

Como instalar Kafka no Rhel 8
- 2501
- 131
- Loren Botsford
Apache Kafka é uma plataforma de streaming distribuída. Com o seu rico conjunto de API (interface de programação de aplicativos), podemos conectar principalmente qualquer coisa a Kafka como fonte de dados e, por outro lado, podemos configurar um grande número de consumidores que receberão o vapor de registros para processamento. Kafka é altamente escalável e armazena os fluxos de dados de maneira confiável e tolerante a falhas. Do ponto de vista da conectividade, Kafka pode servir como uma ponte entre muitos sistemas heterogêneos, que por sua vez podem confiar em seus recursos para transferir e persistir os dados fornecidos.
Neste tutorial, instalaremos o Apache Kafka em um Red Hat Enterprise Linux 8, criaremos o Systemd arquivos da unidade para facilitar o gerenciamento e testar a funcionalidade com as ferramentas de linha de comando enviadas.
Neste tutorial, você aprenderá:
- Como instalar Apache Kafka
- Como criar serviços Systemd para Kafka e Zookeeper
- Como testar Kafka com clientes de linha de comando
Consumindo mensagens no tópico Kafka da linha de comando. Requisitos de software e convenções usadas
| Categoria | Requisitos, convenções ou versão de software usada |
|---|---|
| Sistema | Red Hat Enterprise Linux 8 |
| Programas | Apache Kafka 2.11 |
| Outro | Acesso privilegiado ao seu sistema Linux como raiz ou através do sudo comando. |
| Convenções | # - requer que os comandos Linux sejam executados com privilégios root diretamente como usuário root ou por uso de sudo comando$ - Requer que os comandos do Linux sejam executados como um usuário não privilegiado regular |
Como instalar Kafka no Redhat 8 Instruções passo a passo
Apache Kafka está escrito em Java, então tudo o que precisamos é OpenJdk 8 instalado para prosseguir com a instalação. Kafka confia no Apache Zoookeeper, um serviço de coordenação distribuído, que também é escrito em Java e é enviado com o pacote que baixaremos. Ao instalar serviços de HA (alta disponibilidade) em um único nó, mata seu objetivo, instalaremos e executaremos o Zookeeper pelo bem de Kafka.
- Para baixar Kafka do espelho mais próximo, precisamos consultar o site oficial de download. Podemos copiar o URL do
.alcatrão.gzarquivo a partir daí. Usaremoswget, e o URL colado para baixar o pacote para a máquina de destino:# wget https: // www-eu.apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz -o /opt /kafka_2.11-2.1.0.TGZ
- Nós entramos no
/optardiretório e extraia o arquivo:# cd /opt # tar -xvf kafka_2.11-2.1.0.TGZ
E crie um symblink chamado
/opt/kafkaIsso aponta para o agora criado/opt/kafka_2_11-2.1.0diretório para facilitar nossas vidas.ln -s /opt /kafka_2.11-2.1.0 /opt /kafka
- Criamos um usuário não privilegiado que executará os dois
funcionário do zoológicoeKafkaserviço.# userAdd kafka
- E defina o novo usuário como proprietário de todo o diretório que extraímos, recursivamente:
# chown -r kafka: kafka /opt /kafka*
- Criamos o arquivo da unidade
/etc/Systemd/System/Zookeeper.serviçoCom o seguinte conteúdo:
cópia de[Unidade] Descrição = Zookeeper depois = syslog.rede de destino.Target [Service] TIPO = Usuário simples = Kafka Group = Kafka ExecStart =/Opt/Kafka/Bin/Zookeeper-Server-Start.sh/opt/kafka/config/zookeeper.Propriedades exectop =/opt/kafka/bin/zookeeper-server-stop.sh [install] wantedby = multiususer.alvoObserve que não precisamos escrever o número da versão três vezes por causa do symlink que criamos. O mesmo se aplica ao próximo arquivo de unidade para Kafka,
/etc/Systemd/System/Kafka.serviço, que contém as seguintes linhas de configuração:
cópia de[Unidade] Descrição = Apache Kafka requer = Zookeeper.Serviço depois = Zookeeper.Serviço [Serviço] Tipo = Usuário simples = Kafka Group = Kafka ExecStart =/Opt/Kafka/Bin/Kafka-Server-Start.sh/opt/kafka/config/servidor.Propriedades exectop =/opt/kafka/bin/kafka-server-stop.sh [install] wantedby = multiususer.alvo - Precisamos recarregar
SystemdPara obtê -lo, leia os novos arquivos da unidade:
# Systemctl Daemon-Reload
- Agora podemos iniciar nossos novos serviços (nesta ordem):
# SystemCtl Iniciar o Zookeeper # SystemCtl Iniciar Kafka
Se tudo correr bem,
Systemddeve relatar o estado em execução sobre o status de ambos os serviços, semelhante às saídas abaixo:# Systemctl Status Zookeeper.Serviço Zookeeper.Serviço - Zookeeper Carregado: Carregado (/etc/Systemd/System/Zookeeper.serviço; desabilitado; Preset do fornecedor: desativado) Ativo: ativo (em execução) desde quinta-feira, 2019-01-10 20:44:37 CET; 6 anos atrás PID principal: 11628 (Java) Tarefas: 23 (Limite: 12544) Memória: 57.0m CGROUP: /Sistema.fatia/zookeeper.Serviço 11628 java -xmx512m -xms512m -server […] # status do sistema Kafka.serviço kafka.Serviço - Apache Kafka Carregado: Carregado (/etc/Systemd/System/Kafka.serviço; desabilitado; Preset do fornecedor: desativado) ativo: ativo (em execução) desde quinta-feira 2019-01-10 20:45:11 CET; 11s atrás PID principal: 11949 (Java) Tarefas: 64 (Limite: 12544) Memória: 322.2M CGROUP: /sistema.Slice/Kafka.Serviço 11949 Java -xmx1g -xms1g -server […]
- Opcionalmente, podemos ativar o início automático de inicialização para os dois serviços:
# SystemCtl Ativar Zookeeper.Serviço # SystemCtl Ativar Kafka.serviço
- Para testar a funcionalidade, nos conectaremos a Kafka com um produtor e um cliente de consumo. As mensagens fornecidas pelo produtor devem aparecer no console do consumidor. Mas antes disso, precisamos de um meio, essas duas mensagens de troca em. Criamos um novo canal de dados chamados
temaNos termos de Kafka, onde o provedor publicará e onde o consumidor se inscreverá. Vamos chamar o tópicoFirstKafkatópica. Usaremos oKafkaUsuário para criar o tópico:$/opt/kafka/bin/kafka-topics.sh --create-zookeeper localhost: 2181-replicação-fator 1-Partições 1-Topic FirstKAfkatópico
- Iniciamos um cliente de consumo da linha de comando que se inscreverá no tópico (neste momento vazio) criado na etapa anterior:
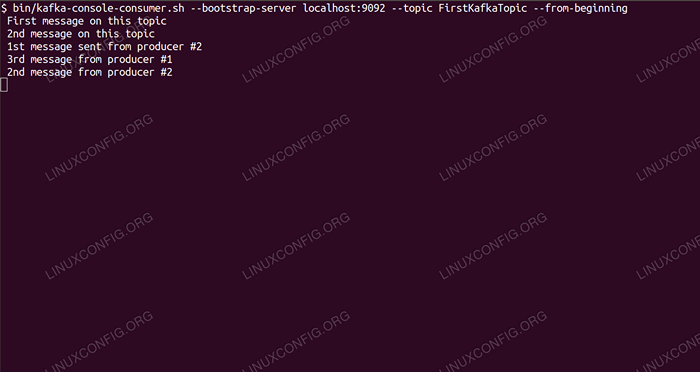
$/opt/kafka/bin/kafka-consumidor.SH-LocalHost de servidor sh-Bootstrap: 9092 --Tópico FirstKafkatopic --do começo
Deixamos o console e o cliente em execução aberta. Este console é onde receberemos a mensagem que publicamos com o cliente produtor.
- Em outro terminal, iniciamos um cliente produtor e publicamos algumas mensagens no tópico que criamos. Podemos consultar Kafka para tópicos disponíveis:
$/opt/kafka/bin/kafka-topics.sh -lista -zookeeper localhost: 2181 FirstKafkatópica
E conecte -se ao que o consumidor está assinado e envie uma mensagem:
$/opt/kafka/bin/kafka-console-produtor.SH-LocalHost de Lista de Broker: 9092-Topic FirstKafkatópica> Nova mensagem publicada pelo produtor do Console #2
No terminal do consumidor, a mensagem deve aparecer em breve:
$/opt/kafka/bin/kafka-consumidor.Shost local de SH --Bootstrap-Server: 9092-Topic FirstKafkatopic-Novo mensagem que assinou o produtor do Console #2
Se a mensagem aparecer, nosso teste será bem -sucedido e nossa instalação Kafka está funcionando como pretendido. Muitos clientes poderiam fornecer e consumir um ou mais registros de tópicos da mesma maneira, mesmo com uma única configuração de nós que criamos neste tutorial.
Tutoriais do Linux relacionados:
- Como usar redes em ponte com LibVirt e KVM
- Coisas para instalar no Ubuntu 20.04
- Como impedir a verificação de conectividade do NetworkManager
- Como instalar o Steam no Ubuntu 22.04 Jammy Jellyfish Linux
- Uma introdução à automação, ferramentas e técnicas do Linux
- Como usar o ADB Android Debug Bridge para gerenciar seu Android…
- Mastering Bash Script Loops
- Loops aninhados em scripts de basquete
- Ubuntu 20.04 WordPress com instalação do Apache
- Como trabalhar com a API de Rest WooCommerce com Python