

Introdução

- 4368
- 1326
- Loren Botsford
31 de julho de 2009
Por Pierre Vignéras
Abstrato:
Como você provavelmente deve saber, o Linux suporta vários sistemas de arquivos, como ext2, ext3, ext4, xfs, reiserfs, jfs, entre outros. Poucos usuários realmente consideram esta parte de um sistema, selecionando opções padrão do instalador de sua distribuição. Neste artigo, darei alguns motivos para uma melhor consideração do sistema de arquivos e de seu layout. Vou sugerir um processo de fundo superior para o design de um layout "inteligente" que permanece o mais estável possível ao longo do tempo para um determinado uso do computador.Introdução
A primeira pergunta que você pode fazer é por que existem tantos sistemas de arquivos e quais são suas diferenças, se houver? Para diminuir (consulte a Wikipedia para obter detalhes):
- Ext2: é o Linux FS, quero dizer, aquele que foi projetado especificamente para Linux (influenciado por EXT e Berkeley FFS). Pro: rápido; Contras: não diário (FSCK longo).
- ext3: a extensão natural ext2. Pro: compatível com ext2, diário; Contras: mais lento que o ext2, como tantos concorrentes, obsoletos hoje.
- ext4: a última extensão da família Ext. Pro: compatibilidade ascendente com ext3, tamanho grande; bom desempenho de leitura; Contras: um pouco recente demais para saber?
- JFS: IBM AIX FS portado para Linux. Pro: maduro, rápido, leve e confiável, tamanho grande; Contras: ainda desenvolvido?
- XFS: SGI IRIX FS portado para Linux. Pro: muito maduro e confiável, bom desempenho médio, tamanho grande, muitas ferramentas (como um desfragmentador); Contras: nenhum tanto quanto eu sei.
- Reiserfs: alternativa ao sistema de arquivo ext2/3 no Linux. Pro: rápido para arquivos pequenos; Contras: ainda desenvolvido?
Existem outros sistemas de arquivos, em particular novos, como BTRFs, ZFs e Nilfs2, que podem parecer muito interessantes também. Vamos lidar com eles mais tarde neste artigo.
Então agora a pergunta é: qual sistema de arquivo é o mais adequado para sua situação específica? A resposta não é simples. Mas se você realmente não souber, se tiver alguma dúvida, eu recomendaria o XFS por vários motivos:
- Ele tem um desempenho muito bom em geral e particularmente em leitura/gravação simultânea (consulte a referência);
- É muito maduro e, portanto, foi testado e sintonizado extensivamente;
- Acima de tudo, ele vem com ótimos recursos, como o XFS_FSR, um desfragmentador fácil de usar (basta fazer um ln -sf $ (que xfs_fsr) /etc /cron.diariamente/desfrag e esqueça).
O único problema que vejo com o XFS é que você não pode reduzir um XFS FS. Você pode cultivar uma partição XFS mesmo quando montada e em uso ativo (Grow a quente), mas não pode reduzir seu tamanho. Portanto, se você tiver algumas necessidades de sistema de arquivo redutoras, escolha outro sistema de arquivos, como ext2/3/4 ou reiserfs (até onde eu sei que você não pode redirugue a quente nem ext3 nem os sistemas de arquivo de reiserfs). Outra opção é manter o XFS e sempre começar com o tamanho de partição pequeno (como você sempre pode crescer a quente depois).
Se você possui um computador de baixo perfil (ou servidor de arquivos) e se você realmente precisar da sua CPU para outra coisa do que lidar com operações de entrada/saída, sugiro JFS.
Se você tiver muitos diretórios ou/e arquivos pequenos, o Reiserfs pode ser uma opção.
Se você precisar de desempenho a todo custo, sugiro ext2.
Honestamente, não vejo nenhum motivo para escolher o ext3/4 (desempenho? realmente?).
Isso é para escolha de sistema de arquivo. Mas então, a outra pergunta é qual layout devo usar? Duas partições? Três? Dedicado /home /? Somente leitura /? Separado /tmp?
Obviamente, não há resposta única para esta pergunta. Muitos fatores devem ser considerados para fazer uma boa escolha. Vou primeiro definir esses fatores:
- Complexidade: Quão complexo o layout é globalmente;
- Flexibilidade: Como é fácil alterar o layout;
- Desempenho: quão rápido o layout permite que o sistema seja executado.
Encontrar o layout perfeito é uma troca entre esses fatores.
Layout padrão
Freqüentemente, um usuário final de desktop com poucos conhecimentos do Linux segue as configurações padrão de sua distribuição, onde (geralmente) apenas duas ou três partições são feitas para Linux, com o sistema de arquivo root ' /', /Boot e a troca. Vantagens dessa configuração é a simplicidade. O principal problema é que esse layout não é flexível nem performante.
Falta de flexibilidade
A falta de flexibilidade é óbvia por muitos motivos. Primeiro, se o usuário final quiser outro layout (por exemplo, ele deseja redimensionar o sistema de arquivo root ou ele deseja usar um sistema de arquivo separado /TMP), ele terá que reiniciar o sistema e usar um software de partição (de um viveiro, por exemplo). Ele terá que cuidar de seus dados, já que a re-partição é uma operação de força bruta que o sistema operacional não está ciente.
Além disso, se o usuário final quiser adicionar algum armazenamento (por exemplo, um novo disco rígido), ele acabará modificando o layout do sistema (/etc/fstab) e depois de algum tempo, seu sistema dependerá apenas do layout de armazenamento subjacente (Número e localização de discos rígidos, partições e assim por diante).
A propósito, ter partições separadas para seus dados (/casa, mas também para todo o áudio, vídeo, banco de dados,…) facilita muito a mudança do sistema (por exemplo, de uma distribuição Linux para outra). Isso também torna o compartilhamento de dados entre sistemas operacionais (BSD, OpenSolaris, Linux e até Windows) mais fácil e mais seguro. mas essa é outra história.
Uma boa opção é usar o gerenciamento de volume lógico (LVM). LVM resolve o problema de flexibilidade de uma maneira muito agradável, como veremos. A boa notícia é que a maioria das distribuições modernas suporta o LVM e algumas o usam por padrão. O LVM adiciona uma camada de abstração na parte superior da remoção de hardware de dependências difíceis entre o sistema operacional (/etc/fstab) e os dispositivos de armazenamento subjacentes (/dev/hda,/dev/sda e outros). Isso significa que você pode alterar o layout do armazenamento - adicionando e removendo discos rígidos - sem perturbar seu sistema. O principal problema do LVM, até onde eu sei, é que você pode ter problemas para ler um volume LVM de outros sistemas operacionais.
Falta de desempenho.
Qualquer que seja o sistema de arquivos (ext2/3/4, xfs, reiserfs, jfs), não é perfeito para todo tipo de dados e padrões de uso (também conhecidos como carga de trabalho). Por exemplo, o XFS é conhecido por ser bom no manuseio de arquivos grandes, como arquivos de vídeo. Por outro lado, o Reiserfs é conhecido por ser eficiente no manuseio de arquivos pequenos (como arquivos de configuração no seu diretório inicial ou em /etc). Portanto, ter um sistema de arquivo para todo tipo de dados e uso definitivamente não é ideal. O único ponto bom com esse layout é que o kernel não precisa suportar muitos sistemas de arquivos diferentes; portanto, reduz a quantidade de memória que o kernel usa ao seu mínimo nu (isso também é verdadeiro com módulos). Mas, a menos que nos concentramos em sistemas incorporados, considero esse argumento irrelevante com os computadores de hoje.
Escolhendo a coisa certa: uma abordagem de fundo superior
Freqüentemente, quando um sistema é projetado, geralmente é feito em uma abordagem de baixo para cima: o hardware é comprado de acordo com os critérios que não estão relacionados ao seu uso. Depois disso, um layout do sistema de arquivos é definido de acordo com esse hardware: “Eu tenho um disco, posso participar dessa maneira, essa partição aparecerá lá, que outro lá, e assim por diante”.
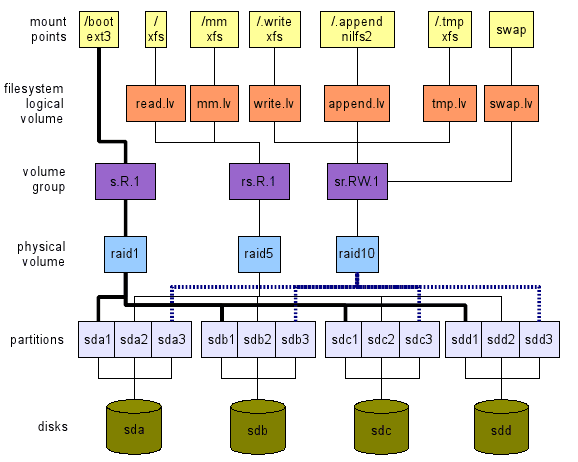
Eu proponho a abordagem reversa. Definimos o que queremos em um nível alto. Em seguida, viajamos camadas de cima para baixo, para os dispositivos reais de hardware - de armazenamento em nosso caso - como mostrado na Figura 1. Esta ilustração é apenas um exemplo do que pode ser feito. Existem muitas opções como veremos. As próximas seções explicarão como podemos chegar a um layout global.
figura 1: Um exemplo de um layout do sistema de arquivo. Observe que duas partições permanecem livres (SDB3 e SDC3). Eles podem ser usados para /bota, para a troca ou ambos. Não "copie/cole" este layout. Não é otimizado para sua carga de trabalho. É apenas um exemplo.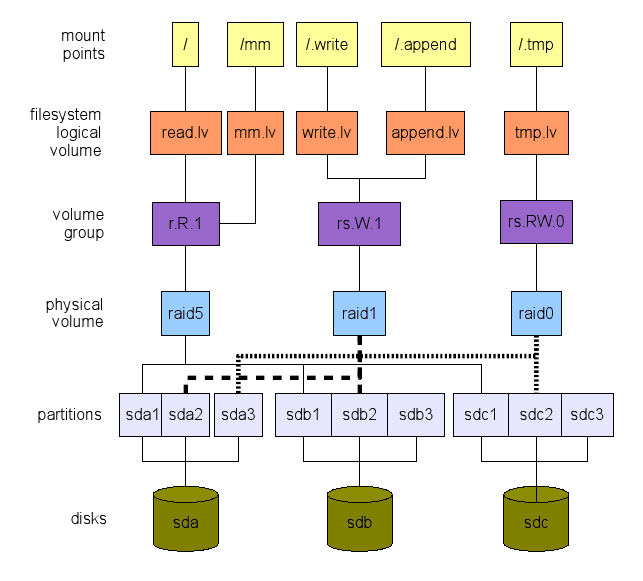
Comprando o hardware certo
Antes de instalar um novo sistema, o uso de destino deve ser considerado. Primeiro de um ponto de vista de hardware. É um sistema incorporado, um desktop, um servidor, um computador multiusuário para todos os fins (com TV/Audio/Video/OpenOffice/Web/Chat/P2P,…)?
Como exemplo, eu sempre recomendo os usuários finais com necessidades simples de desktop (web, correio, bate-papo, poucas mídias) para comprar um processador de baixo custo (o mais barato), bastante RAM (o máximo) e pelo menos dois discos rígidos.
Atualmente, até o processador mais barato é longe o suficiente para surfar na web e assistir a filmes. Muita RAM oferece um bom cache (o Linux usa memória livre para armazenamento em cache - reduzindo a quantidade de entrada/saída dispendiosa para dispositivos de armazenamento). A propósito, a compra da quantidade máxima de RAM que sua placa -mãe pode apoiar é um investimento por dois motivos:
- Os aplicativos tendem a exigir mais e mais memória; Portanto, ter a quantidade máxima de memória já impede que você adicione memória mais tarde por um tempo;
- A tecnologia muda tão rapidamente que seu sistema pode não suportar a memória disponível em 5 anos. Naquela época, a compra de memória antiga provavelmente será muito cara.
Ter dois discos rígidos permite que eles sejam usados no espelho. Portanto, se um falhar, o sistema continuará a trabalhar normalmente e você terá tempo para obter um novo disco rígido. Dessa forma, seu sistema permanecerá disponível e seus dados, bastante seguros (isso não é suficiente, faça backup de seus dados também).
Definindo padrão de uso
Ao escolher hardware e, especificamente, o layout do sistema de arquivos, você deve considerar aplicativos que o usarão. Aplicações diferentes têm carga de trabalho de entrada/saída diferente. Considere as seguintes aplicações: Madeiras (syslog), leitores de correio (Thunderbird, Kmail), mecanismo de pesquisa (Beagle), banco de dados (MySQL, PostgreSQL), P2P (Emule, Gnutella, Vuze), Shells (Bash)… você pode ver sua entrada /padrões de saída e quanto eles diferem?
Portanto, defino o seguinte local de armazenamento abstrato conhecido como volume lógico - LV - na terminologia LVM:
- TMP.LV:
- Para dados temporários como o encontrado em/tmp,/var/tmp e também no diretório inicial de cada usuários $ home/tmp (observe que diretórios de lixo como $ home/lixo, $ home/.O lixo também pode ser mapeado aqui. Consulte a especificação do lixo Freedesktop para obter implicações). Outro candidato é /var /cache. A idéia para esse volume lógico é que possamos ajustá-la demais para o desempenho e podemos aceitar um pouco a perda de dados, pois esses dados não são essenciais para o sistema (consulte o padrão de hierarquia do sistema de arquivo Linux (FHS) para obter detalhes sobre esses locais).
- ler.LV:
- Para dados que são lidos principalmente como para a maioria dos arquivos binários em /bin, /usr /bin, /lib, /usr /lib, arquivos de configuração em /etc e a maioria dos arquivos de configuração em cada diretório de usuário $ home /.Bashrc, e assim por diante. Este local de armazenamento pode ser ajustado para o desempenho da leitura. Podemos aceitar um desempenho ruim de gravação, pois eles ocorrem em ocasiões raras (e.G: Ao atualizar o sistema). Perder dados aqui é claramente inaceitável.
- escrever.LV:
- Para dados que são escritos principalmente de maneira aleatória, como dados escritos por aplicativos P2P ou bancos de dados. Podemos sintonizá -lo para gravar desempenho. Observe que o desempenho de leitura não pode ser muito baixo: os aplicativos P2P e do banco de dados lidos aleatoriamente e muitas vezes os dados que eles escrevem. Podemos considerar esse local como o local "para todos os fins": se você realmente não conhece o padrão de uso de um determinado aplicativo, configure-o para que ele use esse volume lógico. Perder dados aqui também é inaceitável.
- acrescentar.LV:
- Para dados que são escritos principalmente de maneira seqüencial, como para a maioria dos arquivos em/var/log e também $ home/.XSession-Errors, entre outros. Podemos ajustá -lo para o desempenho de anexar, que pode ser bem diferente do desempenho de gravação aleatória. Lá, o desempenho de leitura geralmente não é tão importante (a menos que você tenha necessidades específicas, é claro). A perda de dados aqui é inaceitável para usos normais (o log fornece informações sobre problemas. Se você perder seus troncos, como você pode saber qual foi o problema?).
- milímetros.LV:
- para arquivos multimídia; O caso deles é um pouco especial, pois eles geralmente são grandes (vídeo) e lidos sequencialmente. A ajuste para leitura seqüencial pode ser feita aqui. Os arquivos multimídia são escritos uma vez (por exemplo, da gravação.LV onde os aplicativos P2P escrevem para o MM.lv) e leia muitas vezes sequencialmente.
Você pode adicionar/sugerir outras categorias aqui com padrões diferentes, como sequencial.ler.LV, por exemplo.
Definindo pontos de montagem
Suponhamos que já tenhamos todos esses locais abstratos de armazenamento na forma de/dev/tbd/lv onde:
- TBD é um grupo de volume a ser definido mais tarde (ver 3.5);
- LV é um dos volumes lógicos que acabamos de definir na seção anterior (leia.LV, TMP.LV,…).
Então, supomos que já temos/dev/tbd/tmp.lv,/dev/tbd/leitura.lv,/dev/tbd/write.LV, e assim por diante.
A propósito, consideramos que cada grupo de volume é otimizado para seu padrão de uso (uma troca foi encontrada entre desempenho e flexibilidade).
Dados temporários: TMP.lv
Gostaríamos de ter/tmp,/var/tmp, e qualquer $ home/tmp todos mapeados para/dev/tbd/tmp.lv.
O que eu sugiro é o seguinte:
- montagem/dev/tbd/tmp.LV para A /.Diretório oculto do TMP no nível raiz; Em /etc /fstab, você terá algo assim (é claro, uma vez que o grupo de volume é desconhecido, isso não funcionará; o objetivo é explicar o processo aqui.):
# Substitua o Auto pelo sistema de arquivo real se desejar # substituir padrões 0 2 por suas próprias necessidades (homem fstab)/dev/tbd/tmp.lv /.Padrões automáticos de TMP 0 2
- vincular outros locais ao diretório em /.TMP. Por exemplo, suponha que você não se importe com diretórios separados para /tmp e /var /tmp (consulte FHS para implicações), você pode apenas criar um diretório ALL_TMP dentro /dev /tbd /tmp.LV e ligá -lo a ambos /tmp e /var /tmp. Em /etc /fstab, adicione essas linhas:
/.tmp /all_tmp /tmp nenhum liga 0 0 /.tmp/all_tmp/var/tmp nenhum liga 0 0
Claro que se você prefere se conformar ao FHS, não há problema. Crie dois diretórios distintos FHS_TMP e FHS_VAR_TMP no TMP.Volume do LV e adicione essas linhas:
/.tmp /fhs_tmp /tmp nenhum liga 0 0 /.tmp/fhs_var_tmp/var/tmp nenhum liga 0 0
- Faça um link simulado para o diretório TMP do usuário para /tmp /usuário. Por exemplo, $ home/tmp é um link simbólico para/tmp/$ user_name/tmp (estou usando o ambiente KDE, portanto, meu $ home/tmp é um link simbólico para/tmp/kde- $ user para que todos os aplicativos KDE use o mesmo LV). Você pode automatizar esse processo usando algumas linhas em seu .Bash_profile (ou mesmo no/etc/skel/.Bash_profile para que qualquer novo usuário o tenha). Por exemplo:
se teste ! -e $ home/tmp -a ! -e /tmp /kde- $ user; então mkdir /tmp /kde- $ user; ln -s/tmp/kde- $ usuário $ home/tmp; fi
(Este script é bastante simples e só funciona no caso em que $ home/tmp e/tmp/kde- $ user ainda não existe. Você pode adaptá -lo à sua própria necessidade.)
Leia principalmente dados: leia.lv
Como o sistema de arquivo raiz contém /etc, /bin, /usr /bin e assim por diante, eles são perfeitos para leitura.lv. Portanto, em /etc /fstab, eu colocaria o seguinte:
/dev/tbd/leitura.Padrões de LV / Auto
Para arquivos de configuração nos diretórios residenciais do usuário, as coisas não são tão simples quanto você pode imaginar. Pode -se tentar usar a variável de ambiente xdg_config_home (consulte Freedesktop)
Mas eu não recomendaria esta solução por dois motivos. Primeiro, poucos aplicativos realmente estão em conformidade com isso hoje em dia (o local padrão é $ home/.configurar quando não está definido explicitamente). Segundo, é se você definir xdg_config_home para uma leitura.Sub-diretório de LV, os usuários finais terão problemas para encontrar seus arquivos de configuração. Portanto, para esse caso, não tenho nenhuma boa solução e farei diretórios domésticos e todos os arquivos de configuração armazenados na gravação geral.Localização do VE.
Dados escritos principalmente: escrever.lv
Para esse caso, vou reproduzir de alguma maneira o padrão usado para TMP.lv. Vou vincular diretórios diferentes para diferentes aplicações. Por exemplo, terei no FSTAB algo semelhante a isso:
/dev/tbd/write.lv /.Escreva padrões automáticos 0 2 /.Escreva /dB /dB Nenhum vínculo 0 0 /.Write /p2p /p2p nenhum liga 0 0 /.Escreva /Home /Home Nenhum Bind 0 0
Obviamente, suponha que os diretórios de banco de dados e P2P tenham sido criados em Write.lv.
Observe que você pode ter que estar ciente do acesso aos direitos. Uma opção é fornecer os mesmos direitos do que para /tmp, onde qualquer um pode escrever /ler seus próprios dados. Isso é conseguido pelo seguinte comando Linux, por exemplo: chmod 1777 /p2p.
Anexar principalmente dados: anexar.lv
Esse volume foi ajustado para aplicativos de estilo de madeireiros, como syslog (e suas variantes syslog_ng, por exemplo) e quaisquer outros madeireiros (Java Loggers, por exemplo). O /etc /fstab deve ser semelhante a este:
/dev/tbd/anexo.lv /.Anexar padrões automáticos 0 2 /.Anexar /syslog /var /log nenhum lige 0 0 /.Anexar/ulog/var/uLOG Nenhum vínculo 0 0
Novamente, Syslog e ULOG são diretórios criados anteriormente para append.lv.
Dados multimídia: mm.lv
Para arquivos multimídia, acabei de adicionar a seguinte linha:
/dev/tbd/mm.Padrões automáticos LV /mm
Dentro /mm, eu crio fotos, áudios e vídeos diretórios. Como usuário de desktop, geralmente compartilho meus arquivos multimídia com outros membros da família. Portanto, os direitos de acesso devem ser projetados corretamente.
Você pode preferir ter volumes distintos para arquivos de fotos, áudio e vídeo. Sinta -se à vontade para criar volumes lógicos de acordo: fotos.LV, Audios.LV e vídeos.lv.
Outros
Você pode adicionar seus próprios volumes lógicos de acordo com sua necessidade. Os volumes lógicos são bastante livres para lidar com. Eles não adicionam uma grande sobrecarga e fornecem muita flexibilidade, ajudando você a aproveitar ao máximo o seu sistema, principalmente ao escolher o sistema de arquivo certo para sua carga de trabalho.
Definindo sistemas de arquivos para volumes lógicos
Agora que nossos pontos de montagem e nossos volumes lógicos foram definidos de acordo com nossos padrões de uso de aplicativos, podemos escolher o sistema de arquivos para cada volume lógico. E aqui temos muitas opções como já vimos. Primeiro de tudo, você tem o próprio sistema de arquivo (e.G: ext2, ext3, ext4, reiserfs, xfs, jfs e assim por diante). Para cada um deles, você também tem seus parâmetros de ajuste (como o tamanho do bloco de ajuste, número de inodos, opções de log (xfs) e assim por diante). Finalmente, ao montar, você também pode especificar diferentes opções de acordo com algum padrão de uso (noatime, dados = writeback (ext3), barreira (xfs) e assim por diante). A documentação do sistema de arquivo deve ser lida e compreendida para que você possa mapear as opções para o padrão de uso correto. Se você não tem idéia de qual FS usar para qual finalidade, aqui estão minhas sugestões:
- TMP.LV:
- Este volume conterá muitos tipos de dados, escritos/lidos por aplicativos e usuários, pequenos e grandes. Sem nenhum padrão de uso definido (principalmente lido, principalmente escrito), eu usaria um sistema de arquivo genérico, como XFS ou ext4.
- ler.LV:
- Este volume contém o sistema de arquivo raiz com muitos binários (/bin,/usr/bin), bibliotecas (/lib,/usr/lib), muitos arquivos de configurações (/etc) ... Como a maioria de seus dados é lida, o arquivo -System pode ser aquele com o melhor desempenho de leitura, mesmo que seu desempenho de gravação seja ruim. XFS ou EXT4 são opções aqui.
- escrever.LV:
- Isso é bastante difícil, pois este local é o ”ajuste tudo”Localização, ele deve lidar com a leitura e a gravação corretamente. Novamente, xfs ou ext4 também são opções.
- acrescentar.LV:
- Lá, podemos escolher um sistema de arquivo estruturado de log puro, como o novo Nilfs2 suportado pelo Linux desde 2.6.30, que deve fornecer um desempenho muito bom de gravação (mas cuidado com suas limitações (especialmente sem suporte para atime, atributos estendidos e ACL).
- milímetros.LV:
- contém arquivos de áudio/vídeo que podem ser muito grandes. Esta é uma escolha perfeita para XFS. Observe que no IRIX, o XFS suporta uma seção em tempo real para aplicações multimídia. Isso não é suportado (ainda?) em Linux até onde eu sei.
- Você pode brincar com os parâmetros de ajuste do XFS (consulte o Man XFS), mas requer algum bom conhecimento sobre seu padrão de uso e no XFS Internals.
Nesse alto nível, você também pode decidir se precisa de suporte de criptografia ou compactação. Isso pode ajudar na escolha do sistema de arquivos. Por exemplo, para mm.LV, a compressão é inútil (como os dados multimídia já estão compactados), enquanto pode parecer útil para /casa. Considere também se você precisar de criptografia.
Nessa etapa, escolhemos os sistemas de arquivos para todos os nossos volumes lógicos. A hora é agora descer para a próxima camada e definir nossos grupos de volume.
Grupo de Volume Definindo (VG)
O próximo passo é definir grupos de volume. Nesse nível, definiremos nossas necessidades em termos de ajuste de desempenho e tolerância a falhas. Proponho a definição de VGs de acordo com o seguinte esquema: [r | s].[R | w].[n] Onde:
- 'r' - significa aleatório;
- 'S' - significa sequencial;
- 'R' - significa ler;
- 'C' - significa escrever;
- 'n' - é um número inteiro positivo, zero inclusivo.
Cartas determinam o tipo de otimização que o volume nomeado foi ajustado para. O número fornece uma representação abstrata do nível de tolerância a falhas. Por exemplo:
- r.R.0 significa otimizado para leitura aleatória com um nível de tolerância a falhas de 0: a perda de dados ocorre assim que um dispositivo de armazenamento falha (dito o contrário, o sistema é tolerante a 0 falha no dispositivo de armazenamento).
- s.C.2 significa otimizado para gravação seqüencial com um nível de tolerância a falhas de 2: a perda de dados ocorre assim que três dispositivos de armazenamento falham (dito o contrário, o sistema é tolerante a 2 falhas de dispositivos de armazenamento).
Temos então que mapear cada volume lógico para um determinado grupo de volume. Eu sugiro o seguinte:
- TMP.LV:
- pode ser mapeado para um RS.Rw.0 grupo de volume ou um RS.Rw.1 dependendo de seus requisitos relativos à tolerância a falhas. Obviamente, se o seu desejo é que seu sistema permaneça on-line por 24 horas por dia, 7 dias por semana, 365 dias/ano, a segunda opção deve ser definitivamente considerada. Infelizmente, a tolerância de falhas tem um custo em termos de espaço de armazenamento e desempenho. Portanto, você não deve esperar o mesmo nível de desempenho de um RS.Rw.0 VG e um RS.Rw.1 VG com o mesmo número de dispositivos de armazenamento. Mas se você puder pagar os preços, existem soluções para Rs de execução bastante.Rw.1 e até Rs.Rw.2, 3 e mais! Mais sobre isso no próximo nível.
- ler.LV:
- pode ser mapeado para um r.R.1 VG (aumentar o número tolerante a falhas, se você precisar);
- escrever.LV:
- pode ser mapeado para um r.C.1 VG (a mesma coisa);
- acrescentar.LV:
- pode ser mapeado para um s.C.1 VG;
- milímetros.LV:
- pode ser mapeado para um s.R.1 vg.
Obviamente, temos uma declaração 'maio' e não uma 'deve', pois depende do número de dispositivos de armazenamento que você pode colocar na equação. Definir VG é realmente muito difícil, pois você nem sempre pode abstrair completamente o hardware subjacente. Mas acredito que definir seus requisitos primeiro pode ajudar a definir o layout do seu sistema de armazenamento globalmente.
Veremos no próximo nível, como implementar esses grupos de volume.
Definindo volumes físicos (PV)
Esse nível é onde você implementa um determinado requisito de grupo de volume (definido usando a notação Rs.Rw.n descrito acima). Felizmente, não há - até onde eu sei - muitas maneiras de implementar um requisito de VG. Você pode usar alguns dos recursos LVM (espelhamento, decapagem), RAID de software (com Linux MD) ou RAID de hardware. A escolha depende de suas necessidades e do seu hardware. No entanto, eu não recomendaria o RAID de hardware (hoje em dia) para um computador de mesa ou mesmo um pequeno servidor de arquivos, por dois motivos:
- Muitas vezes (na maioria das vezes, na verdade), o que é chamado de invasão de hardware, é na verdade o ataque de software: você tem um chipset na sua placa -mãe que apresenta um controlador de invasão de baixo custo que exige que algum software (drivers) faça o trabalho real. Definitivamente, o Raid Linux (MD) é muito melhor em termos de desempenho (eu acho) e em termos de flexibilidade (com certeza).
- A menos que você tenha uma CPU muito antiga (classe Pentium II), o ataque suave não é tão caro (isso não é tão verdadeiro para o RAID5, na verdade, mas para RAID0, RAID1 e RAID10, é verdade).
Portanto, se você não tiver idéia de como implementar uma determinada especificação usando RAID, consulte a documentação do RAID.
Algumas poucas dicas, no entanto:
- qualquer coisa com um .0 pode ser mapeado para o RAID0, que é a combinação de invasão mais de desempenho (mas se um dispositivo de armazenamento falhar, você perde tudo).
- s.R.1, r.R.1 e sr.R.1 pode ser mapeado em ordem de preferências para RAID10 (mínimo de 4 dispositivos de armazenamento (SD) necessários), RAID5 (3 DP exigido), RAID1 (2 DP).
- s.C.1, pode ser mapeado em ordem de preferências para RAID10, RAID1 e RAID5.
- r.C.1, pode ser mapeado em ordem de preferências para RAID10 e RAID1 (RAID5 tem um desempenho muito ruim na gravação aleatória).
- sr.R.2 pode ser mapeado para RAID10 (algumas maneiras) e para RAID6.
Quando você mapeia o espaço de armazenamento para um determinado volume físico, não anexe dois espaços de armazenamento do mesmo dispositivo de armazenamento (i.e. partições). Você perderá as duas vantagens do desempenho e da tolerância a falhas! Por exemplo, fazer /dev /sda1 e /dev /sda2 parte do mesmo volume físico RAID1 é bastante inútil.
Finalmente, se você não tiver certeza do que escolher entre LVM e MDADM, sugiro que o Mdadm tenha é um pouco mais flexível (ele suporta RAID0, 1, 5 e 10, enquanto o LVM suporta apenas a listra (semelhante ao RAID0) e espelhando (semelhante ao Raid1)).
Mesmo se estritamente não é necessário, se você usar o MDADM, provavelmente acabará com um mapeamento individual entre VGs e PVs. Disse o contrário, você pode mapear muitos PVs para um VG. Mas isso é um pouco inútil em minha humilde opinião. O MDADM fornece toda a flexibilidade necessária no mapeamento de partições/dispositivos de armazenamento em implementações de VG.
Definindo partições
Por fim, você pode querer fazer algumas partições com seus diferentes dispositivos de armazenamento para atender aos seus requisitos de PV (por exemplo, RAID5 requer pelo menos 3 espaços de armazenamento diferentes). Observe que, na grande maioria dos casos, suas partições terão que ser do mesmo tamanho.
Se você puder, sugiro usar diretamente dispositivos de armazenamento (ou fazer apenas uma única partição a partir de um disco). Mas pode ser difícil se você for curto em dispositivos de armazenamento. Além disso, se você tiver dispositivos de armazenamento de tamanhos diferentes, terá que particionar um deles pelo menos.
Pode ser necessário encontrar alguma troca entre seus requisitos de PV e seus dispositivos de armazenamento disponíveis. Por exemplo, se você tiver apenas dois discos rígidos, definitivamente não poderá implementar um PV RAID5. Você terá que confiar apenas em uma implementação RAID1.
Observe que se você realmente seguir o processo de fundo superior descrito neste documento (e se você puder pagar o preço de seus requisitos, é claro), não há troca real para lidar com! 😉
/bota
Não mencionamos em nosso estudo o sistema de arquivo /inicialização, onde o carregador de inicialização é armazenado. Alguns preferem ter apenas um único / onde / bota é apenas um subdiretório. Outros preferem separar / e / bota. No nosso caso, onde usamos LVM e MDADM, sugiro a seguinte ideia:
- /Boot é um sistema de arquivo separado porque algum carregador de inicialização pode ter problemas com os volumes LVM;
- /Boot é um sistema de arquivo ext2 ou ext3, pois esses formatos são bem suportados por qualquer carregador de inicialização;
- O tamanho da inicialização seria de 100 MB, porque os initramfs podem ser bastante pesados e você pode ter vários núcleos com seus próprios initramfs;
- /bota não é um volume LVM;
- /Boot é um volume RAID1 (criado usando o MDADM). Isso garante que pelo menos dois dispositivos de armazenamento tenham exatamente o mesmo conteúdo composto por kernel, initramfs, sistema.mapa e outras coisas necessárias para a inicialização;
- O volume /Boot RAID1 é feito de duas partições primárias que são a primeira partição em seus respectivos discos. Isso impede que algumas biografias antigas não encontrem o carregador de inicialização devido às limitações antigas de 1 GB.
- O carregador de inicialização foi instalado em ambas as partições (discos) para que o sistema possa inicializar de ambos os discos.
- O BIOS foi configurado corretamente para inicializar em qualquer disco.
Trocar
A troca também é uma coisa que não discutimos até agora. Você tem muitas opções aqui:
- desempenho:
- Se você precisar de desempenho a todo custo, definitivamente, crie uma partição em cada um de seu dispositivo de armazenamento e use -o como uma partição de troca. O kernel equilibrará a entrada/saída para cada partição de acordo com sua própria necessidade, levando ao melhor desempenho. Observe que você pode brincar com prioridade para dar algumas preferências a discuss de dados rígidos (por exemplo, uma unidade rápida pode ter uma prioridade mais alta).
- tolerância ao erro:
- Se você precisar de tolerância a falhas, definitivamente, considere a criação de um volume de troca LVM de um R.Rw.1 Grupo de Volume (implementado por um RAID1 ou RAID10 PV, por exemplo).
- flexibilidade:
- Se você precisar redimensionar sua troca por alguns motivos, sugiro usar um ou muitos volumes de troca LVM.
Sistemas de arquivos futuros e/ou exóticos
Usando o LVM, é muito fácil configurar um novo volume lógico criado a partir de algum grupo de volume (dependendo do que você deseja testar e de seu hardware) e formatá-lo em alguns sistemas de arquivo. LVM é muito flexível a esse respeito. Sinta-se à vontade para criar e remover os sistemas de arquivos à vontade.
Mas, de certa forma, futuros sistemas de arquivos, como ZFS, BTRFs e Nilfs2, não cabem perfeitamente com LVM. O motivo é que o LVM leva a uma clara separação entre as necessidades de aplicação/usuário e implementações dessas necessidades, como vimos. Por outro lado, ZFS e BTRFs integram as necessidades e a implementação em uma coisa. Por exemplo, tanto o ZFS quanto o BTRFS suporta o nível RAID diretamente. O bom é que facilita a criação do layout do sistema de arquivos. O ruim é que isso viola algumas maneiras pelas quais a separação da estratégia de preocupação.
Portanto, você pode acabar com um xfs/lv/vg/md1/sd a, b 1 e btrfs/sd a, b 2 dentro do mesmo sistema. Eu não recomendaria esse layout e sugiro usar ZFS ou BTRFs para tudo ou não.
Outro sistema de arquivo que pode ser interessante é o nilfs2. Este LOG estruturou os sistemas de arquivos terá um desempenho de gravação muito bom (mas talvez um desempenho ruim de leitura). Portanto, esse sistema de arquivo pode ser um candidato muito bom para o volume lógico de anexos ou em qualquer volume lógico criado a partir de um RS.C.N Grupo de Volume.
Unidades USB
Se você deseja usar uma ou várias unidades USB em seu layout, considere o seguinte:
- A largura de banda do barramento USB V2 é de 480 Mbits/s (60 mbytes/s), o que é suficiente para a grande maioria dos aplicativos de mesa (exceto talvez o vídeo HD);
- Até onde eu sei, você não encontrará nenhum dispositivo USB que possa cumprir a largura de banda USB V2.
Portanto, pode ser interessante usar várias unidades USB (ou até mesmo) para torná -las parte de um sistema de invasão, especialmente um sistema RAID1. Com esse layout, você pode retirar uma unidade USB de uma matriz RAID1 e usá-la (no modo somente leitura) em outro lugar. Em seguida, você o puxa novamente em sua matriz Raid1 original e com um comando Magic Mdadm, como:
mdadm /dev /md0 -add /dev /sda1
A matriz reconstruirá automaticamente e voltará ao seu estado original. Eu não recomendaria fazer nenhuma outra matriz de invasão fora de USB Drive, no entanto. Para Raid0, é óbvio: se você remover uma unidade USB, você perde todos os seus dados! Para RAID5, tendo unidade USB e, portanto, a capacidade de capricho quente não oferece vantagem: a unidade USB que você retirou é inútil em um modo RAID5! (mesma observação para RAID10).
Unidades de estado sólido
Finalmente, novas unidades de SSD podem ser consideradas ao definir volumes físicos. Suas propriedades devem ser levadas em consideração:
- Eles têm latência muito baixa (leitura e gravação);
- Eles têm muito bom desempenho e fragmentação aleatórios de leitura não tem impacto em seu desempenho (desempenho determinístico);
- O número de gravações é limitado.
Portanto, as unidades de SSD são adequadas para implementar grupos de volume RSR#N. Como exemplo, mm.LV e leia.Os volumes de VE podem ser armazenados em SSDs, pois os dados geralmente são escritos uma vez e lidos muitas vezes. Este padrão de uso é perfeito para SSD.
Conclusão
No processo de projetar um layout do sistema de arquivos, a abordagem de fundo superior começa com necessidades de alto nível. Este método tem a vantagem em que você pode confiar nos requisitos feitos anteriormente para sistemas semelhantes. Somente a implementação mudará. Por exemplo, se você projetar um sistema de desktop: você pode acabar com um determinado layout (como o da Figura 1). Se você instalar outro sistema de desktop com diferentes dispositivos de armazenamento, poderá confiar em seus primeiros requisitos. Você só precisa adaptar as camadas inferiores: PVs e partições. Portanto, o grande trabalho, padrão de uso ou carga de trabalho, a análise pode ser feita apenas uma vez por sistema, naturalmente.
Na seção seguinte e final, darei alguns exemplos de layout, aproximadamente sintonizados para alguns usos conhecidos de computador.
Exemplos de layout
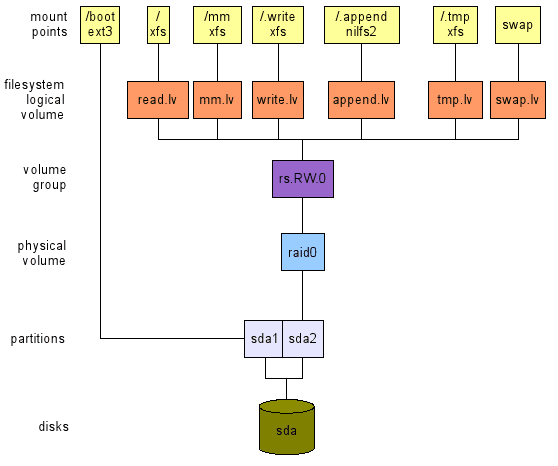
Qualquer uso, 1 disco.
Isso (veja o layout superior de Figura 2) é uma situação bastante estranha na minha opinião. Como já foi dito, considero que qualquer computador deve ser dimensionado de acordo com algum padrão de uso. E ter apenas um disco anexado ao seu sistema significa que você aceita uma falha completa dele de alguma forma. Mas eu sei que hoje a grande maioria dos computadores - especialmente laptops e netbooks - são vendidos (e projetados) com apenas um único disco. Portanto, proponho o seguinte layout que se concentra na flexibilidade e desempenho (tanto quanto possível):
- flexibilidade:
- Como o layout permite redimensionar volumes à vontade;
- desempenho:
- Como você pode escolher um sistema de arquivo (ext2/3, xfs e assim por diante) de acordo com os padrões de acesso a dados.
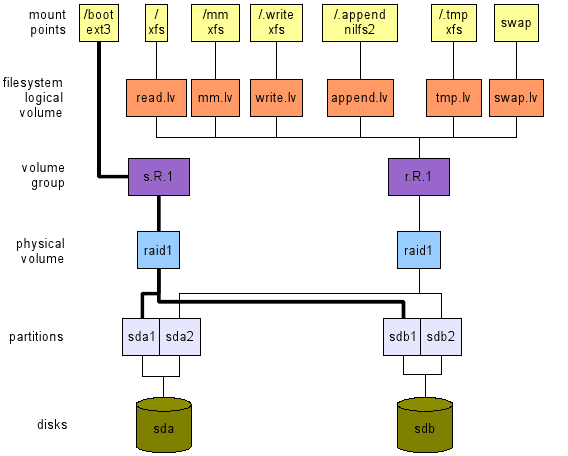
- Figura 2: Um layout com um disco (em cima) e um para uso da área de trabalho com dois discos (inferior).
-
-
- flexibilidade:
- Como o layout permite redimensionar volumes à vontade;
- desempenho:
- como você pode escolher um sistema de arquivo (ext2/3, xfs etc.R.1 VG pode ser fornecido por um PV RAID1 para um bom desempenho de leitura aleatória (em média). Note, no entanto, que ambos S.R.n e Rs.C.n não pode ser fornecido com apenas 2 discos para qualquer valor de n.
- Alta disponibilidade:
- Se um disco falhar, o sistema continuará trabalhando em um modo degradado.
- flexibilidade:
- Como o layout permite redimensionar volumes à vontade;
- desempenho:
- Como você pode escolher um sistema de arquivo (ext2/3, xfs etc.R.1 e Rs.Rw.0 pode ser fornecido com 2 discos graças a RAID1 e RAID0.
- Disponibilidade média:
- Se um disco falhar, dados importantes permanecerão acessíveis, mas o sistema não poderá funcionar corretamente, a menos que algumas ações sejam tomadas para mapear /.TMP e trocar para outro LV mapeado para um VG seguro.
Uso da área de trabalho, alta disponibilidade, 2 discos.
Aqui (veja o layout inferior da Figura 2), nossa preocupação é alta disponibilidade. Como temos apenas dois discos, apenas o RAID1 pode ser usado. Esta configuração fornece:
Observação: A região de troca deve estar no PV RAID1 para garantir alta disponibilidade.
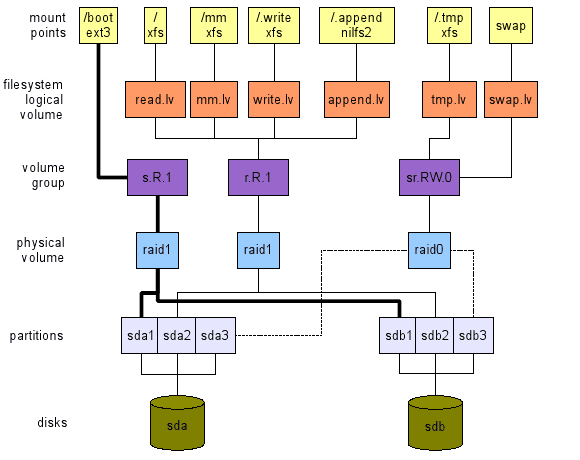
Uso da área de trabalho, alto desempenho, 2 discos
Aqui (veja o layout superior da Figura 3), nossa preocupação é de alto desempenho. Observe, no entanto, que ainda considero inaceitável perder alguns dados. Este layout fornece o seguinte:
- Observação: A região de troca é feita a partir do RS.Rw.0 VG implementado pelo RAID0 PV para garantir a flexibilidade (as regiões de troca de redimensionamento são indolores). Outra opção é usar diretamente uma quarta partição de ambos os discos.
Figura 3: TOP: Layout para uso de desktop de alto desempenho com dois discos. Inferior: layout para servidor de arquivos com quatro discos.
- flexibilidade:
- Como o layout permite redimensionar volumes à vontade;
- desempenho:
- Como você pode escolher um sistema de arquivo (ext2/3, xfs etc.R.1 e Rs.Rw.1 pode ser fornecido com 4 discos graças a RAID5 e RAID10.
- Alta disponibilidade:
- Se um disco falhar, qualquer dados permanecerá acessível e o sistema poderá funcionar corretamente.
- Ou você tem armazenamento suficiente ou/e seus usuários têm altas necessidades de acesso de gravação aleatórias/seqüenciais, o PV RAID10 é a boa opção;
- Ou, você não tem armazenamento suficiente ou/e seus usuários não possuem altas necessidades de acesso de gravação aleatórias/seqüenciais, o RAID5 PV é a boa opção.
Servidor de arquivos, 4 discos.
Aqui (veja o layout inferior da Figura 3), nossa preocupação é de alto desempenho e alta disponibilidade. Este layout fornece o seguinte:
Nota 1:
Podemos ter usado o RAID10 para todo o sistema, pois fornece uma implementação muito boa de Rs.Rw.1 VG (e de alguma maneira também Rs.Rw.2). Infelizmente, isso tem um custo: 4 dispositivos de armazenamento são necessários (aqui partições), cada uma das mesmas capacidade S (digamos s = 500 gigabytes). Mas o volume físico RAID10 não fornece uma capacidade de 4*s (2 terabytes) como você pode esperar. Ele fornece apenas metade dele, 2*s (1 terabytes). Os outros 2*s (1 terabytes) são usados para alta disponibilidade (espelho). Veja a documentação do RAID para obter detalhes. Portanto, eu escolho usar RAID5 para implementar Rs.R.1. RAID5 fornecerá capacidade de 3*s (1.5 gigabytes), os restantes (500 gigabytes) são usados para alta disponibilidade. O mm.O LV geralmente requer uma grande quantidade de espaço de armazenamento, pois possui arquivos multimídia.
Nota 2:
Se você exportar os diretórios NFS ou SMB 'Home', poderá considerar a localização deles com cuidado. Se seus usuários precisarem de muito espaço, fazendo casas na gravação.O LV (a localização do 'Fit-All') pode ter carote de armazenamento, pois é apoiado por um PV RAID10, onde metade do espaço de armazenamento é usada para espelhamento (e desempenho). Você tem duas opções aqui:
Perguntas, comentários e sugestões
Se você tiver alguma dúvida, comentar e/ou sugestão neste documento, não hesite em entrar em contato comigo no seguinte endereço: [email protected].
Direitos autorais
Este documento está licenciado sob um Creative Commons Attribution-Share 2.0 Licença da França.
Isenção de responsabilidade
As informações contidas neste documento são apenas para fins de informação geral. As informações são fornecidas por Pierre Vignéras e, embora eu me esforce para manter as informações atualizadas e corretas, não faço representações ou garantias de qualquer tipo, expresso ou implícito sobre a integridade, precisão, confiabilidade, adequação ou disponibilidade em relação ao documento ou as informações, produtos, serviços ou gráficos relacionados contidos no documento para qualquer finalidade.
Qualquer confiança que você coloca nessas informações é, portanto, estritamente por sua conta e risco. Em nenhum caso, serei responsável por qualquer perda ou dano, inclusive sem limitação, perda ou dano indireto ou conseqüente, ou qualquer perda ou dano decorrente da perda de dados ou lucros decorrentes ou em conexão com o uso deste documento.
Através deste documento, você pode vincular -se a outros documentos que não estão sob o controle de Pierre Vignéras. Não tenho controle sobre a natureza, o conteúdo e a disponibilidade desses sites. A inclusão de qualquer link não implica necessariamente uma recomendação ou endossa as opiniões expressas dentro deles.
Tutoriais do Linux relacionados:
- Coisas para instalar no Ubuntu 20.04
- Coisas para fazer depois de instalar o Ubuntu 20.04 fossa focal linux
- Arquivos de configuração do Linux: os 30 primeiros mais importantes
- Coisas para fazer depois de instalar o Ubuntu 22.04 Jellyfish…
- Como verificar uma saúde do disco rígido na linha de comando…
- Mint 20: Melhor que o Ubuntu e o Microsoft Windows?
- Download do Linux
- Ubuntu 20.04 Guia
- Manjaro Linux Windows 10 Boot dual
- Uma introdução à automação, ferramentas e técnicas do Linux
- « 101 como começar com o OpenCV e a visão computacional no Ubuntu Linux
- Problema de teclas de seta VMware no Ubuntu »