

Removendo linhas duplicadas de um arquivo de texto usando a linha de comando Linux
- 2405
- 406
- Arnold Murray
A remoção de linhas duplicadas de um arquivo de texto pode ser feita na linha de comando Linux. Essa tarefa pode ser mais comum e necessária do que você pensa. O cenário mais comum em que isso pode ser útil é com os arquivos de log. Muitas vezes, os arquivos de log repetem as mesmas informações repetidamente, o que torna o arquivo quase impossível de se virar, às vezes tornando os logs inúteis.
Neste guia, mostraremos vários exemplos de linha de comando que você pode usar para excluir linhas duplicadas de um arquivo de texto. Experimente alguns dos comandos em seu próprio sistema e use o que é mais conveniente para o seu cenário.
Neste tutorial, você aprenderá:
- Como remover linhas duplicadas do arquivo ao classificar
- Como contar o número de linhas duplicadas em um arquivo
- Como remover linhas duplicadas sem classificar o arquivo
Vários exemplos para remover linhas duplicadas de um arquivo de texto no Linux | Categoria | Requisitos, convenções ou versão de software usada |
|---|---|
| Sistema | Qualquer distro Linux |
| Programas | Bash Shell |
| Outro | Acesso privilegiado ao seu sistema Linux como raiz ou através do sudo comando. |
| Convenções | # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de sudo comando$ - Requer que os comandos do Linux sejam executados como um usuário não privilegiado regular |
Remova linhas duplicadas do arquivo de texto
Esses exemplos funcionarão em qualquer distribuição do Linux, desde que você esteja usando o shell de bash.
Para o nosso cenário de exemplo, trabalharemos com o seguinte arquivo, que apenas contém os nomes de várias distribuições Linux. Este é um arquivo de texto muito simples para o exemplo, mas na realidade você pode usar esses métodos em documentos que contêm até milhares de linhas repetidas. Veremos como remover todas as duplicatas deste arquivo usando os exemplos abaixo.
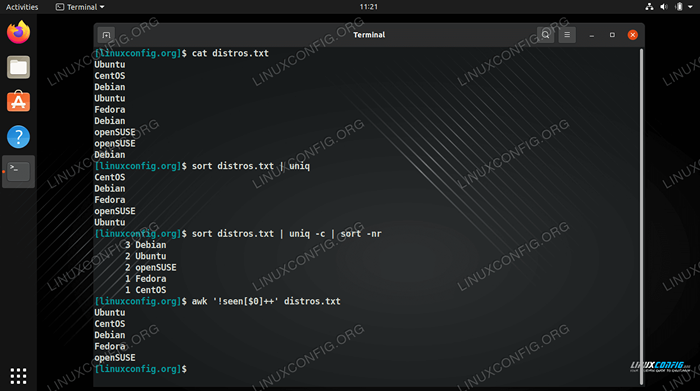
$ CAT distos.txt ubuntu centos debian ubuntu fedora debian openSuse openSuse debian
- O
UniqO comando é capaz de isolar todas as linhas únicas de nosso arquivo, mas isso só funciona se as linhas duplicadas forem adjacentes. Para que as linhas fossem adjacentes, elas primeiro precisariam ser classificadas em ordem alfabética. O comando seguinte funcionaria usandoorganizareUniq.$ distos.txt | UNIQ CENTOS DEBIAN Fedora OpenSuse Ubuntu
Para facilitar as coisas, podemos apenas usar o
-vocêcom classificação para obter o mesmo resultado exato, em vez de tubar -se para o Uniq.
$ Sort -u Distros.TXT CENTOS DEBIAN Fedora OpenSuse Ubuntu
- Para ver quantas ocorrências de cada linha estão no arquivo, podemos usar o
-c(contagem) opção com uniq.$ distos.txt | Uniq -c 1 Centos 3 Debian 1 Fedora 2 OpenSuse 2 Ubuntu
- Para ver as linhas que se repetem com mais frequência, podemos canalizar para outro comando de classificação com o
-n(classificação numérica) e-ropções reversas. Isso nos permite ver rapidamente quais linhas são mais duplicadas no arquivo - outra opção útil para peneirar através de logs.$ distos.txt | uniq -c | classificar -nr 3 Debian 2 Ubuntu 2 OpenSuse 1 Fedora 1 CentOS
- Um problema de usar os comandos anteriores é que confiamos
organizar. Isso significa que nossa saída final é classificada em ordem alfabética ou classificada por quantidade de repetições como no exemplo anterior. Isso pode ser uma coisa boa às vezes, mas e se precisarmos do arquivo de texto para manter seu pedido anterior? Podemos eliminar linhas duplicadas sem classificar o arquivo usando oAwkcomando na seguinte sintaxe.$ awk '!visto [$ 0] ++ 'distos.txt ubuntu centos debian fedora abre
Com este comando, a primeira ocorrência de uma linha é mantida e as linhas duplicadas futuras são descartadas da saída.
- Os exemplos anteriores enviarão saída diretamente para o seu terminal. Se você deseja um novo arquivo de texto com suas linhas duplicadas filtradas, você pode adaptar qualquer um desses exemplos simplesmente usando o
>Operador Bash, como no comando seguinte.$ awk '!visto [$ 0] ++ 'distos.txt> distos-new.TXT
Estes devem ser todos os comandos que você precisa para soltar linhas duplicadas de um arquivo, enquanto opcionalmente classifica ou contando as linhas. Existem mais métodos, mas esses são os mais fáceis de usar e lembrar.
Pensamentos finais
Neste guia, vimos vários exemplo de comando para remover linhas duplicadas de um arquivo de texto no Linux. Você pode aplicar esses comandos a arquivos de log ou qualquer outro tipo de arquivo de texto simples que tenha linhas duplicadas. Também aprendemos a classificar as linhas de um arquivo de texto ou contar o número de duplicatas, pois isso às vezes pode acelerar isolando as informações de que precisamos de um documento.
Tutoriais do Linux relacionados:
- Coisas para instalar no Ubuntu 20.04
- Como melhorar a renderização da fonte do Firefox no Linux
- Uma introdução à automação, ferramentas e técnicas do Linux
- Mastering Bash Script Loops
- Coisas para fazer depois de instalar o Ubuntu 20.04 fossa focal linux
- Comandos Linux: os 20 comandos mais importantes que você precisa para…
- Comandos básicos do Linux
- Como montar a imagem ISO no Linux
- Arquivos de configuração do Linux: os 30 primeiros mais importantes
- Exemplos RSYNC no Linux