

Como monitorar o uso do sistema, interrupções e solucionar problemas de servidores Linux - Parte 9

- 1570
- 127
- Mrs. Willie Beahan
Embora o Linux seja muito confiável, os administradores sábios do sistema devem encontrar uma maneira de ficar de olho no comportamento e na utilização do sistema o tempo todo. Garantindo um tempo de atividade o mais próximo 100% o quanto possível e a disponibilidade de recursos são necessidades críticas em muitos ambientes. Examinar o status passado e atual do sistema nos permitirá prever e provavelmente impedirá possíveis problemas.
 Engenheiro Certificado da Fundação Linux - Parte 9
Engenheiro Certificado da Fundação Linux - Parte 9 Apresentando o Programa de Certificação da Fundação Linux
Neste artigo, apresentaremos uma lista de algumas ferramentas disponíveis na maioria das distribuições upstream para verificar o status do sistema, analisar interrupções e solucionar problemas de problemas em andamento. Especificamente, da infinidade de dados disponíveis, focaremos na CPU, espaço de armazenamento e utilização de memória, gerenciamento básico de processos e análise de logs.
Utilização do espaço de armazenamento
Existem 2 comandos bem conhecidos no Linux que são usados para inspecionar o uso do espaço de armazenamento: df e du.
O primeiro, df (que significa sem disco), é normalmente usado para relatar o uso geral do espaço em disco pelo sistema de arquivos.
Exemplo 1: Relatando o uso de espaço em disco em bytes e formato legível pelo homem
Sem opções, df relata o uso do espaço em disco em bytes. Com o -h sinalizador ele exibirá as mesmas informações usando MB ou GB em vez disso. Observe que este relatório também inclui o tamanho total de cada sistema de arquivos (em blocos 1-K), os espaços gratuitos e disponíveis e o ponto de montagem de cada dispositivo de armazenamento.
# df # df -h
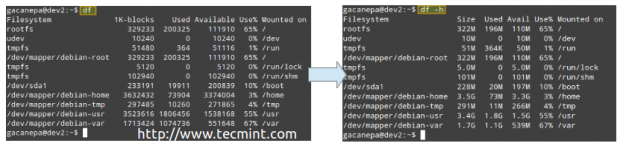 Utilização do espaço em disco
Utilização do espaço em disco Isso certamente é bom - mas há outra limitação que pode tornar inutilizável um sistema de arquivos, e isso está ficando sem inodos. Todos os arquivos em um sistema de arquivos são mapeados para um inode que contém seus metadados.
Exemplo 2: Inspecionando o uso de inode por sistema de arquivos em formato legível pelo homem com
# df -hti
Você pode ver a quantidade de inodos usados e disponíveis:
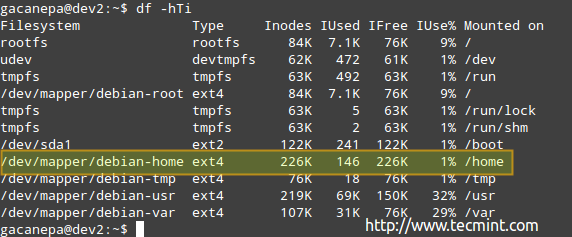 Inode uso de disco
Inode uso de disco De acordo com a imagem acima, existem 146 inodes usados (1%) In /Home, o que significa que você ainda pode criar arquivos 226k nesse sistema de arquivos.
Exemplo 3: Encontrar e / ou excluir arquivos e diretórios vazios
Observe que você pode ficar sem espaço de armazenamento muito antes de ficar sem inodos e vice-versa. Por esse motivo, você precisa monitorar não apenas a utilização do espaço de armazenamento, mas também o número de inodos usados pelo sistema de arquivos.
Use os seguintes comandos para encontrar arquivos ou diretórios vazios (que ocupam 0b) que estão usando inodes sem motivo:
# find /home -Type f -epty # find /home -Type d -epty
Além disso, você pode adicionar o -excluir Sinalize no final de cada comando, se você também desejar excluir esses arquivos e diretórios vazios:
# find /home -Type f -epty - -Delete # Find /Home -Type F -Oppy
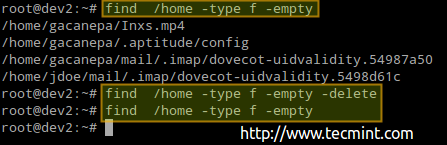 Encontre e exclua arquivos vazios no Linux
Encontre e exclua arquivos vazios no Linux O procedimento anterior excluiu 4 arquivos. Vamos verificar novamente o número de nós usados / disponíveis novamente em / home:
# df -hti | Grep Home
 Verifique o uso do linux inode
Verifique o uso do linux inode Como você pode ver, há 142 INODES usados agora (4 a menos do que antes).
Exemplo 4: Examinando o uso do disco por diretório
Se o uso de um determinado sistema de arquivos estiver acima de uma porcentagem predefinida, você pode usar du (abreviação de uso do disco) para descobrir quais são os arquivos que estão ocupando mais espaço.
O exemplo é dado para /var, que você pode ver na primeira imagem acima, é usado em seus 67%.
# du -sch /var /*
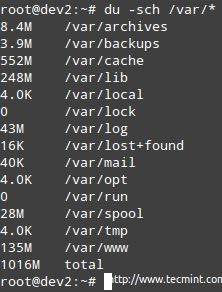 Verifique o uso do espaço do disco por diretório
Verifique o uso do espaço do disco por diretório Observação: Que você pode mudar para qualquer um dos subdiretórios acima para descobrir exatamente o que está neles e quanto cada item ocupa. Você pode usar essas informações para excluir alguns arquivos se não houver necessários ou estender o tamanho do volume lógico, se necessário.
Leia também
- 12 comandos “df” úteis para verificar o espaço do disco
- 10 comandos úteis "DU" para encontrar o uso de disco de arquivos e diretórios
Utilização de memória e CPU
A ferramenta clássica no Linux usada para executar uma verificação geral da utilização da CPU / memória e gerenciamento de processos é o comando principal. Além disso, o Top exibe uma visão em tempo real de um sistema em execução. Existem outras ferramentas que poderiam ser usadas para o mesmo objetivo, como o HTOP, mas eu me contestei para o TOP porque está instalado para fora da caixa em qualquer distribuição do Linux.
Exemplo 5: Exibindo um status ao vivo do seu sistema com o topo
Para iniciar o topo, basta digitar o seguinte comando em sua linha de comando e pressionar Enter.
# principal
Vamos examinar uma saída superior típica:
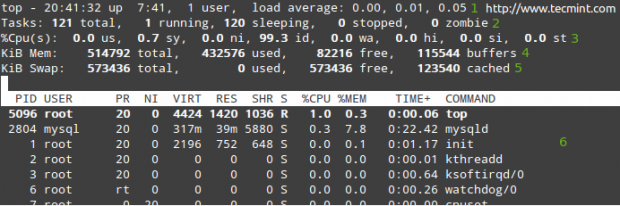 Liste todos os processos em execução no Linux
Liste todos os processos em execução no Linux Nas linhas 1 a 5, as seguintes informações são exibidas:
1. A hora atual (20:41:32) e tempo de atividade (7 horas e 41 minutos). Apenas um usuário está conectado ao sistema e a média de carga durante os últimos 1, 5 e 15 minutos, respectivamente. 0.00, 0.01 e 0.05 Indique que, durante esses intervalos de tempo, o sistema estava ocioso por 0% do tempo (0.00: Nenhum processo estava esperando pela CPU), ela foi sobrecarregada por 1% (0.01: uma média de 0.01 Processos estavam esperando a CPU) e 5% (0.05). Se menos de 0 e menor o número (0.65, por exemplo), o sistema ficou ocioso por 35% durante os últimos 1, 5 ou 15 minutos, dependendo de 0.65 aparece.
2. Atualmente, existem 121 processos em execução (você pode ver a listagem completa em 6). Apenas 1 deles está funcionando (no topo neste caso, como você pode ver na coluna %da CPU) e os 120 restantes estão esperando em segundo plano, mas estão "dormindo" e permanecerão nesse estado até que os chamamos. Como? Você pode verificar isso abrindo um prompt do mysql e executa algumas consultas. Você notará como o número de processos em execução aumenta.
Como alternativa, você pode abrir um navegador da web e navegar para qualquer página que esteja sendo servida pelo Apache e você obterá o mesmo resultado. Obviamente, esses exemplos assumem que ambos os serviços estão instalados em seu servidor.
3. Us (tempo executando processos de usuário com prioridade não modificada), SY (tempo executando processos de kernel), NI (tempo executando processos de usuário com prioridade modificada), WA (tempo aguardando a conclusão de E/S), oi (tempo gasto em manutenção de interrupções de hardware), SI (tempo gasto em serviço de interrupções no software), ST (tempo roubado da VM atual pelo hipervisor - apenas em ambientes virtualizados).
4. Uso da memória física.
5. Troque o uso do espaço.
Exemplo 6: Inspecionando o uso da memória física
Para inspecionar a memória da RAM e o uso de troca, você também pode usar livre comando.
# livre
 Verifique o uso da memória Linux
Verifique o uso da memória Linux Claro que você também pode usar o -m (MB) ou -g (GB) muda para exibir as mesmas informações em forma legível pelo homem:
# grátis -m
 Veja o uso da memória Linux
Veja o uso da memória Linux De qualquer maneira, você precisa estar ciente do fato de que o kernel se reserva o máximo de memória possível e o disponibiliza para processos quando solicitar. Particularmente, o “-/+ buffers/cache”A linha mostra os valores reais após esse cache de E/S é levada em consideração.
Em outras palavras, a quantidade de memória usada pelos processos e a quantidade disponível para outros processos (neste caso, 232 MB usado e 270 MB disponível, respectivamente). Quando os processos precisam dessa memória, o kernel diminui automaticamente o tamanho do cache de E/S.
Leia também: 10 comando “gratuito” útil para verificar o uso da memória do Linux
Analisando mais de perto os processos
A qualquer momento, existem muitos processos em execução em nosso sistema Linux. Existem duas ferramentas que usaremos para monitorar de perto os processos: ps e PSTEE.
Exemplo 7: Exibindo toda a lista de processos em seu sistema com PS (formato padrão completo)
Usando o -e e -f opções combinadas em um (-ef) Você pode listar todos os processos que estão em execução atualmente em seu sistema. Você pode colocar essa saída para outras ferramentas, como grep (Conforme explicado na Parte 1 da série LFCS) para restringir a saída ao processo (s) desejado (s):
# ps -ef | grep -i lula | grep -v grep
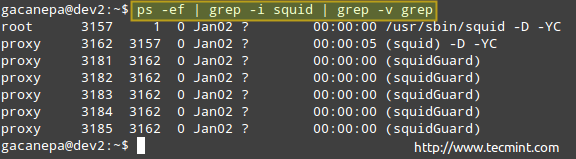 Processos de monitoramento no Linux
Processos de monitoramento no Linux A lista de processos acima mostra as seguintes informações:
Proprietário do processo, PID, PID pai (o processo pai), utilização do processador, tempo em que o comando começou, tty (o ? indica que é um daemon), o tempo acumulado da CPU e o comando associado ao processo.
Exemplo 8: Personalização e classificação da saída de ps
No entanto, talvez você não precise de toda essa informação e gostaria de mostrar ao proprietário do processo, o comando que a iniciou, seu PID e PPID e a porcentagem de memória que ele está usando atualmente - nessa ordem, e classificar por Uso da memória em ordem decrescente (observe que o PS por padrão é classificado pelo PID).
# PS -EO Usuário, Comm, Pid, PPID,%Mem -Sort -%Mem
Onde o sinal menos na frente de %Mem indica a classificação em ordem decrescente.
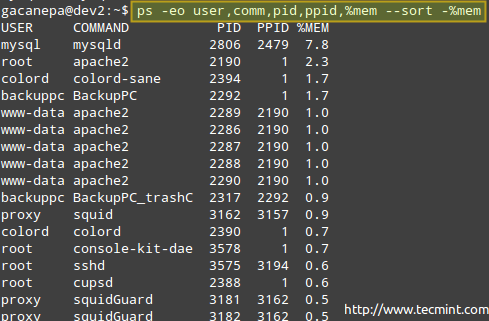 Monitore o uso da memória do processo Linux
Monitore o uso da memória do processo Linux Se, por algum motivo. Outras razões pelas quais você consideraria fazer isso é quando você iniciou um processo em primeiro plano, mas deseja pausar e retomar em segundo plano.
| Nome do sinal | Número do sinal | Descrição |
| Sigterm | 15 | Mate o processo graciosamente. |
| Sigint | 2 | Este é o sinal que é enviado quando pressionamos Ctrl + C. Ele pretende interromper o processo, mas o processo pode ignorá -lo. |
| Sigkill | 9 | Esse sinal também interrompe o processo, mas o faz incondicionalmente (use com cuidado!) como um processo não pode ignorá -lo. |
| Sighup | 1 | Abrevante para "Deslocando", esses sinais instruem Daemons a reler seu arquivo de configuração sem realmente interromper o processo. |
| Sigtstp | 20 | Pausar a execução e esperar pronta para continuar. Este é o sinal que é enviado quando digitamos a combinação de chave ctrl + z. |
| Sigstop | 19 | O processo é pausado e não recebe mais atenção dos ciclos da CPU até que seja reiniciado. |
| Sigcont | 18 | Este sinal diz ao processo para retomar a execução depois de ter recebido Sigtstp ou Sigstop. Este é o sinal que é enviado pelo shell quando usamos os comandos FG ou BG. |
Exemplo 9: Pussando a execução de um processo em execução e retomando -o em segundo plano
Quando a execução normal de um determinado processo implica que nenhuma saída será enviada para a tela enquanto estiver em execução, você pode iniciá -lo em segundo plano (anexando um ampérs e no final do comando).
nome do processo &
ou,
Depois de começar a correr em primeiro plano, faça uma pausa e envie -o para o fundo com
Ctrl + z
# Kill -18 pid
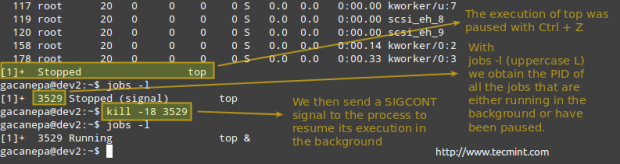 Processo de matar no Linux
Processo de matar no Linux Exemplo 10: Killing By Force A Process “Gone Wild”
Observe que cada distribuição fornece ferramentas para parar / iniciar / reiniciar / recarregar serviços comuns, como serviço em sistemas baseados em SYSV ou SystemCtl em sistemas baseados em SystemD.
Se um processo não responder a esses utilitários, você pode matá -lo pela força enviando o sinal Sigkill.
# ps -ef | Grep Apache # Kill -9 3821
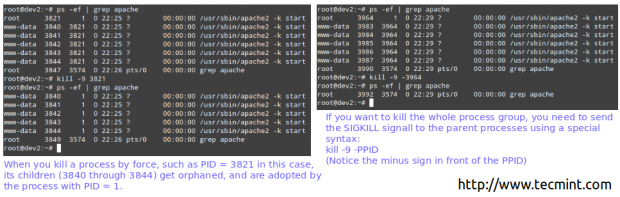 Matar com força o processo Linux
Matar com força o processo Linux Então ... o que aconteceu / está acontecendo?
Quando houve algum tipo de interrupção no sistema (seja uma queda de energia, uma falha de hardware, uma interrupção planejada ou não planejada de um processo ou qualquer anormalidade), os logs in /var/log são seus melhores amigos para determinar o que aconteceu ou o que poderia estar causando os problemas que você está enfrentando.
# cd /var /log
 Veja os logs do Linux
Veja os logs do Linux Alguns dos itens em /var/log são arquivos de texto regulares, outros são diretórios e outros são arquivos compactados de logs girados (históricos). Você vai querer verificar aqueles com a palavra erro em seu nome, mas inspecionar o resto pode ser útil também.
Exemplo 11: Examinando logs para erros nos processos
Imagine este cenário. Seus clientes LAN não conseguem imprimir para impressoras de rede. O primeiro passo para solucionar essa situação vai /var/log/cops diretório e veja o que está lá.
Você pode usar o cauda comando para exibir as últimas 10 linhas do arquivo error_log, ou Tail -f error_log Para uma visão em tempo real do log.
# cd/var/log/cops # ls # Tail Error_log
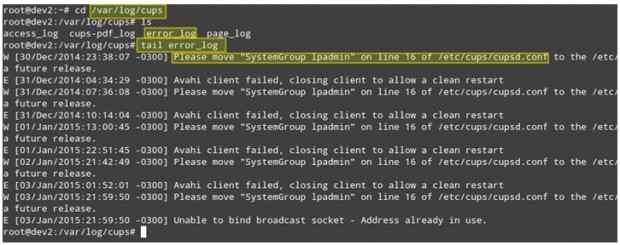 Monitore arquivos de log em tempo real
Monitore arquivos de log em tempo real A captura de tela acima fornece algumas informações úteis para entender o que poderia estar causando seu problema. Observe que, seguindo as etapas ou a correção do mau funcionamento do processo, ainda pode não resolver o problema geral, mas se você for usado desde o início para verificar os troncos toda vez que surgir um problema (seja um local ou uma rede) você) você 'estarei definitivamente no caminho certo.
Exemplo 12: Examinando os logs para falhas de hardware
Embora falhas de hardware possam ser difíceis de solucionar problemas, você deve verificar o DMESG e mensagens registram e grep para palavras relacionadas a uma parte de hardware presumida com defeito.
A imagem abaixo é tirada de /var/log/mensagens Depois de procurar a palavra erro usando o seguinte comando:
# menos/var/log/mensagens | ERRO GREP -I
Podemos ver que estamos tendo um problema com dois dispositivos de armazenamento: /dev/sdb e /dev/sdc, que, por sua vez, causam um problema com a matriz RAID.
 Solução de problemas de problemas de Linux
Solução de problemas de problemas de Linux Conclusão
Neste artigo, exploramos algumas das ferramentas que podem ajudá -lo a estar sempre ciente do status geral do seu sistema. Além disso, você precisa garantir que seu sistema operacional e pacotes instalados sejam atualizados para suas mais recentes versões estáveis. E nunca, nunca, esqueça de verificar os logs! Então você estará indo na direção certa para encontrar a solução definitiva para qualquer problema.
Sinta -se à vontade para deixar seus comentários, sugestões ou perguntas - se você tiver qualquer coisa - usando o formulário abaixo.
Torne -se um engenheiro certificado Linux- « Como configurar um repositório de rede para instalar ou atualizar pacotes - Parte 11
- Como configurar um firewall iptables para permitir o acesso remoto aos serviços no Linux - Parte 8 »