

Como instalar o cluster Elasticsearch (Multi Node) no CentOS/Rhel, Ubuntu e Debian

- 787
- 165
- Arnold Murray
Elasticsearch é flexível e poderoso código aberto, pesquisa em tempo real distribuída e mecanismo analítico. Usando um conjunto simples de APIs, ele fornece a capacidade de pesquisa de texto completo. A pesquisa elástica está disponível gratuitamente sob a licença Apache 2, que fornece mais flexibilidade.
Este artigo o ajudará a configurar o Elasticsearch Multi Node Cluster nos sistemas Centos, Rhel, Ubuntu e Debian. No Elasticsearch Multi Node Cluster está apenas configurando vários clusters de nós únicos com o mesmo nome de cluster na mesma rede.
Cenário de rede
Temos três servidores com os seguintes IPs e nomes de hosts. Todo o servidor está em execução na mesma LAN e tem acesso total um ao outro, usando o IP e o nome do host ambos.
192.168.10.101 Node_1 192.168.10.102 Node_2 192.168.10.103 Node_3
Verifique Java (todos os nós)
Java é o principal requisito para a instalação do Elasticsearch. Portanto, verifique se você está instalado em Java em todos os nós.
# java -version java versão "1.8.0_31 "Java (TM) SE Ambiente de tempo de execução (Build 1.8.0_31-B13) Java Hotspot (TM) de 64 bits VM (Build 25.31-B07, modo misto)
Se você não tiver Java instalado em nenhum sistema de nó, use um dos seguintes links para instalá -lo primeiro.
Instale o Java 8 no CentOS/Rhel 7/6/5
Instale o Java 8 no Ubuntu
Baixar Elasticsearch (todos os nós)
Agora faça o download do mais recente arquivo de elasticsearch em todos os sistemas de nó em sua página de download oficial. No momento da última atualização deste artigo Elasticsearch 1.4.2 versão é a versão mais recente disponível para download. Use o seguinte comando para baixar o elasticsearch 1.4.2.
$ wget https: // download.Elasticsearch.Org/Elasticsearch/Elasticsearch/Elasticsearch-1.4.2.alcatrão.gz
Agora extraia o Elasticsearch em todos os sistemas de nós.
$ tar xzf Elasticsearch-1.4.2.alcatrão.gz
Configure o Elasticsearch
Agora precisamos configurar o Elasticsearch em todos os sistemas de nós. Elasticsearch usa "Elasticsearch" como nome de cluster padrão. Recomendamos alterá -lo de acordo com sua conversa de nomeação.
$ MV Elasticsearch-1.4.2/usr/share/elasticsearch $ CD/usr/share/Elasticsearch
Para alterar o cluster chamado Editar Config/Elasticsearch.yml arquivo em cada nó e atualize os seguintes valores. Os nomes dos nó são gerados dinamicamente, mas para manter um nome fixo fixo, altere também.
No node_1
Editar Elasticsearch Cluster Configuração em Node_1 (192.168.10.101) Sistema.
$ vim config/elasticsearch.yml
conjunto.Nome: Nó Tecadmincluster.Nome: "Node_1"
No node_2
EDIT ELÁSTICASTICSECH CLUSTER CONFIGURAÇÃO NO NODE_2 (192.168.10.102) Sistema.
$ vim config/elasticsearch.yml
conjunto.Nome: Nó Tecadmincluster.Nome: "Node_2"
No node_3
EDIT ELÁSTICASTICSECH CLUSTER CONFIGURAÇÃO NO NODE_3 (192.168.10.103) Sistema.
$ vim config/elasticsearch.yml
conjunto.Nome: Nó Tecadmincluster.Nome: "Node_3"
Instale o plug-in Elasticsearch-Head (todos os nós)
Elasticsearch-Head é um front end para navegar e interagir com um cluster de pesquisa elástica. Use o seguinte comando para instalar este plug -in em todos os sistemas de nós.
$ bin/plugin-Instalação Mobz/Elasticsearch-Head
Elasticsearch Cluster (todos os nós)
Como a configuração do cluster de elasticsearch foi concluída. Vamos iniciar o Elasticsearch Cluster usando o seguinte comando em todos os nós.
$ ./bin/elasticsearch &
Por padrão, Elasticserch Ouça na porta 9200 e 9300. Então conecte -se a Node_1 Na porta 9200, como seguir o URL, você verá todos os três nós em seu cluster.
http: // node_1: 9200/_plugin/Head/
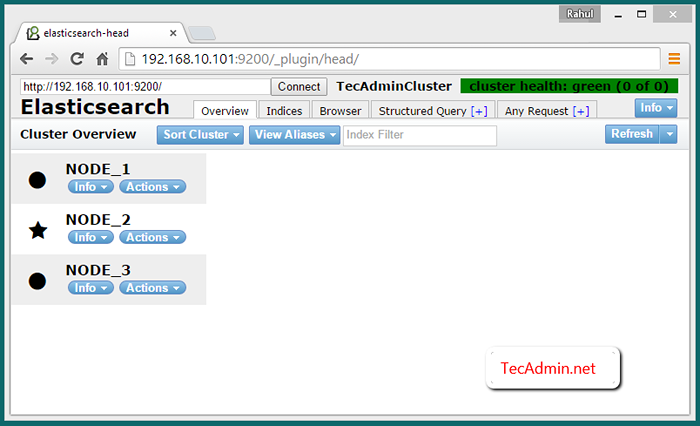
Verifique o cluster de vários nós
Para verificar se o cluster está funcionando corretamente. Insira alguns dados em um nó e se os mesmos dados estiverem disponíveis em outros nós, significa que o cluster está funcionando corretamente.
Insira dados em node_1
Para verificar o cluster, crie um balde em Node_1 e adicione alguns dados.
$ curl -xput http: // node_1: 9200/mybucket $ curl -xput 'http: // node_1: 9200/mybucket/user/rahul' -d '"name": "rahul kumar"' '
$ curl -xput 'http: // node_1: 9200/mybucket/post/1' -d '"user": "rahul", "pós -date": "01-16-2015", "corpo": "Adicionando dados de dados em Elasticsearch Cluster "," Title ":" Elasticsearch Cluster Test " ''
Pesquise dados em todos os nós
Agora pesquise os mesmos dados de Node_2 e Node_3 e verifique se os mesmos dados são replicados para outros nós de cluster. De acordo com os comandos acima, criamos um usuário chamado Rahul e adicionamos alguns dados lá. Portanto, use os seguintes comandos para pesquisar dados associados ao usuário Rahul.
$ curl 'http: // node_1: 9200/mybucket/post/_search?Q = Usuário: RAHUL & BLYSTE = TRUE '$ CURL' http: // node_2: 9200/mybucket/post/_search?Q = Usuário: RAHUL & BLYSTE = TRUE '$ CURL' http: // node_3: 9200/mybucket/post/_search?Q = Usuário: RAHUL & BLYSTE = TRUE '
E você obterá resultados como os comandos abaixo para todos os comandos acima.
"Take": 69, "timed_out": false, "_shards": "total": 5, "bem -sucedido": 5, "falhou": 0, "hits": "total": 1, "max_score ": 1.0, "Hits": ["_index": "mybucket", "_type": "post", "_id": "1", "_score": 1.0, "_source": "User": "Rahul", "PostDate": "01-16-2015", "Body": "Adicionando dados em Elasticsearch Cluster", "Title": "Elasticsearch Cluster Test" ]
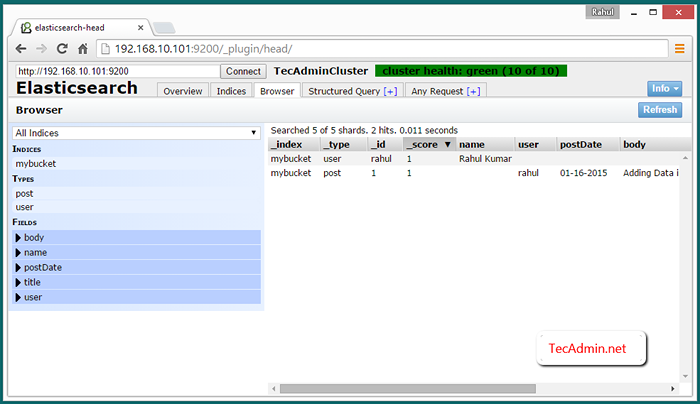
Visualize dados de cluster no navegador da web
Para visualizar os dados sobre o Elasticsearch Cluster Access of Elasticsearch-Head Plugin usando um de IP do cluster abaixo do URL. Em seguida, clique em Navegador aba.
http: // node_1: 9200/_plugin/Head/
- « Como usar o comando SystemCTL para gerenciar serviços Systemd
- Adicionando repositório extra Epel e Remi em um sistema baseado em RHEL »