

Como executar operações de auto-cicatrizes e re-equilíbrio no sistema de arquivos Gluster-Parte 2
- 4988
- 780
- Robert Wunsch DVM
No meu artigo anterior sobre 'Introdução ao Glusterfs (sistema de arquivos) e instalação - Parte 1' foi apenas uma breve visão geral do sistema de arquivos e suas vantagens que descrevem alguns comandos básicos. Vale a pena mencionar sobre os dois recursos importantes, Auto cura e Re-equilíbrio, neste artigo sem a qual explicação Glusterfs não será utido. Vamos nos familiarizar com os termos Auto cura e Re-equilíbrio.
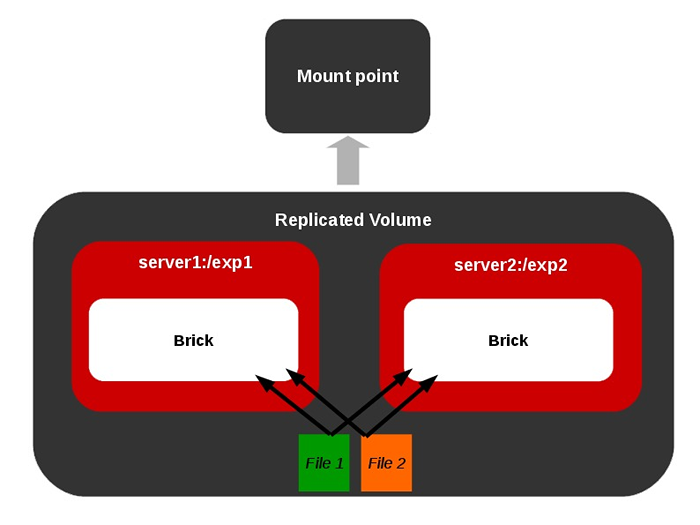
O que queremos dizer com auto-cura em volumes replicados?
Este recurso está disponível para volumes replicados. Suponha que tenhamos um volume replicado [Réplica mínima contagem 2]. Suponha que, devido a algumas falhas, uma ou mais tijolos entre as réplicas caem por um tempo e o usuário exclua um arquivo do ponto de montagem que será afetado apenas no tijolo online.
Quando o tijolo offline fica online mais tarde, é necessário remover esse arquivo deste tijolo.e. Uma sincronização entre os tijolos de réplica chamada como cura deve ser feita. O mesmo acontece com a criação/modificação de arquivos em tijolos offline. Glusterfs tem um daemon de auto-cura embutido para cuidar dessas situações sempre que os tijolos ficam online.
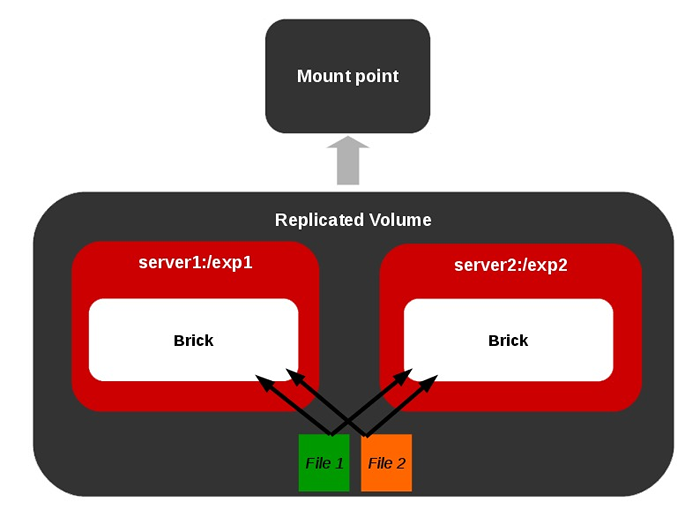 Volume replicado
Volume replicado O que queremos dizer com reequilibrar?
Considere um volume distribuído com apenas um tijolo. Por exemplo, nós Crie 10 arquivos no volume através do Mount Point. Agora todos os arquivos estão residindo no mesmo tijolo, pois há apenas tijolos no volume. Ao adicionar mais um tijolo ao volume, podemos ter que reequilibrar o número total de arquivos entre os dois tijolos. Se um volume for expandido ou encolhido em glusterfs, os dados precisam ser re-equilibrados entre os vários tijolos incluídos no volume.
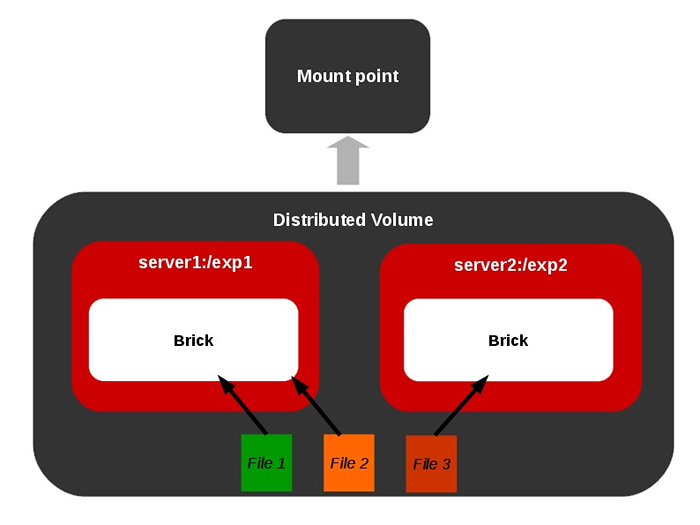 Volume distribuído
Volume distribuído Executando a auto-cura em Glusterfs
1. Crie um volume replicado usando o seguinte comando.
$ GLUSTER VOLUME CREATE VOL REPLICA 2 192.168.1.16:/Home/A 192.168.1.16:/Home/B
Observação: A criação de um volume replicado com tijolos no mesmo servidor pode levantar um aviso para o qual você deve prosseguir ignorando o mesmo.
2. Iniciar e montar o volume.
$ GLUSTER VOLUME START VOL $ MOUNT -T GLUSTERFS 192.168.1.16:/vol/mnt/
3. Crie um arquivo do Mount Point.
$ touch /mnt /foo
4. Verifique o mesmo em duas réplicas de tijolos.
$ ls/home/a/foo $ ls/home/b/foo
5. Agora envie um dos tijolos offline matando o daemon Glusterfs correspondente usando o PID Recebi informações de status de volume.
$ GLUSTER VOLUME STATUS VOL
Saída de amostra
Status do volume: Vol Gluster Process Port Online PID ---------------------------------------------------- -------------------------------------- Tijolo 192.168.1.16:/Home/A 49152 y 3799 Brick 192.168.1.16:/Home/B 49153 Y 3810 Servidor NFS no LocalHost 2049 Y 3824 Daemon Auto-Heal On localhost N/A Y 3829
Observação: Veja a presença de daemon de auto-cura no servidor.
$ Kill 3810
$ GLUSTER VOLUME STATUS VOL
Saída de amostra
Status do volume: Vol Gluster Process Port Online PID ---------------------------------------------------- -------------------------------------- Tijolo 192.168.1.16:/Home/A 49152 y 3799 Brick 192.168.1.16:/Home/B N/A N N/A NFS servidor no LocalHost 2049 Y 3824 Daemon Auto-Heal On Localhost N/A Y 3829
Agora o segundo tijolo está offline.
6. Exclua o arquivo foo de Mount Point e verifique o conteúdo do tijolo.
$ rm -f /mnt /foo $ ls /home /a $ ls /home /b foo
Você vê foo ainda está lá em segundo tijolo.
7. Agora traga de volta o tijolo online.
$ GLUSTER VOLUME Start Vol Force $ GLUSTER VOLUME STATUS VOL VOL
Saída de amostra
Status do volume: Vol Gluster Process Port Online PID ---------------------------------------------------- -------------------------------------- Tijolo 192.168.1.16:/Home/A 49152 y 3799 Brick 192.168.1.16:/Home/B 49153 Y 4110 Servidor NFS no LocalHost 2049 Y 4122 Daemon Auto-Heal On localhost N/A Y 4129
Agora o tijolo está online.
8. Verifique o conteúdo dos tijolos.
$ ls/home/a/$ ls/home/b/
O arquivo foi removido do segundo tijolo pelo daemon de auto-cura.
Observação: No caso de arquivos maiores, pode demorar um pouco para que a operação de auto-cura seja feita com sucesso. Você pode verificar o status da cura usando o seguinte comando.
$ GLUSTER VOLUME Cura VOL Info
Realizando o re-equilíbrio em Glusterfs
1. Crie um volume distribuído.
$ GLUSTER CREATE VOLUME DISTRIBUTE 192.168.1.16:/Home/C
2. Iniciar e montar o volume.
$ GLUSTER VOLUME COMPARTIR DISTIBUE $ MONTE -T GLUSTERFS 192.168.1.16:/distribuir/mnt/
3. Crie 10 arquivos.
$ touch /mnt /arquivo 1… 10 $ ls /mnt /file1 file10 file2 file3 file4 file5 file6 file7 file7 file9 file9 $ ls /home /c file1 file10 file2 file3 file4 file5 file6 file7 file7 file9
4. Adicione outro tijolo ao volume distribuir.
$ GLUSTER VOLUME ADD-BRICK DISTRIBIÇÃO 192.168.1.16:/Home/D $ LS/Home/D
5. Re-equilibrar.
$ GLUSTER VOLUME DE REBALAÇÃO Distribuir o volume inicial reequilíbrio: Distribua: Sucesso: Iniciando o reequilíbrio na distribuição de volume foi bem -sucedida.
6. Verifique o conteúdo.
$ ls /home /c file1 file2 file5 arquivo6 arquivo8 $ ls /home /d file10 file3 file4 file7 file9
Os arquivos foram re-equilibrados.
Observação: Você pode verificar o status de reequilíbrio emitindo o seguinte comando.
$ GLUSTER VOLUME VOLUME DISTIBO STATUS
Saída de amostra
Nó Falhas de tamanho renascida falhas digitalizadas STATUS STATUS TEMPO NO SECS --------- ----------- ------------------------ ----------- ------- -------- ----------------- Localhost 5 0Bytes 15 0 0 Concluído 1.00 Rebalance de volume: Distribua: Sucesso:
Com isso, pretendo concluir esta série no Glusterfs. Sinta-se à vontade para comentar aqui com suas dúvidas sobre os recursos de auto-curas e re-equilíbrio.
- « FDUPES - Uma ferramenta de linha de comando para encontrar e excluir arquivos duplicados no Linux
- Tudo o que você precisa saber sobre processos no Linux [Guia abrangente] »