

Como recuperar dados e reconstruir o RAID de software fracassado - Parte 8

- 2137
- 42
- Mrs. Christopher Okuneva
Nos artigos anteriores desta série RAID, você passou de zero para o herói da RAID. Analisamos várias configurações de invasão de software e explicamos o essencial de cada um, juntamente com as razões pelas quais você se inclinaria para um ou outro, dependendo do seu cenário específico.
 Recuperar reconstrução Falha no software RAID - Parte 8
Recuperar reconstrução Falha no software RAID - Parte 8 Neste guia, discutiremos como reconstruir uma matriz RAID de software sem perda de dados quando no caso de uma falha de disco. Para a brevidade, consideraremos apenas um Raid 1 configuração - mas os conceitos e comandos se aplicam a todos os casos.
Cenário de teste de ataque
Antes de prosseguir, verifique se você configurou um Raid 1 Array seguindo as instruções fornecidas na Parte 3 desta série: Como configurar o RAID 1 (espelho) no Linux.
As únicas variações em nosso presente caso serão:
1) Uma versão diferente do CentOS (V7) do que a usada nesse artigo (V6.5) e
2) diferentes tamanhos de disco para /dev/sdb e /dev/sdc (8 GB cada).
Além disso, se Selinux está ativado no modo de aplicação, você precisará adicionar os rótulos correspondentes ao diretório onde você montará o dispositivo RAID. Caso contrário, você encontrará esta mensagem de aviso ao tentar montá -la:
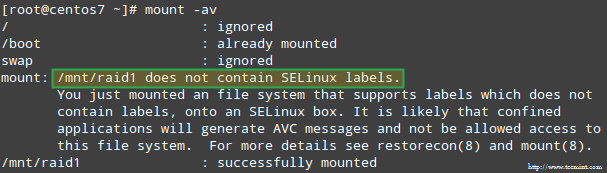 Erro de montagem do Selinux Raid
Erro de montagem do Selinux Raid Você pode consertar isso executando:
# RESTORECON -R /MNT /RAID1
Configurando o monitoramento do RAID
Há várias razões pelas quais um dispositivo de armazenamento pode falhar (no entanto, os SSDs reduziram bastante as chances de isso acontecer), mas independentemente da causa, você pode ter certeza de que os problemas podem ocorrer a qualquer momento e você precisa estar preparado para substituir a falha. parte e para garantir a disponibilidade e integridade de seus dados.
Uma palavra de conselho primeiro. Mesmo quando você pode inspecionar /proc/mdstat Para verificar o status de seus ataques, há um método melhor e de economia de tempo que consiste em correr mdadm No modo Monitor + Scan, que enviará alertas por e -mail para um destinatário predefinido.
Para configurar isso, adicione a seguinte linha em /etc/mdadm.conf:
MailAddr [Email Protected]
No meu caso:
MailAddr [Email Protected]
 RAID Monitoramento de alertas de email
RAID Monitoramento de alertas de email Para correr mdadm No modo Monitor + Scan, adicione a seguinte entrada Crontab como raiz:
@reboot /sbin /mdadm -monitor - -scan --oShot
Por padrão, mdadm verificará as matrizes de ataque a cada 60 segundos e enviarei um alerta se encontrar um problema. Você pode modificar esse comportamento adicionando o --atraso opção para a entrada crontab acima, juntamente com a quantidade de segundos (por exemplo, --atraso 1800 significa 30 minutos).
Finalmente, verifique se você tem um Mail User Agent (MUA) instalado, como Mutt ou Mailx. Caso contrário, você não receberá alertas.
Em um minuto, veremos o que um alerta enviado por mdadm parece.
Simulando e substituindo um dispositivo de armazenamento com falha no RAID
Para simular um problema com um dos dispositivos de armazenamento na matriz RAID, usaremos o --gerenciar e --F-FOLTY Opções da seguinte forma:
# mdadm-manágio--defaulty /dev /md0 /dev /sdc1
Isso resultará em /dev/sdc1 sendo marcado como com defeito, como podemos ver em /proc/mdstat:
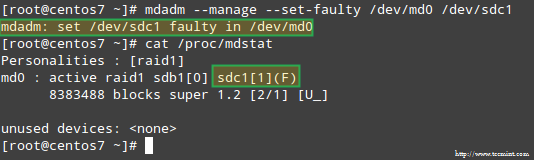 Estimular o problema com o armazenamento de invasão
Estimular o problema com o armazenamento de invasão Mais importante, vamos ver se recebemos um alerta por e -mail com o mesmo aviso:
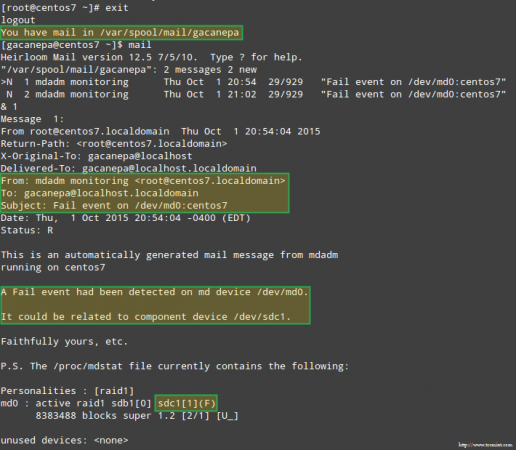 Alerta por e -mail no dispositivo RAID com falha
Alerta por e -mail no dispositivo RAID com falha Nesse caso, você precisará remover o dispositivo da matriz RAID de software:
# mdadm /dev /md0 - -remove /dev /sdc1
Em seguida, você pode removê -lo fisicamente da máquina e substituí -lo por uma peça sobressalente (/dev/sdd, Onde uma partição do tipo fd foi criado anteriormente):
# mdadm -manage /dev /md0 --add /dev /sdd1
Felizmente para nós, o sistema começará automaticamente a reconstruir a matriz com a parte que acabamos de adicionar. Podemos testar isso marcando /dev/sdb1 como defeituoso, removendo -o da matriz e certificando -se de que o arquivo Tecmint.TXT ainda está acessível em /MNT/RAID1:
# mdadm -detail /dev /md0 # montagem | Grep RAID1 # LS -L /MNT /RAID1 | Grep Tecmint # CAT/MNT/RAID1/TECMINT.TXT
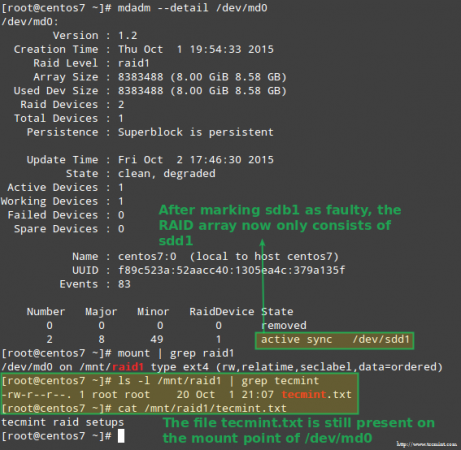 Confirme a reconstrução do Array de Raid
Confirme a reconstrução do Array de Raid A imagem acima mostra claramente que depois de adicionar /dev/sdd1 para a matriz como um substituto para /dev/sdc1, A reconstrução dos dados foi realizada automaticamente pelo sistema sem intervenção de nossa parte.
Embora não seja estritamente necessário, é uma ótima idéia ter um dispositivo sobressalente útil, para que o processo de substituição do dispositivo com defeito por uma boa unidade possa ser feita em um snap. Para fazer isso, vamos re-adquirir /dev/sdb1 e /dev/sdc1:
# mdadm -manage /dev /md0 --add /dev /sdb1 # mdadm -manaage /dev /md0 --add /dev /sdc1
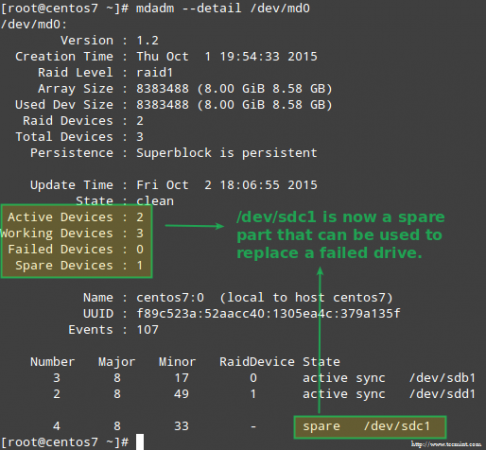 Substitua o dispositivo de invasão com falha
Substitua o dispositivo de invasão com falha Recuperando -se de uma perda de redundância
Conforme explicado anteriormente, mdadm reconstruirá automaticamente os dados quando um disco falhar. Mas o que acontece se 2 discos na matriz falharem? Vamos simular esse cenário marcando /dev/sdb1 e /dev/sdd1 Tão defeituoso:
# Umount /mnt /Raid1 # mdadm --manage--set-faulty /dev /md0 /dev /sdb1 # mdadm--stop /dev /md0 # mdadm --manage--set-faulty /dev /md0 /dev /dev / SDD1
Tentativas de recriar a matriz da mesma maneira que foi criada neste momento (ou usando o --Assuma limpeza opção) pode resultar em perda de dados, por isso deve ser deixado como último recurso.
Vamos tentar recuperar os dados de /dev/sdb1, Por exemplo, em uma partição de disco semelhante (/dev/sde1 - Observe que isso exige que você crie uma partição do tipo fd em /Dev/SDE antes de prosseguir) usando ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1
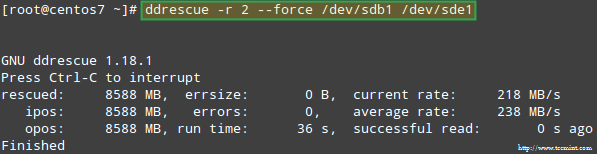 Recuperando o Array RAID
Recuperando o Array RAID Por favor, observe que até este ponto, não tocamos /dev/sdb ou /dev/sdd, as partições que faziam parte da matriz de ataque.
Agora vamos reconstruir a matriz usando /dev/sde1 e /dev/sdf1:
# mdadm --create /dev /md0 --LEvel = espelho --id-devices = 2 /dev /sd [e-f] 1
Observe que em uma situação real, você normalmente usa os mesmos nomes de dispositivos que na matriz original, ou seja,, /dev/sdb1 e /dev/sdc1 Depois que os discos fracassados foram substituídos por novos.
Neste artigo, escolhi usar dispositivos extras para recriar a matriz com novos discos e evitar confusão com as unidades falhas originais.
Quando perguntado se deve continuar escrevendo a matriz, digite Y e pressione Digitar. A matriz deve ser iniciada e você poderá observar seu progresso com:
# assista -n 1 gato /proc /mdstat
Quando o processo é concluído, você poderá acessar o conteúdo do seu ataque:
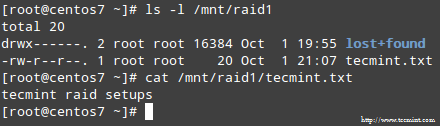 Confirme o conteúdo do RAID
Confirme o conteúdo do RAID Resumo
Neste artigo, analisamos como nos recuperar de ATAQUE falhas e perdas de redundância. No entanto, você precisa lembrar que essa tecnologia é uma solução de armazenamento e Não substitua backups.
Os princípios explicados neste guia se aplicam a todas as configurações de ataque, bem como aos conceitos que abordaremos no próximo e último guia desta série (Gerenciamento de Raid).
Se você tiver alguma dúvida sobre este artigo, fique à vontade para nos deixar uma nota usando o formulário de comentário abaixo. Estamos ansiosos para ouvir de você!
- « Como obter informações de hardware com comando dmidecode no Linux
- PowerLine - adiciona linhas de status poderosas e instruções ao editor Vim e Bash Terminal »