

LFCS monitora os processos do Linux Uso e definir limites de processo em uma base por usuário - Parte 14

- 4620
- 783
- Howard Fritsch
Devido a modificações recentes nos objetivos do exame de certificação LFCS eficazes de 2 de fevereiro de 2016, Estamos adicionando os artigos necessários à série LFCS publicada aqui. Para se preparar para este exame, você é fortemente encorajado a passar pela série LFCE também.
Monitore os processos Linux e definir limites de processo por usuário - Parte 14 Todo administrador do sistema Linux precisa saber como verificar a integridade e a disponibilidade de hardware, recursos e processos -chave. Além disso, definir limites de recursos por usuário também deve fazer parte de seu conjunto de habilidades.
Neste artigo, exploraremos algumas maneiras de garantir que o sistema hardware e o software estejam se comportando corretamente para evitar possíveis problemas que possam causar tempo de inatividade inesperado de produção e perda de dinheiro.
Estatísticas dos processadores de relatórios Linux
Com mpstat Você pode visualizar as atividades para cada processador individualmente ou para o sistema como um todo, tanto como um instantâneo único ou dinamicamente.
Para usar esta ferramenta, você precisará instalar Sysstat:
# yum update && yum instalar sysstat [on CENTOS Sistemas baseados] # Aptitutde Atualização && Aptitude Install SysStat [ON Ubuntu Sistemas baseados] # Zypper Update && Zypper Install SysStat [ON OpenSuse sistemas]
Leia mais sobre Sysstat E são utilitários da Learn Sysstat e seus utilitários MPSTAT, PIDSTAT, IOSTAT e SAR em Linux
Depois de instalar mpstat, Use -o para gerar relatórios de estatísticas de processadores.
Mostrar 3 Relatórios globais de utilização da CPU (-você) para todas as CPUs (conforme indicado por -P Todos) em um intervalo de 2 segundos, faça:
# mpstat -p all -u 2 3
Saída de amostra
Linux 3.19.0-32 Generic (Tecmint.com) quarta -feira 30 de março de 2016 _x86_64_ (4 cpu) 11:41:07 IST cpu %usr %nice %sys %iowait %irq %mole %roubo %hóspedes %gire %odie 11:41:09 ist todos 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91 11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53 11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00 11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57 11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56 11:41:09 IST cpu %usr %nice %sys %iowait %irq %mole roube %hóspedes %gnice %ocioso 11:41:11 ist todos os 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66 11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50 11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68 11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50 11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60 11:41:11 IST cpu %usr %nice %sys %iowait %irq %mole %roubo %hóspedes %gire %inativo 11:41:13 ist todos os 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07 11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54 11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75 11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00 11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57 Média: CPU %USR %Nice %Sys %Iowait %IRQ %Soft %roube %do hóspede %GNECE %Idioded Meia: todos os 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89 Média: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87 Média: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78 Média: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35 Média: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
Para ver as mesmas estatísticas para um específico CPU (CPU 0 no exemplo a seguir), use:
# mpstat -p 0 -u 2 3
Saída de amostra
Linux 3.19.0-32 Generic (Tecmint.com) quarta -feira 30 de março de 2016 _x86_64_ (4 cpu) 11:42:08 IST cpu %usr %nice %sys %iowait %irq %mole %roubo %hóspedes %gire %.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50 11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37 11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74 Média: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
A saída dos comandos acima mostra estas colunas:
CPU: Número do processador como um número inteiro ou a palavra tudo como média para todos os processadores.%usr: Porcentagem de utilização da CPU ao executar aplicativos de nível de usuário.%legal: Igual a%usr, Mas com boa prioridade.%sys: Porcentagem de utilização da CPU que ocorreu ao executar aplicativos do kernel. Isso não inclui tempo gasto lidando com interrupções ou hardware de manuseio.%Iowait:. Uma explicação mais detalhada (com exemplos) pode ser encontrada aqui.%IRQ: Porcentagem de tempo gasto em manutenção de interrupções de hardware.%macio: Igual a%IRQ, Mas com interrupções de software.%roubar: Porcentagem de tempo gasto em espera involuntária (roubar ou roubado tempo) quando uma máquina virtual, como convidada, está "ganhando" a atenção do hipervisor enquanto competem pela (s) CPU (s). Este valor deve ser mantido o mais pequeno possível. Um alto valor nesse campo significa que a máquina virtual está paralisando - ou logo será.%convidado: Porcentagem de tempo gasto executando um processador virtual.%parado: porcentagem de tempo em que as CPUs não estavam executando nenhuma tarefa. Se você observar um valor baixo nesta coluna, isso é uma indicação do sistema sendo colocado sob uma carga pesada. Nesse caso, você precisará examinar mais de perto a lista de processos, como discutiremos em um minuto, para determinar o que está causando.
Para colocar o local em uma carga um tanto alta, execute os seguintes comandos e execute o MPSTAT (conforme indicado) em um terminal separado:
# dd if =/dev/zero de = teste.iso bs = contagem 1g = 1 # mpstat -u -p 0 2 3 # ping -f localhost # interrompa com ctrl + c após o mpstat abaixo completa # mpstat -u -p 0 2 3
Finalmente, compare com a saída de mpstat sob circunstâncias normais:
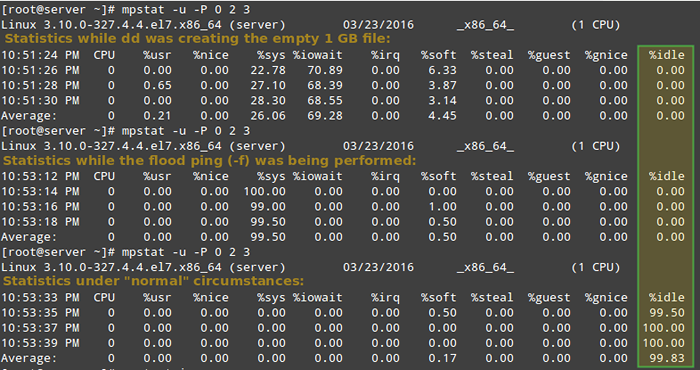 Relatar estatísticas relacionadas aos processadores Linux
Relatar estatísticas relacionadas aos processadores Linux Como você pode ver na imagem acima, CPU 0 estava sob uma carga pesada durante os dois primeiros exemplos, conforme indicado pelo %parado coluna.
Na próxima seção, discutiremos como identificar esses processos famintos de recursos, como obter mais informações sobre eles e como tomar as medidas apropriadas.
Relatando processos Linux
Para listar processos classificando -os por uso da CPU, usaremos o bem conhecido ps comando com o -EO (para selecionar todos os processos com formato definido pelo usuário) e --organizar (para especificar uma ordem de classificação personalizada) As opções, assim:
# ps -eo pid, ppid, cmd,%cpu,%mem - -sort = -%cpu
O comando acima só mostrará o PID, PPID, O comando associado ao processo e a porcentagem de uso de CPU e RAM classificada pela porcentagem de uso da CPU em ordem decrescente. Quando executado durante a criação do .ISO Arquivo, aqui estão as primeiras linhas da saída:
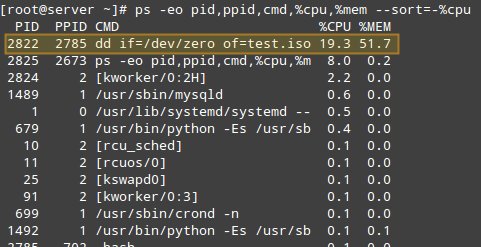 Encontre processos Linux pelo uso da CPU
Encontre processos Linux pelo uso da CPU Uma vez que identificamos um processo de interesse (como aquele com PID = 2822), podemos navegar para /proc/pid (/Proc/2822 neste caso) e faça uma listagem de diretórios.
Este diretório é onde vários arquivos e subdiretórios com informações detalhadas sobre esse processo em particular são mantidas enquanto está sendo executado.
Por exemplo:
/proc/2822/ioContém estatísticas de IO para o processo (número de caracteres e bytes lidos e escritos, entre outros, durante operações de IO)./proc/2822/att/correntemostra os atributos atuais de segurança do Selinux do processo./proc/2822/cGrupDescreve os grupos de controle (CGROUPS para abreviar) ao qual o processo pertence se a opção de configuração do kernel config_cgroups estiver ativada, com a qual você pode verificar:
# Cat /Boot /Config -$ (uname -r) | Grep -i cGRoups
Se a opção estiver ativada, você deverá ver:
Config_cgroups = y
Usando CGROUPS Você pode gerenciar a quantidade de uso de recursos permitido por processo, conforme explicado nos capítulos 1 a 4 do Guia de Gerenciamento de Recursos Red Hat Enterprise Linux 7, no Capítulo 9 do Guia de Análise e Tuning do Sistema OpenSUSE, e nos grupos de controle Seção do Ubuntu 14.04 Documentação do servidor.
O /proc/2822/fd é um diretório que contém um link simbólico para cada descritor de arquivo que o processo abriu. A imagem a seguir mostra essas informações para o processo iniciado em TTY1 (o primeiro terminal) para criar o .ISO imagem:
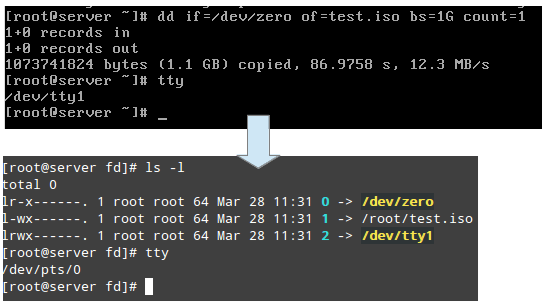 Encontre informações do processo Linux
Encontre informações do processo Linux A imagem acima mostra que stdin (Descritor de arquivo 0), stdout (Descritor de arquivo 1), e stderr (Descritor de arquivo 2) são mapeados para /dev/zero, /raiz/teste.ISO, e /dev/tty1, respectivamente.
Mais informações sobre /Proc pode ser encontrado em “o /Proc FileSystem ”Documento mantido e mantido pelo kernel.org e no manual do programador Linux.
Definir limites de recursos por usuário no Linux
Se você não tiver cuidado e permitir que qualquer usuário execute um número ilimitado de processos, pode eventualmente experimentar um desligamento inesperado do sistema ou ser travado à medida que o sistema entra em um estado inutilizável. Para evitar que isso aconteça, você deve colocar um limite para o número de processos que os usuários podem começar.
Para fazer isso, edite /etc/segurança/limites.conf e adicione a seguinte linha na parte inferior do arquivo para definir o limite:
* Hard NProc 10
O primeiro campo pode ser usado para indicar um usuário, um grupo ou todos eles (*), enquanto o segundo campo aplica um limite rígido para o número de processo (NPROC) para 10. Para aplicar mudanças, o registro e o retorno é suficiente.
Assim, vamos ver o que acontece se um certo usuário que não. Se não tivéssemos implementado limites, isso iniciaria inicialmente duas instâncias de uma função e depois duplicaria cada um deles em um loop sem fim. Assim, acabaria levando seu sistema a um rastreamento.
No entanto, com a restrição acima, a bomba de garfo não é bem -sucedida, mas o usuário ainda será bloqueado até que o administrador do sistema mate o processo associado a ele:
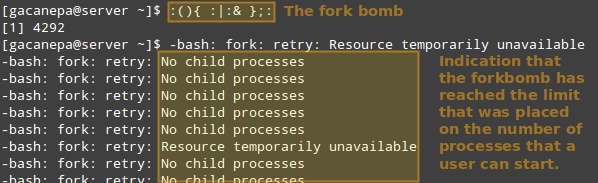 Executar a Bomba de Fork
Executar a Bomba de Fork DICA: Outras possíveis restrições tornadas possíveis por ulimit estão documentados no limites.conf arquivo.
Linux Outras ferramentas de gerenciamento de processos
Além das ferramentas discutidas anteriormente, um administrador do sistema também pode precisar:
a) Modificar a prioridade de execução (uso de recursos do sistema) de um processo usando Renice. Isso significa que o kernel alocará mais ou menos recursos do sistema ao processo com base na prioridade atribuída (um número comumente conhecido como “gentileza”Em um intervalo de -20 para 19).
Quanto menor o valor, maior a prioridade da execução. Usuários regulares (exceto root) podem apenas modificar a gentileza dos processos que possuem em um valor mais alto (o que significa uma prioridade de execução mais baixa), enquanto a raiz pode modificar esse valor para qualquer processo e pode aumentá -lo ou diminuí -lo.
A sintaxe básica de Renice é a seguinte:
# Renice [-n] Identificador
Se o argumento após o novo valor de prioridade não estiver presente (vazio), ele será definido como PID por padrão. Nesse caso, a gentileza do processo com Pid = identificador está configurado para .
b) Interromper a execução normal de um processo quando necessário. Isso é comumente conhecido como "matar" o processo. Sob o capô, isso significa enviar ao processo um sinal para concluir sua execução corretamente e liberar quaisquer recursos usados de maneira ordenada.
Para matar um processo, use o matar Comando o seguinte:
# mate pid
Como alternativa, você pode usar o PKILL para encerrar todos os processos de um determinado proprietário (-você), ou proprietário de um grupo (-G), ou mesmo aqueles processos que têm um PPID em comum (-P). Essas opções podem ser seguidas pela representação numérica ou pelo nome real como identificador:
# pkill [options] identificador
Por exemplo,
# pkill -g 1000
matará todos os processos de propriedade de grupo com GID = 1000.
E,
# pkill -p 4993
matará todos os processos cujo PPID é 4993.
Antes de executar um pkill, É uma boa ideia testar os resultados com PGREP Primeiro, talvez usando o -eu opção também para listar os nomes dos processos. São necessárias as mesmas opções, mas apenas retorna os PIDs de processos (sem tomar mais ações) que seriam mortos se pkill é usado.
# pgrep -l -u gacanepa
Isso é ilustrado na próxima imagem:
 Encontre processos de execução do usuário no Linux
Encontre processos de execução do usuário no Linux Resumo
Neste artigo, exploramos algumas maneiras de monitorar o uso de recursos para verificar a integridade e a disponibilidade de componentes críticos de hardware e software em um sistema Linux.
Também aprendemos a tomar as medidas apropriadas (seja ajustando a prioridade de execução de um determinado processo ou encerrando -o) em circunstâncias incomuns.
Esperamos que os conceitos explicados neste tutorial tenham sido úteis. Se você tiver alguma dúvida ou comentário, sinta -se à vontade para entrar em contato usando o formulário de contato abaixo.
Torne -se um administrador de sistema certificado Linux- « Como alterar os parâmetros de tempo de execução do kernel de uma maneira persistente e não persistente
- LFCs Como explorar o Linux com documentações e ferramentas de ajuda instalada - Parte 12 »