

Instale o cluster multinodo Hadoop usando CDH4 em RHEL/CENTOS 6.5

- 644
- 63
- Enrique Crist
Hadoop é uma estrutura de programação de código aberto desenvolvido pela Apache para processar big data. Ele usa HDFS (Sistema de arquivos distribuído Hadoop) para armazenar os dados em todos os DataNodes no cluster de maneira distributiva e o modelo MapReduce para processar os dados.
 Instale o hadoop multinodo cluster
Instale o hadoop multinodo cluster Namenode (Nn) é um daemon mestre que controla HDFS e Jobtracker (Jt) é daemon mestre para mecanismo MapReduce.
Requisitos
Neste tutorial, estou usando dois CENTOS 6.3 Vm 'mestre' e 'nó'viz. (Master e Node são meus nomes de host). O ip 'mestre' é 172.21.17.175 e o nó IP é '172.21.17.188'. As seguintes instruções também funcionam em RHEL/CENTOS 6.x versões.
Em mestre
[[Email Protected] ~]# HostName mestre
[[Email Protected] ~]# ifconfig | Grep 'Inet Addr' | Head -1 Inet Addr:172.21.17.175 Bcast: 172.21.19.255 máscara: 255.255.252.0
No nó
[[Email Protected] ~]# HostName nó
[[Email Protected] ~]# ifconfig | Grep 'Inet Addr' | Head -1 Inet Addr:172.21.17.188 Bcast: 172.21.19.255 máscara: 255.255.252.0
Primeiro, verifique se todos os hosts de cluster estão lá em '/etc/hosts'arquivo (em cada nó), se você não tiver DNS configurado.
Em mestre
[[Email Protected] ~]# cat /etc /hosts 172.21.17.175 Mestre 172.21.17.188 Nó
No nó
[[Email Protected] ~]# cat /etc /hosts 172.21.17.197 Qabox 172.21.17.176 Ansible-Ground
Instalando o Hadoop Multinode Cluster em CentOS
Usamos oficial CDH repositório para instalar CDH4 Em todos os hosts (mestre e nó) em um cluster.
Etapa 1: Faça o download de instalar o repositório CDH
Vá para a página oficial de download do CDH e pegue o CDH4 (i.e. 4.6) versão ou você pode usar o seguinte wget comando para baixar o repositório e instalá -lo.
No RHEL/CENTOS 32 bits
# wget http: // arquivo.Cloudera.com/CDH4/One-Click-Install/Redhat/6/i386/Cloudera-CDH-4-0.I386.RPM # YUM-NOGPGCHECK LocalInstall Cloudera-CDH-4-0.I386.RPM
No RHEL/CENTOS 64 bits
# wget http: // arquivo.Cloudera.com/CDH4/One-Click-Install/Redhat/6/x86_64/Cloudera-CDH-4-0.x86_64.RPM # YUM-NOGPGCHECK LocalInstall Cloudera-CDH-4-0.x86_64.RPM
Antes de instalar o hadoop multinodo cluster, adicione a chave GPG pública de Cloudera ao seu repositório executando um dos seguintes comando de acordo com a arquitetura do seu sistema.
## no sistema de 32 bits ## # rpm --import http: // arquivo.Cloudera.com/cdh4/redhat/6/i386/cdh/rpm-gpg-key-cloudera
## no sistema de 64 bits ## # rpm --import http: // arquivo.Cloudera.com/cdh4/redhat/6/x86_64/cdh/rpm-gpg-key-cloudera
Etapa 2: Configurar Jobtracker e Namenode
Em seguida, execute o seguinte comando para instalar e configurar o JobTracker e NameNode no servidor mestre.
[[Email Protected] ~]# yum limpe todos [[email protegido] ~]# yum install hadoop-0.20-mapreduce-jobtracker
[[Email Protected] ~]# yum limpe todos [[email protegido] ~]# yum install hadoop-hdfs-namenode
Etapa 3: Nó do nome secundário de configuração
Novamente, execute os seguintes comandos no servidor mestre para configurar o nó secundário nó.
[[Email Protected] ~]# yum limpe todos [[email protegido] ~]# yum install hadoop-hdfs-secundarynam
Etapa 4: Configurar TaskTracker e DataNode
Em seguida, configure o TaskTracker & Datanode em todos os hosts de cluster (nó), exceto o Jobtracker, Namenode e Hosts de Namenode secundário (ou em espera) (no nó neste caso).
[[Email Protected] ~]# yum limpe todos [[email protegido] ~]# yum install hadoop-0.20-Mapreduce-Tasktracker Hadoop-HDFS-Datanode
Etapa 5: Configurar o cliente Hadoop
Você pode instalar o Hadoop Client em uma máquina separada (neste caso, eu a instalei no DataNode, você pode instalá -lo em qualquer máquina).
[[Email Protected] ~]# yum instale hadoop-client
Etapa 6: Implante HDFs nos nós
Agora, se terminarmos as etapas acima, vamos avançar para implantar HDFs (a ser feita em todos os nós).
Copie a configuração padrão para /etc/hadoop diretório (em cada nó em cluster).
[[email protegido] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
[[email protegido] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
Usar alternativas comando para definir seu diretório personalizado, como segue (em cada nó em cluster).
[[email protegido] ~]# alternativas --verbose--instala/etc/hadoop/conf Hadoop-Conf/etc/hadoop/conf.my_cluster 50 leitura/var/lib/alternativas/hadoop-Conf [[email protegido] ~]# alternativas--set hadoop-conf/etc/hadoop/conf.my_cluster
[[email protegido] ~]# alternativas --verbose--instala/etc/hadoop/conf Hadoop-Conf/etc/hadoop/conf.my_cluster 50 leitura/var/lib/alternativas/hadoop-Conf [[email protegido] ~]# alternativas--set hadoop-conf/etc/hadoop/conf.my_cluster
Etapa 7: Personalizando arquivos de configuração
Agora aberto 'Site do núcleo.xml'Arquivo e atualização “fs.Defaultfs”Em cada nó em cluster.
[[Email Protected] conf]# cat/etc/hadoop/conf/core-site.xml
fs.Defaultfs hdfs: // mestre/
[[Email Protected] conf]# cat/etc/hadoop/conf/core-site.xml
fs.Defaultfs hdfs: // mestre/
Próxima atualização “dfs.permissões.SuperUserGroup" em Site HDFS.xml em cada nó em cluster.
[[Email Protected] conf]# cat/etc/hadoop/conf/hdfs-site.xml
dfs.nome.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/nome dfs.permissões.SuperUsergroup Hadoop
[[Email Protected] conf]# cat/etc/hadoop/conf/hdfs-site.xml
dfs.nome.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/nome dfs.permissões.SuperUsergroup Hadoop
Observação: Por favor, verifique se a configuração acima está presente em todos os nós (faça em um nó e execute SCP para copiar no restante dos nós).
Etapa 8: Configurando diretórios de armazenamento locais
Atualize “DFS.nome.dir ou dfs.Namenode.nome.dir ”em 'hdfs-site.xml 'no namenode (no mestre e nó). Altere o valor como destacado.
[[Email Protected] conf]# cat/etc/hadoop/conf/hdfs-site.xml
dfs.Namenode.nome.dir Arquivo: /// data/1/dfs/nn,/nfsmount/dfs/nn
[[Email Protected] conf]# cat/etc/hadoop/conf/hdfs-site.xml
dfs.DataNode.dados.dir Arquivo: /// data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Etapa 9: Crie diretórios e gerencie permissões
Execute os comandos abaixo para criar estrutura de diretório e gerenciar permissões de usuário na máquina Namenode (Master) e DataNode (NODE).
[[email protegido]]# mkdir -p/data/1/dfs/nn/nfsmount/dfs/nn [[email protegido]]# chmod 700/data/1/dfs/nn/nfsmount/dfs/nn
[[email protegido]]# mkdir -p/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/dn [[email protegido]]# chown -R hdfs: hdfs/data/1/dfs/nn/nfsmount/dfs/nn/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/ dn
Formatar o namenode (no mestre), emitindo o seguinte comando.
[[Email Protected] conf]# sudo -u hdfs hdfs namenode -format
Etapa 10: Configurando o Namenode secundário
Adicione a seguinte propriedade ao Site HDFS.xml Arquive e substitua o valor como mostrado no mestre.
dfs.Namenode.http-address 172.21.17.175: 50070 O endereço e a porta nos quais a interface do nome Namenode vai ouvir.
Observação: No nosso caso, o valor deve ser o endereço IP da VM Master.
Agora vamos implantar o MRV1 (versão do mapa 1). Abrir 'MapRed-site.xml'Arquivo a seguir os valores como mostrado.
[[Email Protected] conf]# cp hdfs-site.XML MAPRED-SITE.XML [[Email Protected] conf]# Vi MapRed-Site.XML [[Email Protected] conf]# Cat MapRed-Site.xml
mapa.trabalho.Tracker Master: 8021
Em seguida, copiar 'MapRed-site.xml'Arquivo para a máquina de nó usando o seguinte comando scp.
[[Email Protected] conf]# scp/etc/hadoop/conf/mapred-site.nó xml:/etc/hadoop/conf/mapred-site.XML 100% 200 0.2kb/s 00:00
Agora configure os diretórios de armazenamento locais a serem usados pelo MRV1 Daemons. Novamente aberto 'MapRed-site.xml'Arquive e faça alterações como mostrado abaixo para cada tracker -tarefa.
 Mapred.local.dir â/dados/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
Depois de especificar esses diretórios no 'MapRed-site.xml'arquivo, você deve criar os diretórios e atribuir as permissões de arquivo corretas a eles em cada nó em seu cluster.
mkdir -p/data/1/mapred/local/data/2/mapred/local/data/3/mapred/local/data/4/mapred/local CHOW dados/2/mapred/local/data/3/mapred/local/data/4/mapred/local
Etapa 10: Inicie HDFS
Agora execute o seguinte comando para iniciar HDFs em todos os nó no cluster.
[[email protegido] conf]# para x em 'cd /etc /init.d; ls hadoop-hdfs-*'; Faça o serviço sudo $ x start; feito
[[email protegido] conf]# para x em 'cd /etc /init.d; ls hadoop-hdfs-*'; Faça o serviço sudo $ x start; feito
Etapa 11: Crie diretórios HDFs /TMP e MapReduce /Var
É necessário para criar /tmp com permissões adequadas exatamente como mencionado abaixo.
[[Email Protected] conf]# sudo -u hdfs hadoop fs -mkdir /tmp [[email protegido] conf]# sudo -u hdfs hadoop fs -chmod -r 1777 /tmp
[[Email protegido] conf]# sudo -u hdfs hadoop fs -mkdir -p/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[email protegido] conf]# sudo -u hdfs hadoop fs -chmod 1777/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[email protegido] conf]# sudo -u hdfs hadoop fs -chown -r mapred/var/lib/hadoop -hdfs/cache/mapred
Agora verifique a estrutura do arquivo HDFS.
[[Email Protected] ODE conf]# sudo -u hdfs hadoop fs -ls -r / drwxrwxrwt-hdfs hadoop 0 2014-05-29 09:58 / tmp drwxr-xr-x-hdfs hadoop 0 2014-05-29 09 : 59 /var drwxr-xr-x-hdfs hadoop 0 2014-05-29 09:59 /var /libxr-xr-x-hdfs hadoop 0 2014-05-29 09:59 /var /lib /hadoop-hdfs DRWXR-XR-X-HDFS HADOOP 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache drwxr-xr-x-mapered hadoop 0 2014-05-29 09:59/var/lib/hadoop -hdfs/cache/mapred DRWXR-XR-X-MAPRED HADOOP 0 2014-05-29 09:59/VAR/LIB/HADOOP-HDFS/CACHE/MAPRED/MAPRED DRWXRWXRWT-MAPREDOOP 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging
Depois de iniciar o HDFS e criar '/tmp', mas antes de iniciar o Jobtracker, crie o diretório HDFS especificado pelo' mapa.sistema.Dir 'Parâmetro (por padrão $ Hadoop.TMP.dir/mapred/sistema e altere o proprietário para mapa.
[[Email Protected] conf]# sudo -u hdfs hadoop fs -mkdir/tmp/mapRed/system [[email protegido] conf]# sudo -u hdfs hadoop fs -chown mapred: hadoop/tmp/mapred/sistema
Etapa 12: Inicie o MapReduce
Para iniciar o MapReduce: Inicie os serviços TT e JT.
Em cada sistema de tracker -tarefa
[[Email Protected] conf]# serviço hadoop-0.20-Mapreduce-Tasktracker Iniciar o TaskTracker: [OK] TaskTracker de partida, logando para/var/log/hadoop-0.20-Mapreduce/Hadoop-Hadoop-Tasktracker-Node.fora
No sistema JobTracker
[[Email Protected] conf]# serviço hadoop-0.20-Mapreduce-Jobtracker Começando a iniciar o JobTracker: [OK] Iniciando Jobtracker, logando para/var/log/hadoop-0.Mápreduco/Hadoop-Hadoop-Jobtracker-Mestre.fora
Em seguida, crie um diretório doméstico para cada usuário do Hadoop. É recomendável que você faça isso no Namenode; por exemplo.
[[Email Protected] conf]# sudo -u hdfs hadoop fs -mkdirâ /user /[[email protegido] conf]# sudo -u hdfs hadoop fs -Chown /user /user /
Observação: onde é o nome de usuário do Linux de cada usuário.
Como alternativa, você põe o diretório doméstico da seguinte forma.
[[Email Protected] conf]# sudo -u hdfs hadoop fs -mkdir /user /$ user [[email protegido] conf]# sudo -u hdfs hadoop fs -chown $ user /$ user /$ user
Etapa 13: Open JT, NN UI do navegador
Abra seu navegador e digite o URL como http: // ip_address_of_namenode: 50070 Para acessar o Namenode.
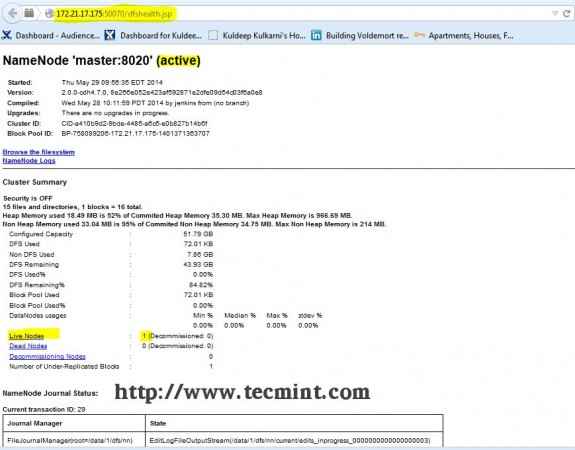 Interface Hadoop Namenode
Interface Hadoop Namenode Abra outra guia no seu navegador e digite o URL como http: // ip_address_of_jobtracker: 50030 Para acessar o JobTracker.
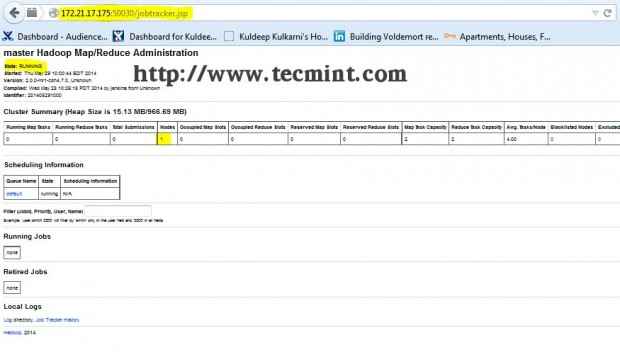 Hadoop Map/Reduce Administration
Hadoop Map/Reduce Administration Este procedimento foi testado com sucesso em RHEL/CENTOS 5.X/6.X. Por favor, comente abaixo se você enfrentar algum problema com a instalação, eu o ajudarei com as soluções.
- « Crie seu próprio site de compartilhamento de vídeo usando 'script CumulusClips' no Linux
- Criando hosts virtuais, gerar certificados e chaves SSL e ativar o gateway CGI no Gentoo Linux »