

Como instalar e configurar o Hive com alta disponibilidade - Parte 7

- 4237
- 145
- Mrs. Christopher Okuneva
Hive é um Armazém de dados modelo em Hadoop Eco-sistema. Pode ser executado como uma ferramenta ETL em cima de Hadoop. Permitir alta disponibilidade (HA) no Hive não é semelhante ao que fazemos em serviços mestres como Namenode e Recursion Manager.
O failover automático não acontecerá em Hive (HiveServer2). Caso existam HiveServer2 (HS2) falha, executando empregos naquele falhou HS2 vai falhar. Precisamos reenviar o trabalho para que o trabalho possa funcionar em outros HiveServer2. Então, habilitando Ha sobre HS2 nada além de, aumentar o número de HS2 componentes em Conjunto.
Neste artigo, veremos as etapas para instalar e ativar o Alta disponibilidade de Hive.
Requisitos
- Melhores práticas para implantar o Hadoop Server no CentOS/Rhel 7 - Parte 1
- Configurando pré -requisitos do Hadoop e endurecimento de segurança - Parte 2
- Como instalar e configurar o gerente de Cloudera no CentOS/RHEL 7 - Parte 3
- Como instalar o CDH e configurar as colocações do serviço no CentOS/RHEL 7 - Parte 4
- Como configurar alta disponibilidade para Namenode - Parte 5
- Como configurar alta disponibilidade para gerente de recursos - Parte 6
Vamos começar…
Instalação e configuração da colméia
1. Logar em Gerente de Cloudera no URL abaixo e navegar Gerente de Cloudera -> Adicionar serviço.
http: // 13.233.129.39: 7180/cmf/home
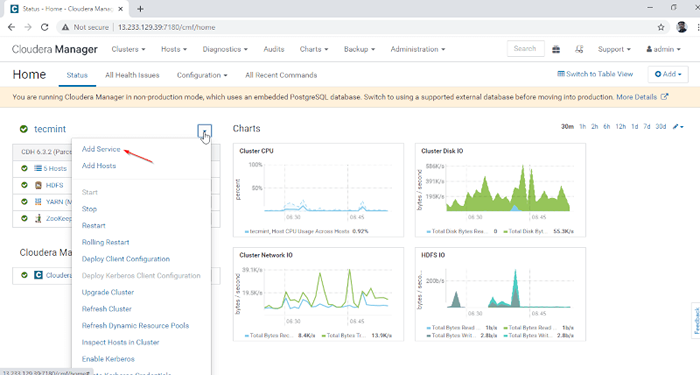 Adicionar serviço no gerente de cloudera
Adicionar serviço no gerente de cloudera 2. Selecione o serviço 'Hive'.
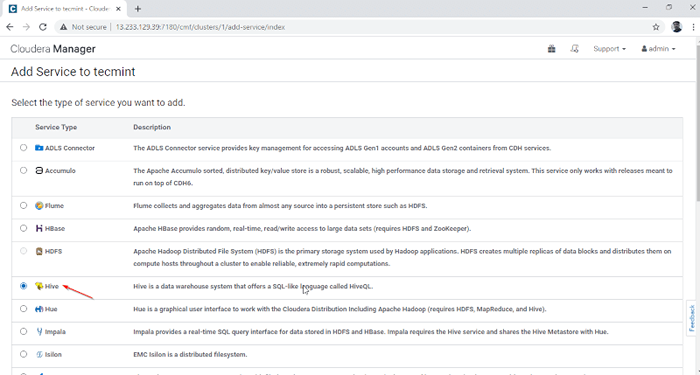 Escolha o serviço de colméia
Escolha o serviço de colméia 3. Atribua os serviços nos nós.
- Porta de entrada - É o serviço do cliente em que o usuário pode acessar a colméia. Geralmente, este serviço será colocado em Borda nós dedicados aos usuários.
- Metastore de colméia - É um repositório central para armazenar metadados de colméia.
- Servidor webhcat - É uma API da Web para Hcatalog e outros serviços Hadoop.
- HiveServer2 - É uma interface de clientes para execução de consulta no Hive.
Depois de selecionar os servidores, clique em 'Continuar'Para prosseguir.
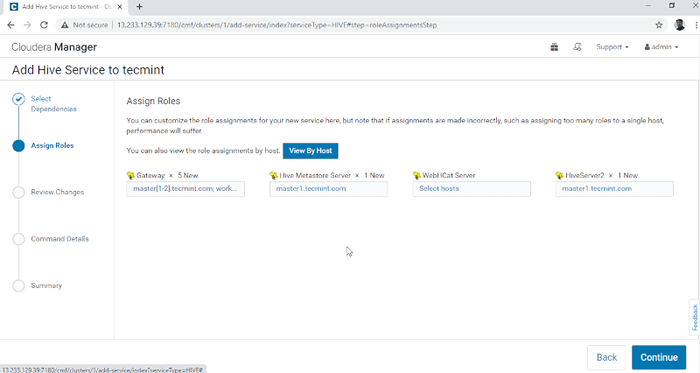 Atribuir serviço como nós
Atribuir serviço como nós 4. Hive Metastore precisa de um banco de dados subjacente para armazenar metadados. Aqui estamos usando o padrão PostGresql banco de dados que está embutido com CDH.
Abaixo mencionados no banco de dados Detalhes serão inseridos automaticamente, 'Conexão de teste'será ignorado quando o banco de dados mencionado será criado em tempo real. Em tempo real, precisamos criar o banco de dados no banco de dados externo e testar a conexão para prosseguir. Uma vez feito, clique no 'Continuar'.
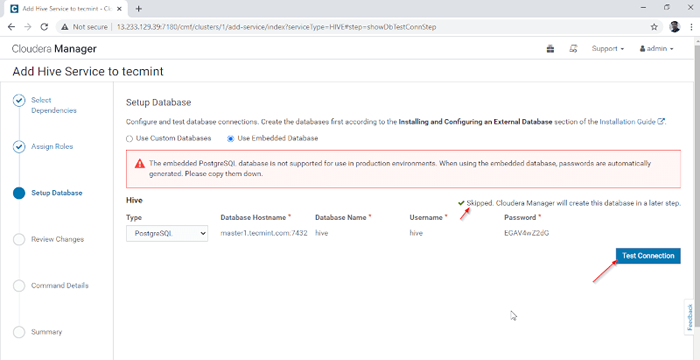 Banco de dados de configuração
Banco de dados de configuração 5. Configure o Hive Warehouse diretório, /Usuário/Hive/Warehouse é o caminho do diretório padrão para armazenar mesas de colméia. Clique no 'Continuar'.
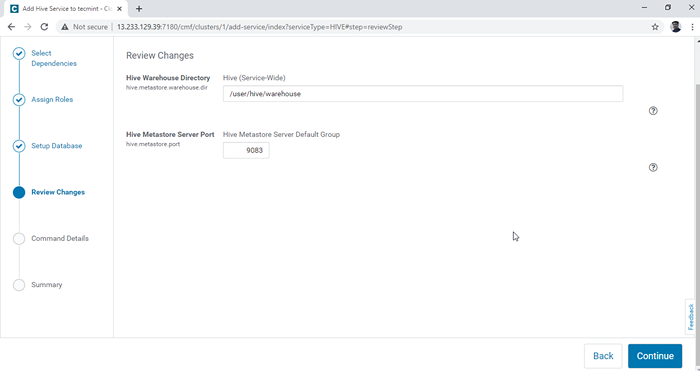 Escolha o diretório de armazém de Hive
Escolha o diretório de armazém de Hive 6. A instalação do Hive é iniciada.
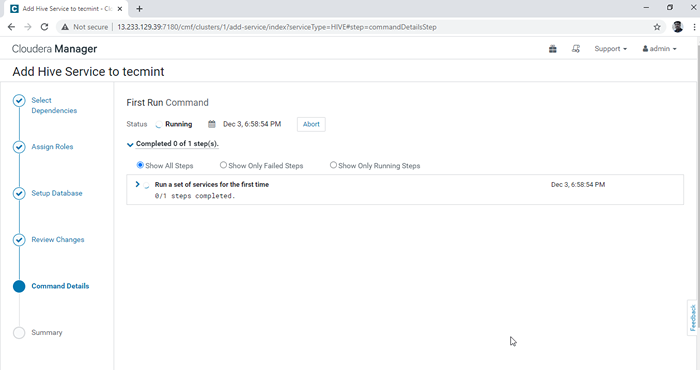 Progresso da instalação da colméia
Progresso da instalação da colméia 7. Depois que a instalação concluída, você pode obter o 'Finalizado' status. Clique 'Continuar'Para prosseguir.
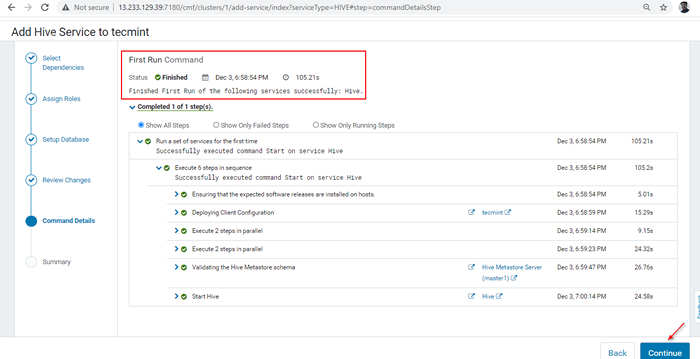 Instalação do Hive terminado
Instalação do Hive terminado 8. Instalação e configuração de colméias concluídas com êxito. Clique 'Terminar'Para concluir o procedimento de instalação.
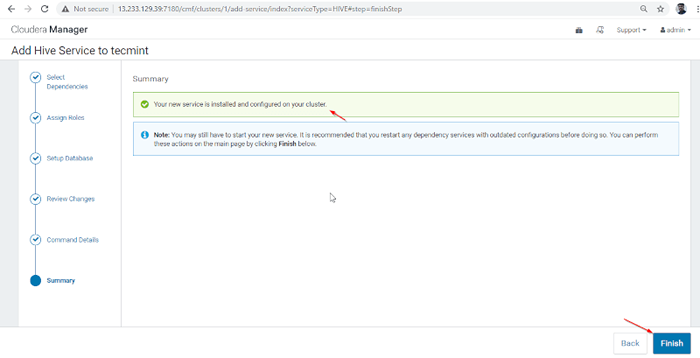 Termine a instalação do Hive
Termine a instalação do Hive 9. Você pode ver o Hive Serviço adicionado em Conjunto através Painel de gerente de cloudera.
 Serviço de Hive adicionado
Serviço de Hive adicionado 10. Você pode ver o HiveServer2 em Instâncias de Hive. Nós adicionamos HiveServer2 em Master1.
Gerente de Cloudera -> Hive -> Instâncias -> HiveServer2.
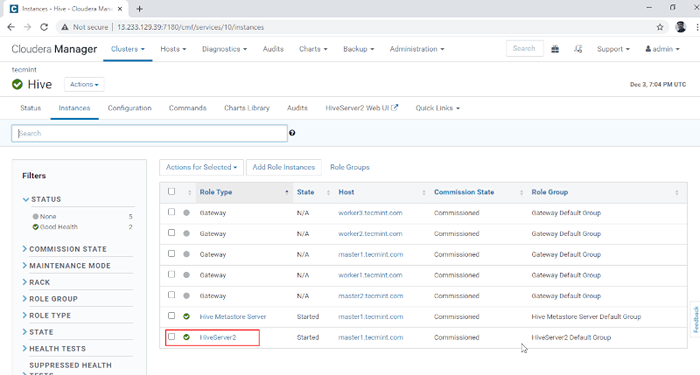 Veja as instâncias do HiveServer2
Veja as instâncias do HiveServer2 Permitindo alta disponibilidade na colméia
11. Em seguida, adicione o papel da colméia indo para Gerente de Cloudera -> Hive -> Ações -> Adicione o papel Instâncias.
 Adicione a instância de função Hive
Adicione a instância de função Hive 12. Selecione os servidores onde você deseja colocar extra HiveServer2. Você pode adicionar mais de dois, não há limite. Aqui estamos adicionando um extra HiveServer2 em Master2.
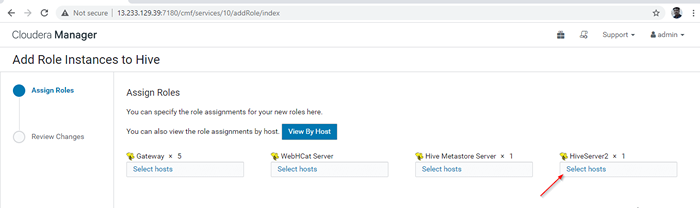 Escolha servidor para Hive
Escolha servidor para Hive 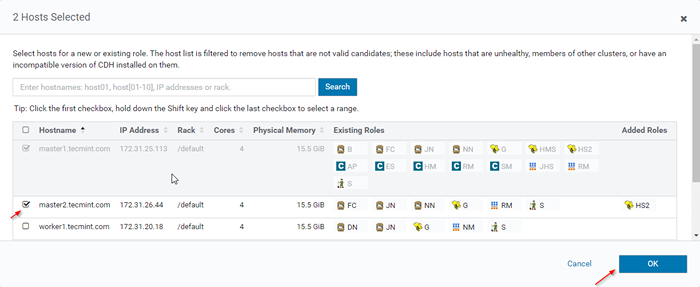 Escolha o servidor host
Escolha o servidor host 13. Depois de selecionar o servidor, clique em 'Continuar'.
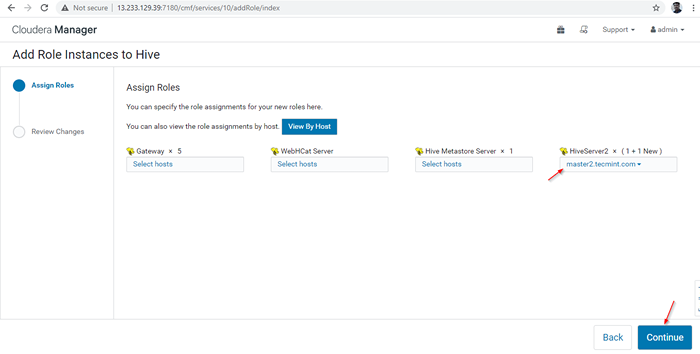 Servidor adicionado
Servidor adicionado 14. A HIVERSERVER2 será adicionado ao Instâncias de colméia, você precisa começar indo para Gerente de Cloudera -> Hive -> Instâncias -> (Selecione HiveServer2 adicionado recentemente) -> Ação para selecionados -> Começar.
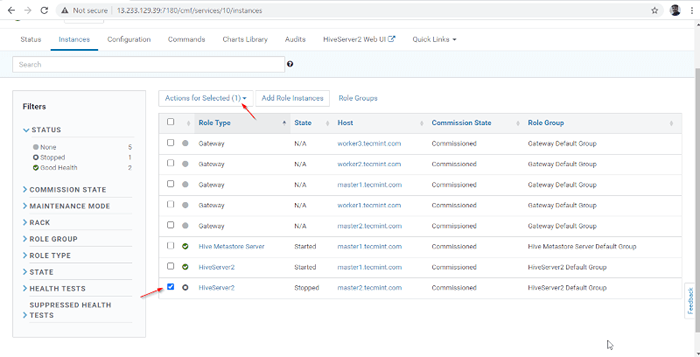 Escolha Hive Server
Escolha Hive Server 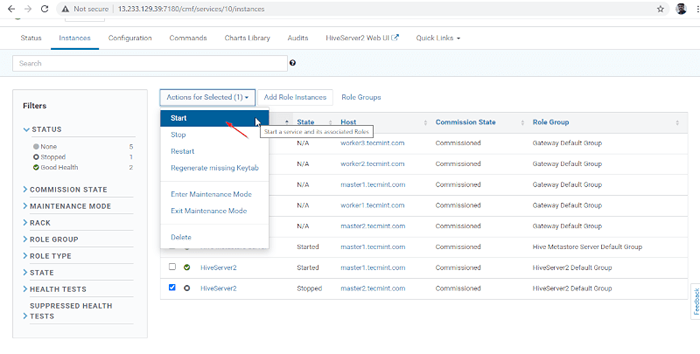 Inicie o Hive Server
Inicie o Hive Server 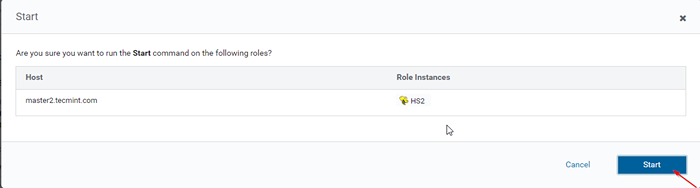 Inicie o servidor Hive
Inicie o servidor Hive 15. Uma vez HiveServer2 Começou em Master2, você vai conseguir o status 'Finalizado'. Clique Fechar.
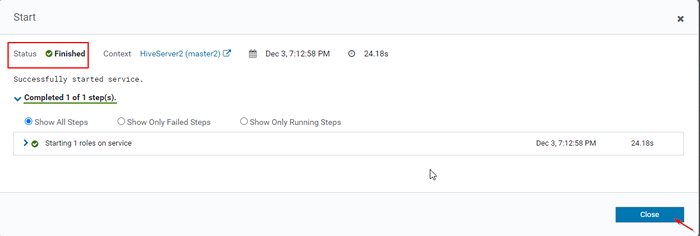 Concluído
Concluído 16. Você pode ver, tanto o HiveServer2s Estão correndo.
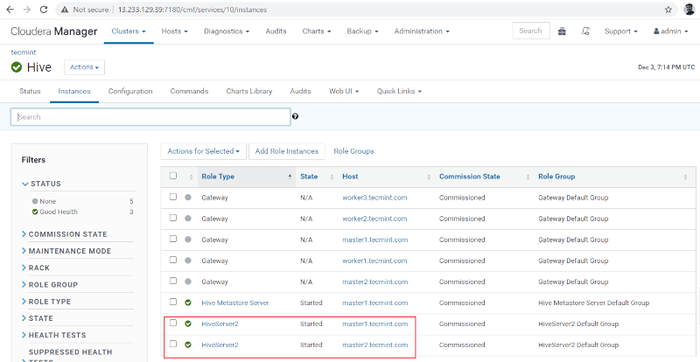 Verifique o status dos servidores Hive
Verifique o status dos servidores Hive Verificando a disponibilidade da colméia
Podemos conectar o HiveServer2 Através da linha de entrega que é um fina cliente e linha de comando. Ele usa o driver JDBC para estabelecer a conexão.
17. Faça login no servidor onde Gateway de colméia está correndo.
[[Email protegido] ~] $ Beeline
 Conecte -se ao HiveServer2
Conecte -se ao HiveServer2 18. Introduzir o JDBC string de conexão para conectar o HiveServer2. Nesse sentido, o corda Estamos mencionando o HIVERSERVER2 (Master2) com seu número de porta padrão 10000. Esta string de conexão só se conectará ao HiveServer2 que está funcionando Master2.
Beeline> !conectar "JDBC: hive2: // master1.Tecmint.com: 10000 "
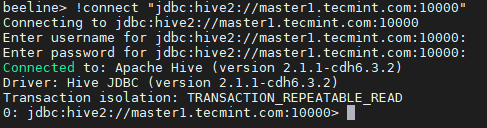 String de conexão JDBC
String de conexão JDBC 19. Execute uma amostra de consulta.
0: JDBC: hive2: // master1.Tecmint.COM: 10000> Mostrar bancos de dados;
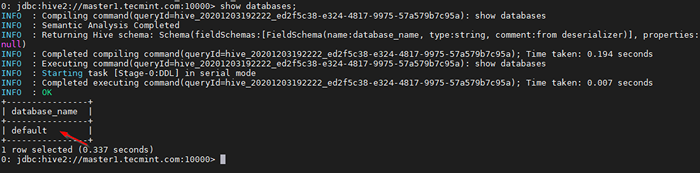 Execute uma consulta de amostra
Execute uma consulta de amostra Este é o banco de dados padrão que vem embutido.
20. Use o comando abaixo para encerrar a sessão de colméia.
0: JDBC: hive2: // master1.Tecmint.com: 10000> !desistir
 Pare de Hive Session
Pare de Hive Session 21. Você pode usar a mesma maneira de se conectar HiveServer2 funcionando Master2.
Beeline> !conectar "JDBC: hive2: // master2.Tecmint.com: 10000 "
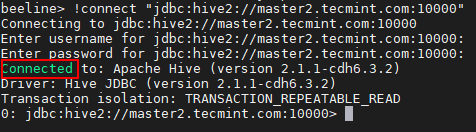 Conecte -se ao Hive Server
Conecte -se ao Hive Server 23. Podemos conectar o HiveServer2 em Descoberta do Zookeeper modo. Neste método, não precisamos mencionar o HiveServer2 na string de conexão, em vez disso, estamos usando Funcionário do zoológico Para descobrir o disponível HiveServer2.
Aqui podemos usar um balanceador de carga de terceiros para equilibrar a carga entre os disponíveis HIVERSERVER2. A configuração abaixo é necessária para ativar Modo de descoberta do Zookeeper indo para Gerente de Cloudera -> Hive -> Configuração.
 Ativar modo de descoberta do Zookeeper
Ativar modo de descoberta do Zookeeper 24. Em seguida, pesquise a propriedade “Snippet de configuração avançada do HiveServer2”E clique no + Símbolo para adicionar a propriedade abaixo.
Nome: Hive.Server2.apoiar.dinâmico.serviço.Valor da descoberta: Descrição True:
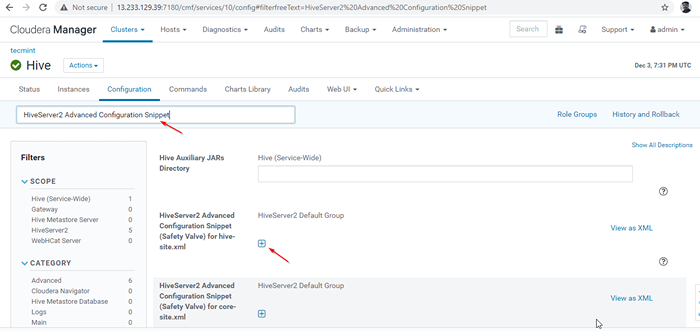 Snippet de configuração avançada do HiveServer2
Snippet de configuração avançada do HiveServer2 25. Depois de entrar na propriedade, clique em 'Salvar alterações'.
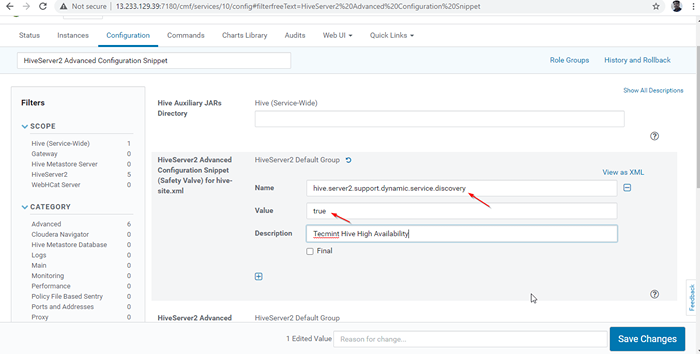 Adicionar propriedade
Adicionar propriedade 26. Ao fazer alterações na configuração, precisa reiniciar os serviços afetados clicando no símbolo da cor laranja para reiniciar os serviços.
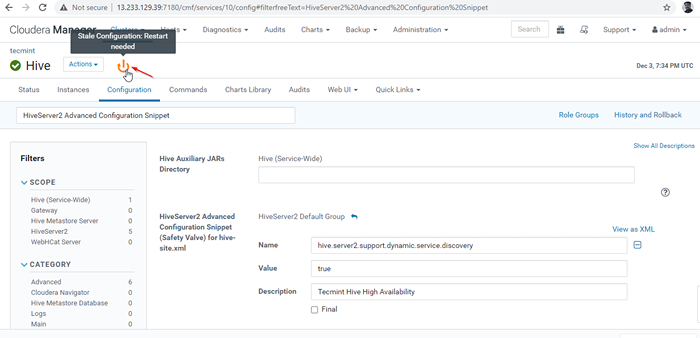 Reiniciar serviços
Reiniciar serviços 27. Clique 'Reinicie o velho' Serviços.
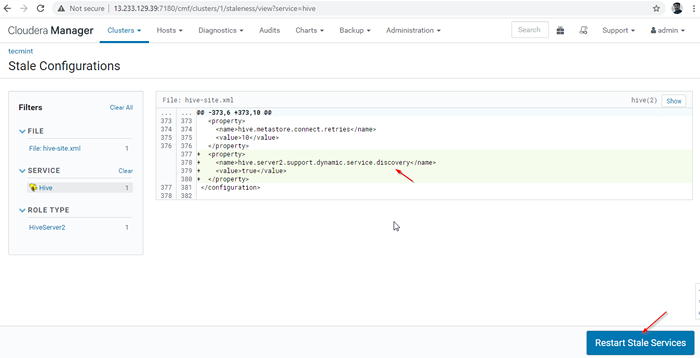 Reinicie os serviços velhos
Reinicie os serviços velhos 28. Existem duas opções disponíveis. Se o cluster estiver em produção ao vivo, precisamos preferir o reinício do rolamento para minimizar a interrupção. Como estamos instalando recentemente, podemos escolher a segunda opção 'Re-implantar a configuração do cliente', e clique'Reinicie agora'.
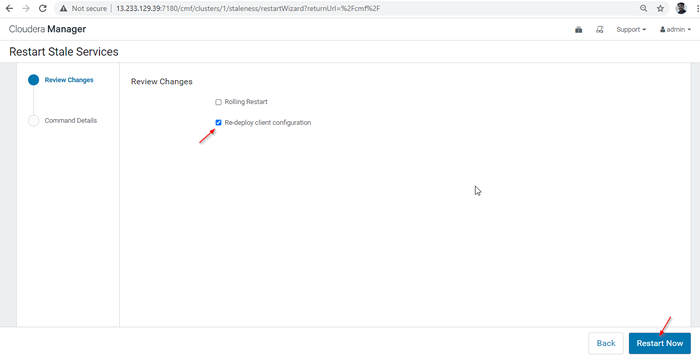 Re-implantar a configuração do cliente
Re-implantar a configuração do cliente 29. Uma vez que o reiniciar concluir com sucesso, você estará recebendo o status 'Finalizado'. Clique 'Terminar'Para completar o processo.
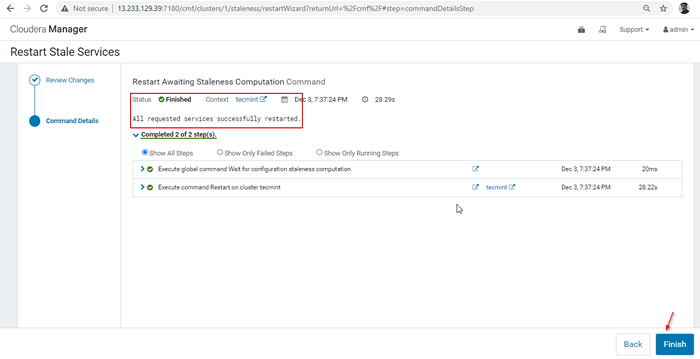 Termine o processo
Termine o processo 30. Agora vamos conectar o HiveServer2 usando Descoberta do Zookeeper modo. No JDBC conexão, a string que precisamos usar o Funcionário do zoológico servidores com seu número de porta 2081. Colete os servidores Zookeeper indo para Gerente de Cloudera -> Funcionário do zoológico -> Instâncias -> (Anote os nomes dos servidores).
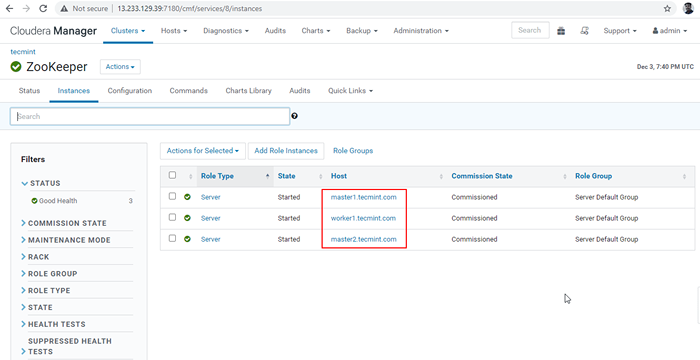 Servidores Zookeeper
Servidores Zookeeper Estes são os três servidores com Zookeeper, 2181 é o número da porta.
Master1.Tecmint.com: 2181 Master2.Tecmint.com: 2181 trabalhador1.Tecmint.com: 2181
31. Agora entre entre linha direta.
[[Email protegido] ~] $ Beeline
 Conectar -se à linha direta
Conectar -se à linha direta 32. Introduzir o JDBC string de conexão como mencionado abaixo. Temos que mencionar o Modo de descoberta de serviço e Namespace de zookeeper. 'HiveServer2'é o espaço para nome padrão do HiVeserver2.
Beeline>!conectar "JDBC: hive2: // master1.Tecmint.com: 2181, master2.Tecmint.com: 2181, trabalhador1.Tecmint.COM: 2181/; ServiceScoberyMode = Zookeeper; ZookeeperNamespace = HiveServer2 "
 Digite String de conexão JDBC
Digite String de conexão JDBC 33. Agora a sessão está conectada a HiveServer2 funcionando Master1. Execute uma amostra de consulta para validar. Use o comando abaixo para criar um banco de dados.
0: JDBC: hive2: // master1.Tecmint.com: 2181, mastro> criar banco de dados Tecmint;
 Crie banco de dados
Crie banco de dados 34. Use o comando abaixo para listar o banco de dados.
0: JDBC: hive2: // master1.Tecmint.com: 2181, mastro> show bancos de dados;
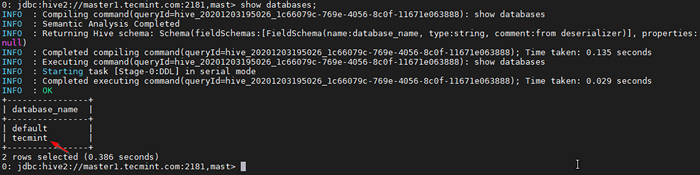 Listar banco de dados
Listar banco de dados 35. Agora vamos validar a alta disponibilidade em Modo de descoberta do Zookeeper. Vá para Gerente de Cloudera e pare o HiveServer2 sobre Master1 que testamos acima.
Gerente de Cloudera -> Hive -> Instâncias -> (selecione HiveServer2 sobre Master1) -> Ação para selecionados -> Parar.
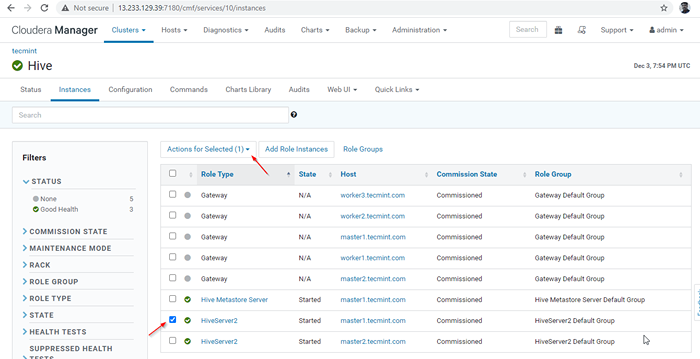 Escolha Hive Server
Escolha Hive Server 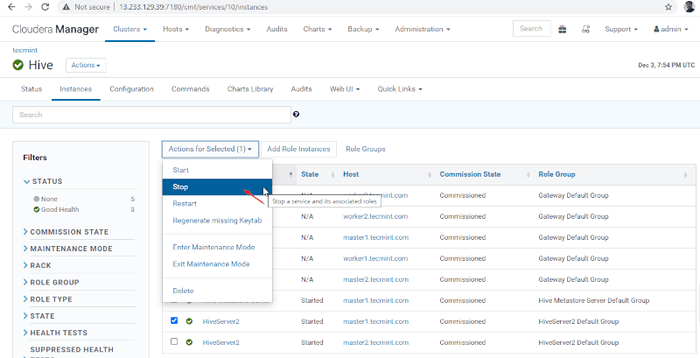 Stop Hive Server
Stop Hive Server 36. Clique no 'Parar'. Uma vez parado, você estará recebendo o status 'Finalizado'. Verifique o HiveServer2 sobre Master1 navegando para Hive -> Instâncias.
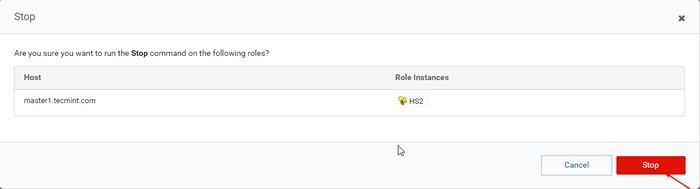 Stop Hive Server
Stop Hive Server 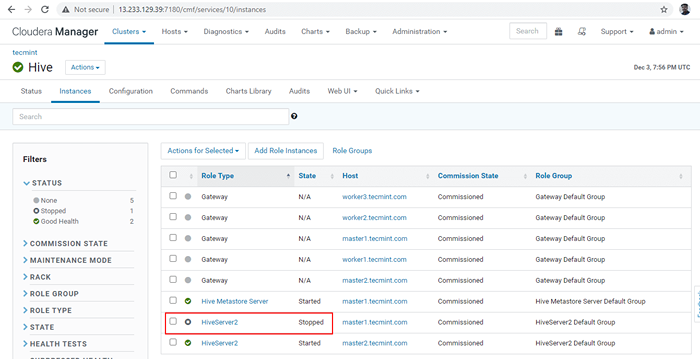 Verifique o servidor Hive
Verifique o servidor Hive 37. Entre no entre linha direta e conectar o HiveServer2 usando o mesmo JDBC string de conexão com Modo de descoberta do Zookeeper Como fizemos nas etapas acima.
[[Email Protected] ~] $ Beeline!conectar "JDBC: hive2: // master1.Tecmint.com: 2181, master2.Tecmint.com: 2181, trabalhador1.Tecmint.COM: 2181/; ServiceScoberyMode = Zookeeper; ZookeeperNamespace = HiveServer2 "
 Conecte o HiveServer2
Conecte o HiveServer2 Agora você estará conectado a HiveServer2 funcionando Master2.
38. Validar com uma consulta de amostra.
0: JDBC: hive2: // master1.Tecmint.com: 2181, mastro> show bancos de dados;
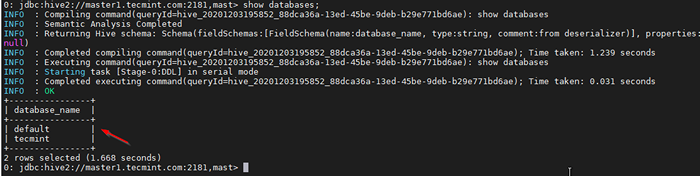 Valide a consulta de amostra
Valide a consulta de amostra Conclusão
Neste artigo, passamos pelas etapas detalhadas para ter o Hive Data Warehouse modelo em nosso Conjunto com Alta disponibilidade. Em um ambiente de produção em tempo real, mais de três HiveServer2 será colocado com Modo de descoberta do Zookeeper habilitado.
Aqui, todo o HiveServer2's estão se registrando com Funcionário do zoológico sob um comum Espaço para nome. Zookeeper dinamicamente descobre o disponível HiveServer2 e estabelece a sessão de colméia.
- « Como instalar o VMware Workstation 16 Pro em sistemas Linux
- Como instalar um cluster Kubernetes no CentOS 8 »