

Melhores práticas para implantar o Hadoop Server no CentOS/Rhel 7 - Parte 1

- 1043
- 251
- Wendell Legros
Nesta série de artigos, vamos cobrir todo Cloudera Hadoop Cluster Building construção com Fornecedor e Industrial práticas recomendadas recomendadas.
Parte 1: Práticas recomendadas para implantar o Hadoop Server no CentOS/Rhel 7 Parte 2: Configurando pré-requisitos do Hadoop e endurecimento de segurança Parte 3: Como instalar e configurar o gerente de Cloudera no CentOS/RHEL 7 Parte 4: Como instalar o CDH e configurar as colocações de serviços no CentOS/RHEL 7 Parte 5: Como configurar alta disponibilidade para namenode Parte 6: Como configurar alta disponibilidade para gerente de recursos Parte 7: Como instalar e configurar o Hive com alta disponibilidade Parte 8: Como instalar e configurar a Sentry (ferramenta de autorização) Parte 9: Como instalar Kerberos (Kerberising the Cluster) para autenticação do Hadoop Parte 10: Como ajustar o cluster (ajuste de fios) no CentOS/RHEL 7OS instalação e fazendo OS pré-requisitos de nível são os primeiros passos para construir um Cluster Hadoop. Hadoop pode ser executado na plataforma de vários sabores da Linux: CENTOS, Chapéu vermelho, Ubuntu, Debian, SUSE etc., Na produção em tempo real, a maior parte do Clusters Hadoop são construídos em cima de RHEL/CENTOS, nós vamos usar CENTOS 7 Para demonstração nesta série de tutoriais.
Em uma organização, a instalação do sistema operacional pode ser feita usando Kickstart. Se for um cluster de 3 a 4 nós, a instalação manual será possível, mas se construirmos um grande cluster com mais de 10 nós, é tedioso instalar OS um por um por um. Nesse cenário, o método Kickstart entra em cena, podemos prosseguir com a instalação em massa usando o Kickstart.
Alcançando um bom desempenho de um Ambiente Hadoop depende do fornecimento do hardware e software corretos. Então, construindo uma produção Cluster Hadoop envolve muita consideração sobre hardware e software.
Neste artigo, passaremos por vários benchmarks sobre a instalação do sistema operacional e algumas práticas recomendadas para implantar Cloudera Hadoop Cluster Server sobre CENTOS/RHEL 7.
Consideração importante e práticas recomendadas para implantar o Hadoop Server
A seguir são as melhores práticas para a criação de implantação Cloudera Hadoop Cluster Server sobre CENTOS/RHEL 7.
- Os servidores Hadoop não exigem servidores padrão corporativos para criar um cluster, requer hardware de commodities.
- No cluster de produção, com 8 a 12 discos de dados são recomendados. De acordo com a natureza da carga de trabalho, precisamos decidir sobre isso. Se o cluster for para aplicações intensivas em computação, ter 4 a 6 unidades é uma prática recomendada para evitar problemas de E/S.
- As unidades de dados devem ser particionadas individualmente, por exemplo - a partir de /data01 para /data10.
- A configuração do RAID não é recomendada para nós do trabalhador, porque o próprio Hadoop fornece a tolerância a falhas nos dados replicando os blocos em 3 por padrão. Então Jbod é o melhor para nós do trabalhador.
- Para servidores mestre, Raid 1 é a melhor prática.
- O sistema de arquivos padrão em CENTOS/RHEL 7.x é XFS. Hadoop suporta XFS, Ext3 e Ext4. O sistema de arquivo recomendado é ext3, pois é testado para um bom desempenho.
- Todos os servidores devem estar tendo a mesma versão do sistema operacional, pelo menos uma pequena liberação menor.
- É prática melhor ter hardware homogêneo (todos os nós do trabalhador devem ter as mesmas características de hardware (RAM, espaço em disco e núcleo etc.).
- De acordo com a carga de trabalho do cluster (carga de trabalho equilibrada, computação intensiva, E/S intensiva) e tamanho, recurso (RAM, CPU) Planejamento por servidor será diferente.
Encontre o exemplo abaixo para a partição de disco dos servidores do armazenamento de 24 TB.
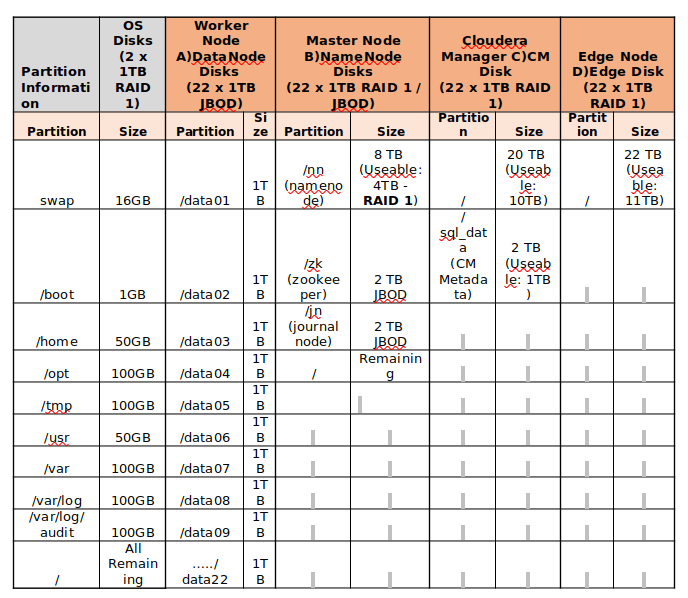 Particionamento de disco
Particionamento de disco Instalando o CentOS 7 para a implantação do Hadoop Server
Coisas que você precisa saber antes de instalar CENTOS 7 servidor para Servidor Hadoop.
- A instalação mínima é suficiente para Servidores Hadoop (nós do trabalhador), em alguns casos, a GUI pode ser instalada apenas para servidores mestre ou servidores de gerenciamento, onde podemos usar navegadores para UIs da Web de ferramentas de gerenciamento.
- Configurando redes, nome do host e outras configurações relacionadas ao sistema operacional podem ser feitas após a instalação do sistema operacional.
- Em tempo real, os fornecedores de servidores terão seu próprio console para interagir e gerenciar os servidores, por exemplo - os servidores Dell estão tendo IDRAC, que é um dispositivo, incorporado a servidores. Usando essa interface IDRAC, podemos instalar o sistema operacional com uma imagem do sistema operacional em nosso sistema local.
Neste artigo, instalamos o sistema operacional (CENTOS 7) na máquina virtual VMware. Aqui, não teremos vários discos para realizar partições. Centos é semelhante a RHEL (mesma funcionalidade), então veremos as etapas para instalar CENTOS.
1. Comece baixando o CentOS 7.X ISO Imagem no seu sistema Windows local e selecione -a enquanto inicializa a máquina virtual. Selecionar 'Instale o CentOS 7' como mostrado.
 Instale o menu de inicialização do CentOS 7
Instale o menu de inicialização do CentOS 7 2. Selecione os Linguagem, o padrão será Inglês, e clique continuar.
 Selecione CentOS 7 Language
Selecione CentOS 7 Language 3. Seleção de software - Selecione os 'Instalação mínima'e clique'Feito'.
 Seleção de software do CentOS
Seleção de software do CentOS 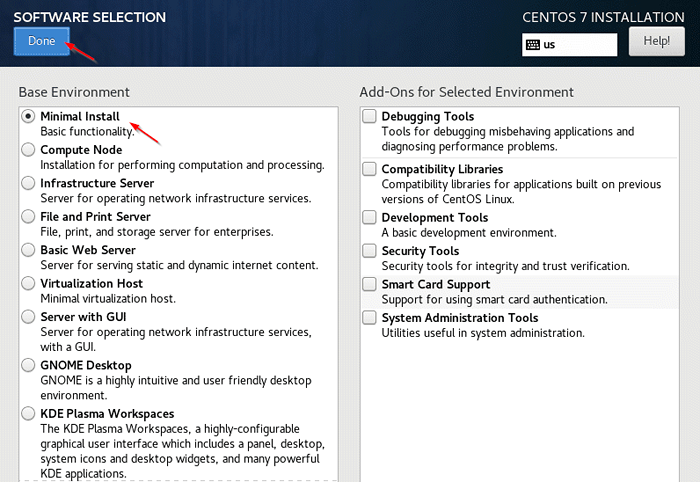 Instalação mínima do CentOS 7
Instalação mínima do CentOS 7 4. Colocou o senha raiz Como isso nos levará a definir.
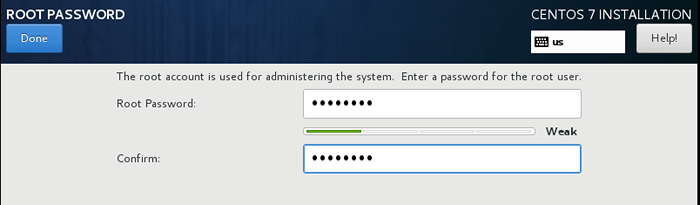 Defina senha raiz
Defina senha raiz 5. Destino de instalação - Este é o passo importante a ser cauteloso. Precisamos selecionar o disco em que o sistema operacional deve ser instalado, o disco dedicado deve ser selecionado para OS. Clique no 'Destino de instalação'E selecione o disco, em tempo real vários discos estarão lá, precisamos selecionar, preferível'SDA'.
 Selecione Destino de Instalação
Selecione Destino de Instalação 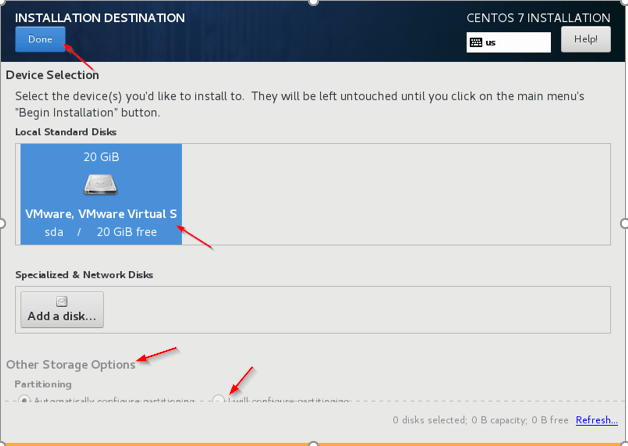 Selecione disco para instalação do CentOS
Selecione disco para instalação do CentOS 6. Outras opções de armazenamento - Escolha a segunda opção (vou configurar o particionamento) para configurar o particionamento relacionado ao sistema operacional como /var, /var/log, /lar, /tmp, /optar, /trocar.
 Particionamento do CentOS manual
Particionamento do CentOS manual 7. Uma vez feito, comece a instalação.
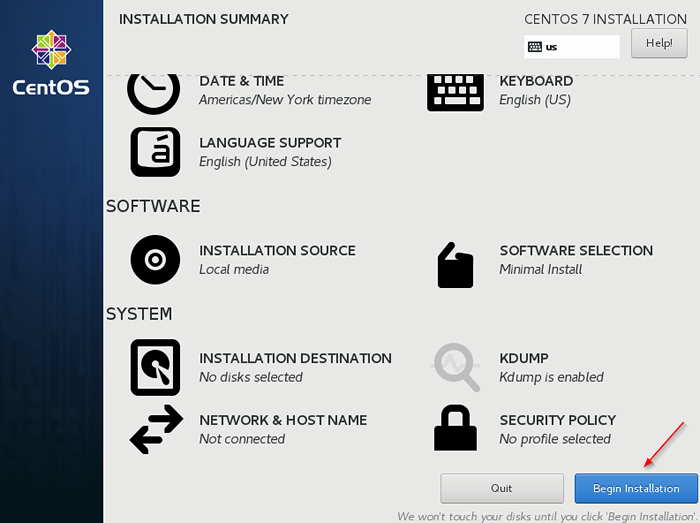 Comece a instalação do CentOS
Comece a instalação do CentOS  Instalação do CentOS 7
Instalação do CentOS 7 8. Depois que a instalação concluir, reinicie o servidor.
 Instalação do CentOS 7 completa
Instalação do CentOS 7 completa 9. Faça login no servidor e defina o nome do host.
# hostnamectl status # hostnamectl set-hostname tecmint # hostnamectl status
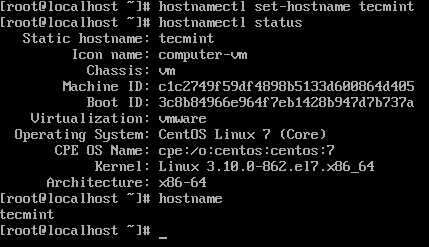 Defina o nome do host no CentOS
Defina o nome do host no CentOS Resumo
Neste artigo, passamos por etapas de instalação do sistema operacional e práticas recomendadas para particionamento do sistema de arquivos. Tudo isso é orientação geral, de acordo com a natureza da carga de trabalho, podemos precisar nos concentrar em mais nuances para alcançar o melhor desempenho do cluster. O planejamento de cluster é arte para o Hadoop administrador. Teremos mergulho profundo nos pré-requisitos do nível do sistema operacional e endurecimento da segurança no próximo artigo.
- « Como dividir a tela Vim horizontal e verticalmente em Linux
- 10 Gateways de API de código aberto e ferramentas de gerenciamento »