

Como criar um modo de espera quente com PostgreSQL
- 2679
- 511
- Randal Kuhlman
Objetivo
Nosso objetivo é criar uma cópia de um banco de dados PostGresql que esteja constantemente sincronizando com o original e aceita consultas somente leitura.
Sistema operacional e versões de software
- Sistema operacional: Red Hat Enterprise Linux 7.5
- Software: PostgreSQL Server 9.2
Requisitos
Acesso privilegiado aos sistemas mestre e escravo
Convenções
- # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de
sudocomando - $ - dados os comandos do Linux a serem executados como um usuário não privilegiado regular
Introdução
O PostgreSQL é um RDBMS de código aberto (sistema de gerenciamento de banco de dados relacional) e, com quaisquer bancos de dados, a necessidade pode surgir para dimensionar e fornecer HA (alta disponibilidade). Um único sistema que presta um serviço é sempre um possível ponto único de falha - e mesmo com sistemas virtuais, pode haver um momento em que você não pode adicionar mais recursos a uma única máquina para lidar com a carga cada vez maior. Também pode haver uma necessidade de outra cópia do conteúdo do banco de dados que pode ser consultado para análises de longa duração, que não são adequadas para serem executadas no banco de dados de produção altamente transações com uso intensivo de transações. Esta cópia pode ser uma restauração simples do backup mais recente de outra máquina, mas os dados estariam desatualizados assim que forem restaurados.
Ao criar uma cópia do banco de dados que está constantemente replicando seu conteúdo com o original (chamado mestre ou primário), mas, ao fazê-lo, aceitar e retornar os resultados das consultas somente leitura, podemos criar um Hot Standby que têm de perto o mesmo conteúdo.
Em caso de falha no mestre, o banco de dados de espera (ou escravo) pode assumir o papel de primária, interromper a sincronização e aceitar solicitações de leitura e gravação, para que as operações possam prosseguir e o mestre fracassado pode ser devolvido à vida (talvez como em espera, mudando o caminho de sincronização). Quando o primário e o modo de espera estão em execução, consultas que não tentam modificar o conteúdo do banco de dados podem ser descarregadas para o modo de espera, para que o sistema geral possa lidar com uma carga maior. Observe, no entanto, que haverá algum atraso - o modo de espera estará por trás do mestre, na quantidade de tempo que leva para sincronizar as mudanças. Esse atraso pode cautelar dependendo da configuração.
Existem muitas maneiras de construir uma sincronização mestre-escrava (ou mesmo mestre-mestre) com o PostgreSQL, mas neste tutorial vamos configurar a replicação de streaming, usando o mais recente servidor PostGresql disponível nos repositórios Red Hat. O mesmo processo geralmente se aplica a outras distribuições e versões de RDMBS, mas pode haver diferenças em relação aos caminhos do sistema de arquivos, gerentes de pacotes e serviços e outros.
Instalando o software necessário
Vamos instalar o PostGresql com yum Para ambos os sistemas:
YUM Instale o PostGresql-Server
Após a instalação bem -sucedida, precisamos inicializar os dois clusters de banco de dados:
# PostGresql-setup InitDB Inicializando o banco de dados… . OK Para fornecer inicialização automática para os bancos de dados na inicialização, podemos ativar o serviço em Systemd:
SystemCtl Ativar PostgreSQL
Usaremos 10.10.10.100 como primário e 10.10.10.101 Como o endereço IP da máquina de espera.
Configure o mestre
Geralmente é uma boa ideia fazer backup de qualquer arquivo de configuração antes de fazer alterações. Eles não ocupam espaço que vale a pena mencionar e, se algo der errado, o backup de um arquivo de configuração em funcionamento pode ser um salva -vidas.
Precisamos editar o PG_HBA.conf com um editor de arquivos de texto como vi ou Nano. Precisamos adicionar uma regra que permitirá ao usuário do banco de dados do modo de espera acessar o primário. Esta é a configuração do lado do servidor, o usuário ainda não existe no banco de dados. Você pode encontrar exemplos no final do arquivo comentados que estão relacionados ao replicação base de dados:
# Permitir conexões de replicação do localhost, por um usuário com o privilégio de replicação #. #Local Replicação Postgres Peer #host Replicação Postgres 127.0.0.1/32 Ident #host Replicação Postgres :: 1/128 Ident
Vamos adicionar outra linha ao final do arquivo e marcar -a com um comentário para que possa ser facilmente visto o que é alterado dos padrões:
## MyConf: Replicação Replicação Replicação Repusser 10.10.10.101/32 MD5
Nos sabores de Red Hat, o arquivo está localizado por padrão sob o /var/lib/pgsql/data/ diretório.
Também precisamos fazer alterações no arquivo de configuração principal do servidor de banco de dados, PostGresql.conf, que está localizado no mesmo diretório, encontramos o PG_HBA.conf.
Encontre as configurações encontradas na tabela abaixo e modifique -as da seguinte forma:
| Seção | Configuração padrão | Configuração modificada |
|---|---|---|
| Conexões e autenticação | #listen_addresses = 'localhost' | out_addresses = '*' |
| Escreva com antecedência log | #wal_level = mínimo | wal_level = 'hot_standby' |
| Escreva com antecedência log | #archive_mode = off | archive_mode = ON |
| Escreva com antecedência log | #archive_command = ” | Archive_Command = 'True' |
| REPLICAÇÃO | #max_wal_senders = 0 | max_wal_senders = 3 |
| REPLICAÇÃO | #hot_standby = off | hot_standby = on |
Observe que as configurações acima são comentadas por padrão; você precisa de descomentar e mudar seus valores.
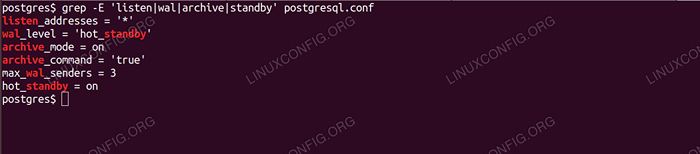
Você pode grep os valores modificados para verificação. Você deve obter algo como o seguinte:
Verificando as mudanças com o grep Agora que as configurações estão bem, vamos iniciar o servidor principal:
# SystemCtl Iniciar PostgreSQL
E use PSQL Para criar o usuário do banco de dados que lidará com a replicação:
# su -postgres -bash -4.2 $ psql psql (9.2.23) Digite "Ajuda" para obter ajuda. PostGres =# Crie o limite de conexão do Login de Login de Replicação do Repusor de Usuário 'SecretPassword' -1; Criar papel
Tome nota da senha que você dá ao Repusador, Vamos precisar do lado de espera.
Configure o escravo
Deixamos o modo de espera com o initdb etapa. Vamos trabalhar como o PostGres Usuário, que é superusuário no contexto do banco de dados. Precisaremos de uma cópia inicial do banco de dados primário, e vamos conseguir isso com pg_basebackup comando. Primeiro, limpamos o diretório de dados em espera (faça uma cópia de antemão, se desejar, mas é apenas um banco de dados vazio):
$ rm -rf/var/lib/pgsql/data/*
Agora estamos prontos para fazer uma cópia consistente do primário para a espera:
$ pg_basebackup -h 10.10.10.100 -u RepUser -d/var/lib/pgsql/data/senha: aviso: pg_stop_backup completo, todos os segmentos do WAL necessários foram arquivados Precisamos especificar o endereço IP do mestre depois -H e o usuário que criamos para replicação, neste caso Repusador. Como o primário está vazio além deste usuário que criamos, o pg_basebackup deve ser concluído em segundos (dependendo da largura de banda de rede). Se algo der errado, verifique a regra da HBA no primário, a correção do endereço IP dado ao pg_basebackup comando, e que a porta 5432 na primária é acessível a partir de espera (por exemplo, com Telnet).
Quando o backup terminar, você notará que o diretório de dados é preenchido no escravo, incluindo arquivos de configuração (lembre -se, excluímos tudo deste diretório):
# ls/var/lib/pgsql/data/backup_label.Old PG_CLOG PG_LOG PG_SERIAL PG_SUBTRANS PG_VERSION POSTMASTER.Optos base PG_HBA.conf PG_Multixact PG_SNAPSHOTS PG_TBLSPC PG_XLOG PostMaster.pid global pg_ident.conf PG_Notify PG_STAT_TMP PG_TWOPHASE POSTGRESQL.Conf recuperação.conf Agora precisamos fazer alguns ajustes na configuração do modo de espera. O endereço IP permitido para o Repusor se conectar da necessidade de ser o endereço do servidor mestre em PG_HBA.conf:
# cauda -n2/var/lib/pgsql/data/pg_hba.conf ## myconf: replicação replicação replicação Repusser 10.10.10.100/32 MD5 As mudanças no PostGresql.conf são os mesmos do mestre, pois copiamos esse arquivo com o backup também. Dessa forma, ambos os sistemas podem assumir o papel de mestre ou espera em relação a esses arquivos de configuração.
No mesmo diretório, precisamos criar um arquivo de texto chamado recuperação.conf, e adicione as seguintes configurações:
# cat/var/lib/pgsql/dados/recuperação.Conf Standby_mode = 'em' primary_conninfo = 'host = 10.10.10.100 porta = 5432 usuário = senha do repusador = secretPassword 'trigger_file ='/var/lib/pgsql/trigger_file ' Observe que para o primário_conninfo Configuração, usamos o endereço IP do Primário e a senha que demos para Repusador no banco de dados mestre. O arquivo de gatilho poderia estar praticamente em qualquer lugar legível pelo PostGres Usuário do sistema operacional, com qualquer nome de arquivo válido - no evento de falha primária, o arquivo pode ser criado (com tocar por exemplo) que desencadeará failover no modo de espera, o que significa que o banco de dados começa a aceitar operações de gravação também.
Se este arquivo recuperação.conf está presente, o servidor entrará no modo de recuperação na inicialização. Temos tudo no lugar, para que possamos iniciar o modo de espera e ver se tudo funciona como deveria ser:
# SystemCtl Iniciar PostgreSQL
Deve demorar um pouco mais do que o habitual para recuperar o prompt de volta. O motivo é que o banco de dados executa a recuperação para um estado consistente em segundo plano. Você pode ver o progresso no arquivo de log principal do banco de dados (seu nome de arquivo será diferente dependendo do dia da semana):
$ tailf/var/lib/pgsql/data/pg_log/postgresql-thu.LOG LOG: Digitando o modo de modo de espera: streaming replicação conectada com êxito ao log primário: o refazer começa em 0/3000020 LOG: Estado de recuperação consistente alcançado em 0/30000E0 LOG: O sistema de banco de dados está pronto para aceitar as conexões de leitura somente Verificando a configuração
Agora que ambos os bancos de dados estão em funcionamento, vamos testar a configuração criando alguns objetos no primário. Se tudo correr bem, esses objetos devem aparecer em espera.
Podemos criar alguns objetos simples no primário (que minha aparência familiar) com PSQL. Podemos criar o script SQL simples abaixo chamado amostra.SQL:
-- Crie uma sequência que servirá como PK da tabela de funcionários, crie seqüência de funcionários_seq inicia com 1 incremento por 1 sem maxvalue minvalue 1 cache 1; - Crie a tabela de funcionários Criar funcionários da tabela (emp_id numérico chave primária padrão nextVal ('funcionários_seq' :: regclass), primeiro_name text não nulo, last_name text não nulo, birth_year numérico não nulo, bift_month numérico não nulo, birt_dayofmonth numérico não nulo) ; - Insira alguns dados na inserção da tabela nos funcionários (First_Name, Last_Name, BIRND_YEAR, BIRNH_MONTH, BIRNH_DAYOFMONTH) valores ('Emily', 'James', 1983,03,20); inserir em funcionários (primeiro_name, last_name, birt_year, birth_month, birth_dayofmonth) valores ('John', 'Smith', 1990,08,12); É uma boa prática manter as modificações da estrutura do banco de dados em scripts (opcionalmente empurrados para um repositório de código) também, para referência posterior. Compensa quando você precisa saber o que você modificou e quando. Agora podemos carregar o script no banco de dados:
$ psql < sample.sql CREATE SEQUENCE NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "employees_pkey" for table "employees" CREATE TABLE INSERT 0 1 INSERT 0 1 E podemos consultar a tabela que criamos, com os dois registros inseridos:
PostGres =# Selecione * dos funcionários; EMP_ID | primeiro_name | Último nome | nascimento_year | nascimento_month | birth_dayofmonth --------+------------+-----------+------------+- -----------+------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 linhas) Vamos consultar o modo de espera para obter dados que esperamos ser idênticos ao primário. Em espera, podemos executar a consulta acima:
PostGres =# Selecione * dos funcionários; EMP_ID | primeiro_name | Último nome | nascimento_year | nascimento_month | birth_dayofmonth --------+------------+-----------+------------+- -----------+------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 linhas) E com isso terminamos, temos uma configuração de espera quente com um servidor primário e um em espera, sincronizando de mestre para escravo, enquanto as consultas somente leitura são permitidas no escravo.
Conclusão
Existem muitas maneiras de criar replicação com o PostgreSQL, e há muitas tualhas em relação à replicação de streaming que configuramos também para tornar a configuração mais robusta, falha ou até mesmo ter mais membros. Este tutorial não é aplicável a um sistema de produção - ele deve mostrar algumas diretrizes gerais sobre o que está envolvido em tal configuração.
Lembre -se de que a ferramenta pg_basebackup está disponível apenas no PostgreSQL versão 9.1+. Você também pode considerar adicionar o arquivamento válido do Wal à configuração, mas, por uma questão de simplicidade, pulamos isso neste tutorial para manter as coisas para fazer o mínimo enquanto atingem um par de sistemas sincronizados em funcionamento. E finalmente mais uma coisa a observar: o modo de espera é não cópia de segurança. Tem um backup válido o tempo todo.
Tutoriais do Linux relacionados:
- Coisas para instalar no Ubuntu 20.04
- Ubuntu 20.04 Instalação PostGresql
- Ubuntu 22.04 Instalação PostGresql
- Uma introdução à automação, ferramentas e técnicas do Linux
- Coisas para fazer depois de instalar o Ubuntu 20.04 fossa focal linux
- Arquivos de configuração do Linux: os 30 primeiros mais importantes
- Download do Linux
- Linux pode obter vírus? Explorando a vulnerabilidade do Linux…
- Mint 20: Melhor que o Ubuntu e o Microsoft Windows?
- Coisas para instalar no Ubuntu 22.04