

Como persistir dados para pós -grausql em java
- 1799
- 122
- Mrs. Christopher Okuneva
Java é talvez a linguagem de programação mais usada hoje em dia. É robustez e natureza independente da plataforma permite que aplicativos baseados em Java funcionem principalmente em qualquer coisa. Como é o caso de qualquer aplicativo, precisamos armazenar nossos dados de alguma maneira confiável - essa necessidade chamou bancos de dados para a vida.
Nas conexões de banco de dados Java são implementadas pela JDBC (Java Banco de Dados API de conectividade), que permitem que o programador lide com diferentes tipos de bancos de dados da mesma maneira, o que facilita muito a nossa vida quando precisamos salvar ou ler dados de um banco de dados.
Neste tutorial, criaremos um exemplo de aplicativo Java que poderá se conectar a uma instância do banco de dados PostGresql e gravar dados nele. Para verificar se nossa inserção de dados é bem -sucedida, também implementaremos a leitura de volta e imprimiremos a tabela em que inserimos dados.
Neste tutorial, você aprenderá:
- Como configurar o banco de dados para o aplicativo
- Como importar o driver PostGresql JDBC para o seu projeto
- Como inserir dados no banco de dados
- Como executar uma consulta simples para ler o conteúdo de uma tabela de banco de dados
- Como imprimir dados buscados
Resultados da execução do aplicativo. Requisitos de software e convenções usadas
| Categoria | Requisitos, convenções ou versão de software usada |
|---|---|
| Sistema | Ubuntu 20.04 |
| Programas | NetBeans IDE 8.2, PostgreSql 10.12, JDK 1.8 |
| Outro | Acesso privilegiado ao seu sistema Linux como raiz ou através do sudo comando. |
| Convenções | # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de sudo comando$ - Requer que os comandos do Linux sejam executados como um usuário não privilegiado regular |
A configuração
Para os fins deste tutorial, precisamos apenas de uma estação de trabalho (desktop ou laptop) para instalar todos os componentes necessários. Não abordaremos a instalação do JDK, o NetBeans IDE ou a instalação do banco de dados PostgreSQL na máquina de laboratório. Assumimos que o banco de dados chamado ExampledB está em funcionamento e podemos conectar, ler e escrever usando a autenticação de senha, com as seguintes credenciais:
| Nome de usuário: | exemplo |
| Senha: | ExpletPass |
Este é um exemplo de configuração, use senhas fortes em um cenário do mundo real! O banco de dados está definido para ouvir no localHost, que será necessário quando construímos o JDBC URL de conexão.
O principal objetivo do nosso aplicativo é mostrar como escrever e ler no banco de dados; portanto, para as informações valiosas que estamos tão ansiosos para persistir, simplesmente escolheremos um número aleatório entre 1 e 1000 e armazenaremos essas informações com um único ID do cálculo e a hora exata em que os dados são registrados no banco de dados.
O ID e o tempo da gravação serão fornecidos pelo banco de dados, que vamos trabalhar apenas na questão real (fornecendo um número aleatório neste caso). Isso é de propósito, e abordaremos as possibilidades dessa arquitetura no final deste tutorial.
Configurando o banco de dados para o aplicativo
Temos um serviço de banco de dados em execução e um banco de dados chamado ExampledB Temos direitos para trabalhar com as credenciais acima mencionadas. Para ter um lugar onde podemos armazenar nossos dados preciosos (aleatórios), precisamos criar uma tabela e também uma sequência que fornecerá identificadores exclusivos de uma maneira conveniente. Considere o seguinte script SQL:
Crie sequência resultid_seq Iniciar com 0 incremento por 1 sem maxvalue minvalue 0 cache 1; altere sequence resultid_seq proprietário para exemplo o exemplo; Criar tabela calc_Results (Chave primária numérica resid NextVal ('ResultId_seq' :: Regclass), Result_Of_CalCulocation numérico não nulo, registro_date timestamp padrão agora ()); altere tabela calc_results proprietário para exemplo o exemplo; Essas instruções devem falar por si mesmas. Criamos uma sequência, definimos o proprietário para exemplo, Crie uma tabela chamada calc_results (representando "resultados de cálculo"), definido resid ser preenchido automaticamente com o próximo valor de nossa sequência em cada inserção e definir resultado_of_calculocation e data da gravação colunas que armazenarão nossos dados. Finalmente, o proprietário da mesa também está definido como exemplo.
Para criar esses objetos de banco de dados, mudamos para PostGres do utilizador:
$ sudo su - postgres
E execute o script (armazenado em um arquivo de texto chamado tabela_for_java.SQL) contra o ExampledB base de dados:
$ psql -d ExampledB < table_for_java.sql CREATE SEQUENCE ALTER SEQUENCE CREATE TABLE ALTER TABLE
Com isso, nosso banco de dados está pronto.
Importando o driver PostgreSQL JDBC para o projeto
Para construir o aplicativo, usaremos o NetBeans IDE 8.2. Os primeiros passos são trabalhos manuais. Escolhemos o menu Arquivo, criamos um novo projeto. Vamos deixar os padrões na próxima página do assistente, com categoria de "java" e projeto no "java Application". Vamos pressionar a seguir. Damos um nome ao aplicativo (e opcionalmente definimos um local não padrão). No nosso caso, será chamado persisttopostgres. Isso fará com que o IDE crie um projeto Java Base para nós.
No painel Projetos, clicamos com o botão direito do mouse em “Bibliotecas” e selecione “Adicionar biblioteca…”. Uma nova janela será exibida, onde pesquisamos e selecionamos o driver PostgreSQL JDBC e adicione -o como uma biblioteca.
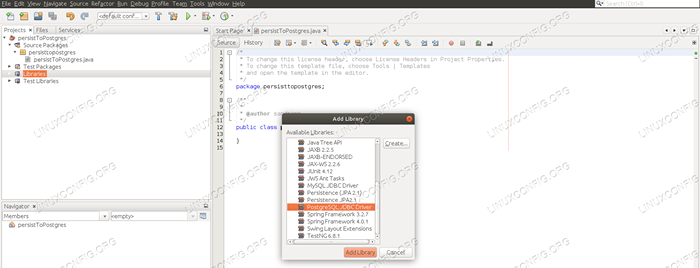 Adicionando o driver PostgreSQL JDBC ao projeto.
Adicionando o driver PostgreSQL JDBC ao projeto. Compreendendo o código -fonte
Agora adicionamos o seguinte código -fonte à classe principal do nosso aplicativo, Persisttopostgres:
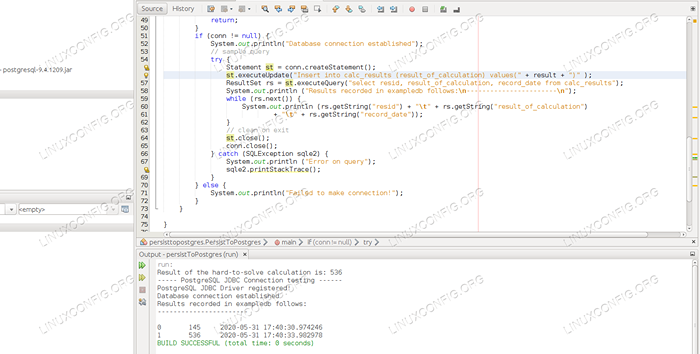
pacote persisttopostgres; importar java.SQL.Conexão; importar java.SQL.DriverManager; importar java.SQL.ResultSet; importar java.SQL.SqLexception; importar java.SQL.Declaração; importar java.util.simultâneo.Threadlocalrandom; classe pública persisttopostgres public static void main (string [] args) int resultado = threadlrandom.atual().NextInt (1, 1000 + 1); Sistema.fora.println ("O resultado do cálculo difícil de resolver é:" + resultado); Sistema.fora.println ("----- PostgreSQL JDBC Connection Testing ------"); tente classe.forname ("org.PostGresql.Driver "); Catch (ClassNotFoundException cnfe) Sistema.fora.Println ("Sem driver PostgreSQL JDBC no caminho da biblioteca!"); CNFE.printStackTrace (); retornar; Sistema.fora.Println ("Driver PostgreSQL JDBC registrado!"); Conexão conn = null; tente Conn = DriverManager.getConnection ("JDBC: PostGresql: // localhost: 5432/ExempledB", "ExempliSuser", "ExpletPass"); catch (sqlexception sqle) sistema.fora.println ("Falha na conexão! Verifique o console de saída "); sqle.printStackTrace (); retornar; if (Conn != null) sistema.fora.println ("conexão com o banco de dados estabelecida"); // Consulta de consulta Tente declaração st = Conn.createstatement (); st.ExecuteUpdate ("Inserir em Calc_Results (resultado_of_calculocation) valores (" + resultado + ")"); ResultSet Rs = ST.ExecuteQuery ("Selecione resid, resultado_of_calculation, registro_date de calc_results"); Sistema.fora.println ("Resultados registrados no ExampledB segue: \ n ------------------------- \ n"); while (Rs.próximo ()) sistema.fora.println (Rs.getString ("resid") + "\ t" + rs.getString ("resultado_of_calculocation") + "\ t" + rs.getString ("registro_date")); // Limpe na saída st.fechar(); Conn.fechar(); catch (sqlexception sqle2) sistema.fora.println ("Erro na consulta"); SQLE2.printStackTrace (); else sistema.fora.println ("Falha ao fazer a conexão!"); - Na linha 12, calculamos um número aleatório e o armazenamos no
resultadovariável. Este número representa o resultado de um cálculo pesado que
Precisamos armazenar no banco de dados. - Na linha 15, tentamos registrar o driver PostgreSQL JDBC. Isso resultará em um erro se o aplicativo não encontrar o motorista em tempo de execução.
- Na linha 26, construímos a sequência de conexão JDBC usando o nome do host em que o banco de dados está em execução (localhost), a porta que o banco de dados está ouvindo (5432, a porta padrão para postgreSQL), o nome do banco de dados (ExampledB) e as credenciais mencionadas no começo.
- Na linha 37, executamos o
insira dentro deDeclaração SQL que insere o valor doresultadovariável noresultado_of_calculocationcoluna docalc_resultsmesa. Especificamos apenas o valor dessas colunas únicas; portanto, os padrões se aplicam:residé buscado a partir da sequência nós
conjunto, edata da gravaçãopadrão paraagora(), qual é o horário do banco de dados no momento da transação. - Na linha 38, construímos uma consulta que retornará todos os dados contidos na tabela, incluindo nossa inserção na etapa anterior.
- Na linha 39, apresentamos os dados recuperados imprimindo-os de maneira semelhante à mesa, livres de recursos e saída.
Executando o aplicativo
Agora podemos limpar, construir e executar o persisttopostgres Aplicação, do próprio IDE, ou da linha de comando. Para correr do IDE, podemos usar o botão "Run Project" em cima. Para executá -lo da linha de comando, precisamos navegar para o dist diretório do projeto e invocar a JVM com o Jarra pacote como um argumento:
$ java -jar persisttopostgres.O resultado do JAR do cálculo difícil de resolver é: 173 ----- PostgreSQL JDBC Conexão Testing ------ Conexão de banco de dados Resultados estabelecidos registrados no ExampledB Seguindo: ------------- ---------- 0 145 2020-05-31 17:40:30.974246
As execuções da linha de comando fornecerão a mesma saída que o console do IDE, mas o mais importante aqui é que cada execução (seja da linha de comando IDE ou da linha de comando) inserirá outra linha em nossa tabela de banco de dados com o número aleatório que é calculado em cada cada correr.
É por isso que também veremos um número crescente de registros na saída do aplicativo: cada execução cresce a tabela com uma linha. Depois de algumas corridas, veremos uma longa lista de linhas de resultado na tabela.
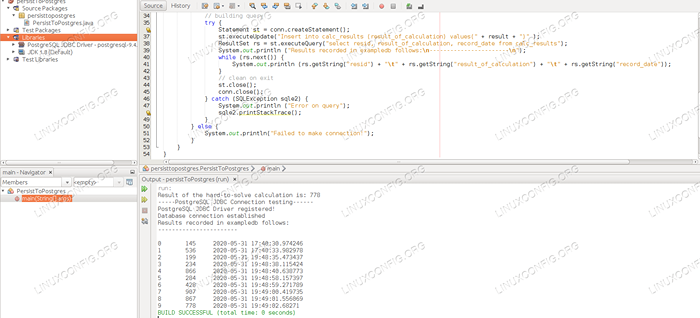 A saída do banco de dados mostra os resultados de cada execução do aplicativo.
A saída do banco de dados mostra os resultados de cada execução do aplicativo. Conclusão
Embora esse aplicativo simples dificilmente tenha uso do mundo real, é perfeito demonstrar alguns aspectos importantes importantes. Neste tutorial, dissemos que fazemos um cálculo importante com o aplicativo e inserimos um número aleatório a cada vez, porque o objetivo deste tutorial é mostrar como persistir os dados. Esse objetivo que concluímos: a cada execução, o aplicativo sai e os resultados dos cálculos internos seriam perdidos, mas o banco de dados preserva os dados.
Executamos o aplicativo de uma única estação de trabalho, mas se realmente precisaríamos resolver um cálculo complicado, precisaríamos alterar o URL do banco de dados para apontar para uma máquina remota executando o banco de dados, e poderíamos iniciar o cálculo em vários computadores Ao mesmo tempo, criando centenas ou milhares de instâncias desse aplicativo, talvez resolvendo pequenos pedaços de um quebra planejamento.
Por que o planejamento é necessário? Para ficar com este exemplo: se não deixarmos de atribuir identificadores de linha ou registro de data e hora ao banco de dados, nosso aplicativo teria sido muito maior, muito mais lento e muito mais cheio de bugs - alguns deles apenas aparecem quando executamos duas instâncias da instância do Aplicação no mesmo momento.
Tutoriais do Linux relacionados:
- Ubuntu 20.04 Instalação PostGresql
- Ubuntu 22.04 Instalação PostGresql
- Como impedir a verificação de conectividade do NetworkManager
- Coisas para instalar no Ubuntu 20.04
- Como trabalhar com a API de Rest WooCommerce com Python
- Como verificar a duração da bateria no Ubuntu
- Programador EEPROM CH341A - Leia e escreva dados para chip…
- Coisas para instalar no Ubuntu 22.04
- Oracle Java Instalação no Ubuntu 20.04 fossa focal linux
- Como instalar Java no Manjaro Linux