:54:18 Métricas de informações.TopMetrics: nntop conf: dfs.Namenode.principal.janela.num.baldes = 10 19/04/13 11:54:18 Métricas de informações.TopMetrics: nntop conf: dfs.Namenode.principal.num.Usuários = 10 19/04/13 11:54:18 Métricas de informações.TopMetrics: nntop conf: dfs.Namenode.principal.janelas.Minutos = 1,5,25 19/04/13 11:54:18 Info NameNode.FSNamesystem: Representar o cache no Namenode está ativado em 19/04/13 11:54:18 Info Namenode.FSNamesystem: Résty Cache usará 0.03 do tempo total de expiração do cache do cache da pilha e do cache é 600000 milis 19/04/13 11:54:18 Informações Util.GSET: Capacidade de computação para mapa NameNodetryCache 19/04/13 11:54:18 Informações Util.GSET: VM Tipo = 64 bits 19/04/13 11:54:18 Informações Util.GSET: 0.0299999999329447746% Memória máxima 966.7 MB = 297.0 KB 19/04/13 11:54:18 Informações Util.GSET: Capacidade = 2^15 = 32768 entradas 19/04/13 11:54:18 Info NameNode.FSIMAGE: ALOCADO NOVO BlockPoolId: BP-415167234-192.168.1.108-1555142058167 19/04/13 11:54:18 Info Common.Armazenamento: Diretório de Armazenamento/Home/Hadoop/HDFS/Namenode foi formatado com sucesso. 19/04/13 11:54:18 Info Namenode.FsImageFormatProtoBuf: Salvar o arquivo de imagem/home/hadoop/hdfs/namenode/corrente/fsImage.CKPT_0000000000000000000 Usando sem compactação 19/04/13 11:54:18 Info Namenode.FsImageFormatProtoBuf: File/Home/Hadoop/HDFS/Namenode/Current/FSImage.ckpt_0000000000000000000 do tamanho 323 bytes salvos em 0 segundos. 19/04/13 11:54:18 Info Namenode.NnstorageretentionManager: vai reter 1 imagens com txid> = 0 19/04/13 11:54:18 Informações Util.Exitutil: Sair com o status 0 19/04/13 11:54:18 Info Namenode.Namenode: Shutdown_msg: /*********************************************** *************** Shutdown_msg: Desligando o Namenode no Hadoop.caixa de areia.com/192.168.1.108 ***************************************************** ***********/
Depois que o namenode for formatado, inicie os HDFs usando o start-dfs.sh roteiro.
$ start-dfs.sh
[hadoop@hadoop ~] $ start-dfs.sh iniciando namenodos no [hadoop.caixa de areia.com] Hadoop.caixa de areia.com: iniciando namenode, logando para/home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-namenode-hadoop.caixa de areia.com.fora Hadoop.caixa de areia.com: Iniciando DataNode, logando para/home/hadoop/hadoop-2.8.5/Logs/Hadoop-Hadoop-Datanode-Hadoop.caixa de areia.com.fora iniciando namenodos secundários [0.0.0.0] A autenticidade do host '0.0.0.0 (0.0.0.0) 'Não pode ser estabelecido. A impressão digital da ECDSA é sha256: e+nfcek/kvnignwdhgfvikhjbwwghiijjkfjygr7nki. Tem certeza que deseja continuar se conectando (sim/não)? sim 0.0.0.0: Aviso: Adicionado permanentemente '0.0.0.0 '(ECDSA) para a lista de hosts conhecidos. [email protected] de 0: 0.0.0.0: iniciando o secundário em.8.5/Logs/Hadoop-Hadoop-Secondarynamenode-Hadoop.caixa de areia.com.fora
Para iniciar os serviços de fio, você precisa executar o script de início do fio i.e. Start-yarn.sh
$ start-yarn.sh
[Hadoop@Hadoop ~] $ Start-Yarn.SH DIREITO DE FEIONOS DAIMONS DE CONSELHOS, LOGGEGEM PARA/HOME/HADOOP/HADOOP-2.8.5/logs/Yarn-Hadoop-ResourceManager-Hadoop.caixa de areia.com.fora Hadoop.caixa de areia.com: Iniciando Nodemanager, logando para/home/hadoop/hadoop-2.8.5/Logs/Yarn-Hadoop-Nodemanager-Hadoop.caixa de areia.com.fora
Para verificar todos os serviços/daemons do Hadoop são iniciados com sucesso, você pode usar o JPS comando.
$ JPS 2033 NAMENODE 2340 Secundário
Agora podemos verificar a versão atual do Hadoop que você pode usar abaixo do comando:
$ hadoop versão
ou
Versão $ hdfs
[Hadoop@Hadoop ~] $ Hadoop Versão Hadoop 2.8.5 Subversão https: // git-wip-us.apache.org/repos/asf/hadoop.Git -R 0B8464D75227FCEE2C6E7F2410377B3D53D3D5F8 Compilado por JDU em 2018-09-10T03: 32Z compilado com Protoc 2.5.0 da fonte com soma de verificação 9942CA5C745417C14E318835F420733 Este comando foi executado usando/home/hadoop/hadoop-2.8.5/share/hadoop/Common/hadoop-common-2.8.5.jar [hadoop@hadoop ~] $ hdfs versão Hadoop 2.8.5 Subversão https: // git-wip-us.apache.org/repos/asf/hadoop.Git -R 0B8464D75227FCEE2C6E7F2410377B3D53D3D5F8 Compilado por JDU em 2018-09-10T03: 32Z compilado com Protoc 2.5.0 da fonte com soma de verificação 9942CA5C745417C14E318835F420733 Este comando foi executado usando/home/hadoop/hadoop-2.8.5/share/hadoop/Common/hadoop-common-2.8.5.jar [hadoop@hadoop ~] $
Interface da linha de comando HDFS
Para acessar o HDFS e criar alguns diretórios em cima do DFS, você pode usar o HDFS CLI.
$ hdfs dfs -mkdir /testdata $ hdfs dfs -mkdir /hadoopdata $ hdfs dfs -ls /
[Hadoop@hadoop ~] $ hdfs dfs -ls / encontrou 2 itens drwxr-xr-x-hadoop supergrupo 0 2019-04-13 11:58 / hadoopdata drwxr-xr-x-hadoop supergrupo 0 2019-04-13 11: 59 /testData
Acesse o namenode e o fio do navegador
Você pode acessar a interface do usuário da web para o Namenode e o Yarn Resource Manager por meio de qualquer um dos navegadores como Google Chrome/Mozilla Firefox.
Namenode Web UI - http: //: 50070
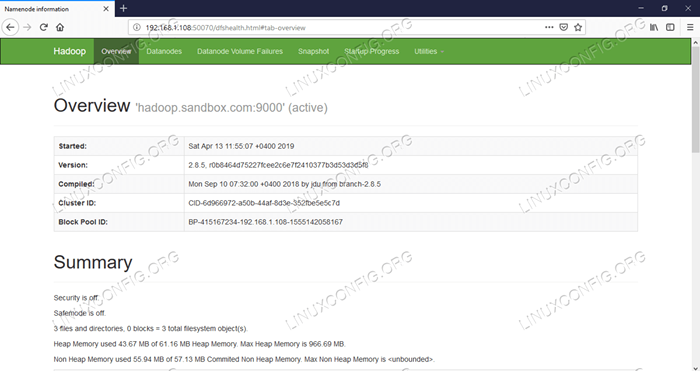 Interface do usuário da Web Namenode.
Interface do usuário da Web Namenode. 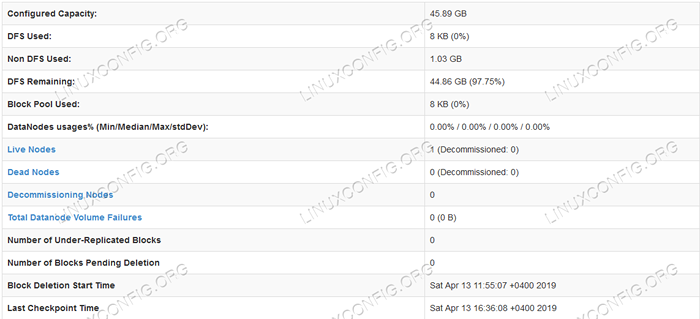 Informações detalhadas para HDFS.
Informações detalhadas para HDFS. 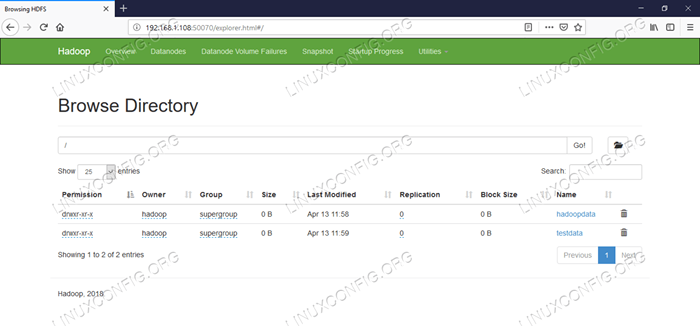 Navegação do diretório HDFS.
Navegação do diretório HDFS. A interface da web do Yarn Resource Manager (RM) exibirá todos os trabalhos em execução no cluster Hadoop atual.
UI da web do gerenciador de recursos - http: //: 8088
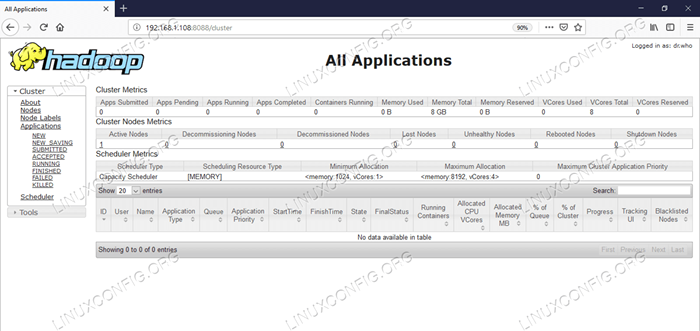 Interface do usuário da Web Gerenciador de recursos (YARN).
Interface do usuário da Web Gerenciador de recursos (YARN). Conclusão
O mundo está mudando a maneira como está operando atualmente e os dados grandes estão desempenhando um papel importante nesta fase. Hadoop é uma estrutura que facilita nossa vida enquanto trabalha em grandes conjuntos de dados. Existem melhorias em todas as frentes. O futuro é emocionante.
Tutoriais do Linux relacionados:
- Ubuntu 20.04 Hadoop
- Coisas para instalar no Ubuntu 20.04
- Como criar um cluster Kubernetes
- Como instalar Kubernetes no Ubuntu 20.04 fossa focal linux
- Como instalar Kubernetes no Ubuntu 22.04 Jellyfish…
- Coisas para fazer depois de instalar o Ubuntu 20.04 fossa focal linux
- Coisas para instalar no Ubuntu 22.04
- Como trabalhar com a API de Rest WooCommerce com Python
- Como gerenciar clusters de Kubernetes com Kubectl
- Uma introdução à automação, ferramentas e técnicas do Linux
- « Como instalar o WordPress.com aplicativo com desktop no Ubuntu 19.04 Disco Dingo Linux
- Como instalar Redmine no RHEL 8 / CENTOS 8 Linux »