

Como instalar o Apache Kafka no Ubuntu 20.04

- 4042
- 492
- Spencer Emard
Apache Kafka é uma plataforma de streaming de eventos distribuída e de código aberto desenvolvido pela Apache Software Foundation. Isso está escrito em linguagens de programação Scala e Java. Você pode instalar o Kafka em qualquer plataforma que suporta java.
Este tutorial descreveu seu tutorial passo a passo para instalar Apache Kafka no Ubuntu 20.04 LTS Linux System. Você também aprenderá a criar tópicos em Kafka e executar nós de produtor e consumidor.
Pré -requisitos
Você deve ter acesso à conta privilegiada do sudo ao Ubuntu 20.04 Sistema Linux.
Etapa 1 - Instalando Java
Apache Kafka pode ser executado em todas as plataformas suportadas por java. Para configurar Kafka no sistema Ubuntu, você precisa instalar o Java First. Como sabemos, o Oracle Java agora está disponível comercialmente, então estamos usando sua versão de código aberto OpenJDK.
Execute o comando abaixo para instalar o OpenJDK no seu sistema a partir dos PPAs oficiais.
sudo apt update sudo apt install default-jdk
Verifique a versão Java ativa atual.
Java -Versão Versão OpenJdk "11.0.9.1 "2020-11-04 OpenJDK Runtime Environment (Build 11.0.9.1+1-Ubuntu-0ubuntu1.20.04) OpenJDK de 64 bits servidor VM (Build 11.0.9.1+1-Ubuntu-0ubuntu1.20.04, modo misto, compartilhamento) Etapa 2 - Baixe o último Apache Kafka
Baixe os arquivos binários do Apache Kafka em seu site oficial de download. Você também pode selecionar qualquer espelho próximo para baixar.
wget https: // dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.TGZ Em seguida, extraia o arquivo de arquivo
Tar xzf kafka_2.13-3.2.0.TGZsudo mv kafka_2.13-3.2.0/usr/local/kafka
Etapa 3 - Criando arquivos da unidade Systemd
Agora, você precisa criar arquivos da unidade Systemd para os serviços Zookeeper e Kafka. O que o ajudará a iniciar/parar o serviço Kafka de uma maneira fácil.
Primeiro, crie um arquivo de unidade Systemd para Zookeeper:
vim/etc/systemd/system/zookeeper.serviço
E adicione o seguinte conteúdo:
[Unidade] Descrição = Apache Zookeeper Server Documentation = http: // zookeeper.apache.org requer = rede.alvo remoto-fs.Target After = Network.alvo remoto-fs.Target [Service] Type = simples execStart =/usr/local/kafka/bin/zookeeper-server-start.sh/usr/local/kafka/config/zookeeper.Propriedades Execstop =/usr/local/kafka/bin/zookeeper-server-stop.reinicialização sh = on-abnormal [install] wantedby = multi-user.alvo
Salve o arquivo e feche-o.
Em seguida, para criar um arquivo de unidade Systemd para o serviço Kafka:
vim/etc/systemd/system/kafka.serviço
Adicione o conteúdo abaixo. Certifique -se de definir o correto Java_home Caminho conforme o Java instalado em seu sistema.
[Unidade] Descrição = documentação do servidor Apache Kafka = http: // kafka.apache.org/documentação.html requer = zookeeper.Serviço [Serviço] Tipo = Ambiente simples = "Java_home =/usr/lib/jvm/java-1.11.0-openjdk-amd64 "ExecStart =/usr/local/kafka/bin/kafka-server-start.sh/usr/local/kafka/config/servidor.Propriedades exectop =/usr/local/kafka/bin/kafka-server-stop.sh [install] wantedby = multiususer.alvo
Salve o arquivo e feche.
Recarregue o daemon Systemd para aplicar novas alterações.
SystemCTL Daemon-Reload
Etapa 4 - Iniciar o serviço Kafka e Zookeeper
Primeiro, você precisa iniciar o serviço Zookeeper e depois começar a Kafka. Use o comando SystemCTL para iniciar uma instância de Zookeeper de um nó único.
SUDO SYSTEMCTL START Zookeeper
Agora inicie o servidor Kafka e visualize o status de execução:
SUDO SYSTEMCTL START KAFKA SUDO SYSTEMCTL STATUS KAFKA
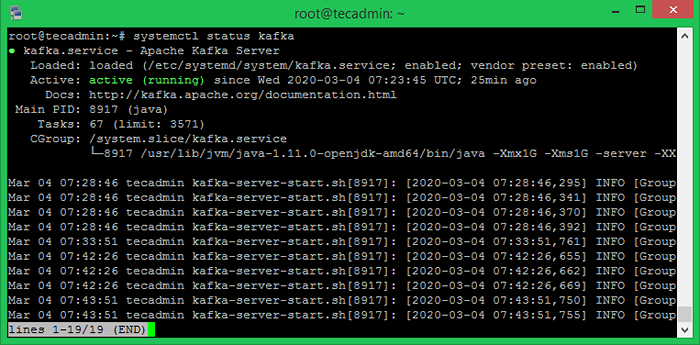
Tudo feito. A instalação de Kafka foi concluída com sucesso. A parte deste tutorial ajudará você a trabalhar com o servidor Kafka.
Etapa 5 - Crie um tópico em Kafka
Kafka fornece vários scripts de shell pré-construídos para trabalhar nele. Primeiro, crie um tópico chamado "TestTopic" com uma única partição com uma única réplica:
CD/usr/local/kafka bin/kafka-topics.SH --Create --Bootstrap-Server LocalHost: 9092-Replicação-fator 1-Partições 1-TOPIC TOPTIC CRIADO TOTE TESTTICO.
O fator de replicação descreve quantas cópias de dados serão criadas. Como estamos executando com uma única instância, mantenha este valor 1.
Defina as opções de partição como o número de corretores que você deseja que seus dados sejam divididos entre. Como estamos correndo com um único corretor, mantenha este valor 1.
Você pode criar vários tópicos executando o mesmo comando que acima. Depois disso, você pode ver os tópicos criados em Kafka pelo comando Running Abaixo:
bin/kafka-topics.SH-LIST-LocalHost de servidor-servidor: 9092 [saída] TestTopic
Como alternativa, em vez de criar tópicos manualmente, você também pode configurar seus corretores para criar tópicos de criação automática quando um tópico inexistente é publicado para.
Etapa 6 - Envie e receba mensagens em Kafka
O "produtor" é o processo responsável por colocar dados em nosso kafka. O Kafka vem com um cliente da linha de comando que receberá informações de um arquivo ou de entrada padrão e o enviará como mensagens para o cluster kafka. O Kafka padrão envia cada linha como uma mensagem separada.
Vamos executar o produtor e depois digitar algumas mensagens no console para enviar para o servidor.
Bin/Kafka-Console-produtor.SH-Localhost de Lista de Boscadores: 9092-TOPIC TESTTOPIC> Bem-vindo a Kafka> Este é o meu primeiro tópico>
Você pode sair deste comando ou manter este terminal em execução para mais testes. Agora abra um novo terminal para o processo de consumidor Kafka na próxima etapa.
Etapa 7 - Usando o consumidor Kafka
Kafka também tem um consumidor de linha de comando para ler dados do cluster kafka e exibir mensagens para saída padrão.
Consumidor-consumidor de Bin/Kafka.sh-bootstrap-server localhost: 9092-TOPIC TESTTICO-Frogo-acolhedor de boas-vindas a kafka Este é o meu primeiro tópico
Agora, se você ainda está executando o produtor Kafka (Etapa 6) em outro terminal. Basta digitar algum texto nesse terminal do produtor. Será imediatamente visível no terminal do consumidor. Veja a captura de tela abaixo do produtor e consumidor Kafka no trabalho:
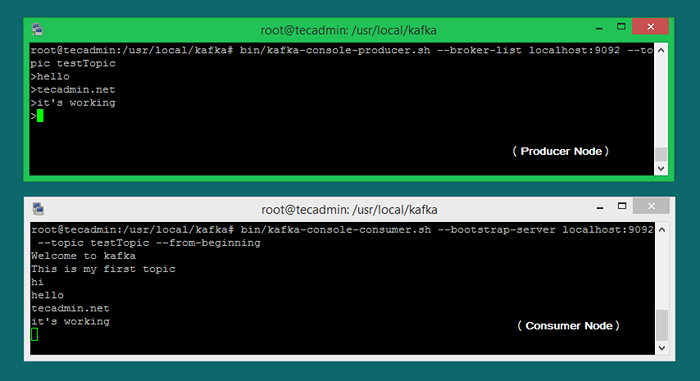
Conclusão
Este tutorial ajudou você a instalar e configurar o serviço Apache Kafka em um sistema Ubuntu. Além disso, você aprendeu a criar um novo tópico no servidor Kafka e executar um processo de produção de amostra e consumidor com Apache Kafka.