

Como instalar o Apache Kafka no CentOS 8

- 2250
- 48
- Wendell Legros
Apache Kafka é uma plataforma de streaming distribuída. É útil para a criação de pipelines de dados de streaming em tempo real para obter dados entre os sistemas ou aplicativos. Outro recurso útil são os aplicativos de streaming em tempo real que podem transformar fluxos de dados ou reagir em um fluxo de dados.
Este tutorial ajudará você a instalar os sistemas Apache Kafka Centos 8 ou Rhel 8 Linux.
Pré -requisitos
- O sistema recém -instalado é recomendado para seguir a configuração inicial do servidor.
- Acesso ao shell ao sistema CentOS 8 com a conta de privilégios sudo.
Etapa 1 - Instale Java
Você deve ter o Java instalado em seu sistema para executar o Apache Kafka. Você pode instalar o OpenJDK em sua máquina executando o seguinte comando. Além disso, instale outras ferramentas necessárias.
sudo dnf install java-11-openjdk wget vim Etapa 2 - Baixe o Apache Kafka
Baixe os arquivos binários do Apache Kafka em seu site oficial de download. Você também pode selecionar qualquer espelho próximo para baixar.
wget https: // dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.TGZ Em seguida, extraia o arquivo de arquivo
Tar xzf kafka_2.13-3.2.0.TGZsudo mv kafka_2.13-3.2.0/usr/local/kafka
Etapa 3 - Configure arquivos da unidade Kafka Systemd
O CentOS 8 usa o Systemd para gerenciar seu estado de serviços. Portanto, precisamos criar arquivos da unidade Systemd para o serviço Zookeeper e Kafka. O que nos ajuda a gerenciar serviços Kafka para iniciar/parar.
Primeiro, crie o arquivo da unidade Systemd para o Zookeeper com o comando abaixo:
vim/etc/systemd/system/zookeeper.serviço
Adicione abaixo o CONTNET:
[Unidade] Descrição = Apache Zookeeper Server Documentation = http: // zookeeper.apache.org requer = rede.alvo remoto-fs.Target After = Network.alvo remoto-fs.Target [Service] Type = Simple ExecStart =/usr/bin/Bash/usr/local/kafka/bin/zookeeper-server-start.sh/usr/local/kafka/config/zookeeper.Propriedades exectop =/usr/bin/bash/usr/local/kafka/bin/zookeeper-server-stop.reinicialização sh = on-abnormal [install] wantedby = multi-user.alvo
Salve o arquivo e feche-o.
Em seguida, para criar um arquivo da unidade Kafka Systemd usando o seguinte comando:
vim/etc/systemd/system/kafka.serviço
Adicione o conteúdo abaixo. Certifique -se de definir o correto Java_home Caminho conforme o Java instalado em seu sistema.
[Unidade] Descrição = documentação do servidor Apache Kafka = http: // kafka.apache.org/documentação.html requer = zookeeper.Serviço [Serviço] TIPO = Ambiente simples = "Java_home =/usr/lib/jvm/jre-11-openjdk" execstart =/usr/bin/bash/usr/local/kafka/bin/kafka-server-start.sh/usr/local/kafka/config/servidor.Propriedades exectop =/usr/bin/bash/usr/local/kafka/bin/kafka-server-stop.sh [install] wantedby = multiususer.alvo
Salve o arquivo e feche-o.
Recarregue o daemon Systemd para aplicar alterações.
SystemCTL Daemon-Reload
Etapa 4 - Iniciar o servidor Kafka
Kafka exigiu o Zookeeper, então primeiro, inicie um servidor Zookeeper em seu sistema. Você pode usar o script disponível com Kafka para iniciar uma instância do Zoookeeper de um único nó.
SUDO SYSTEMCTL START Zookeeper
Agora inicie o servidor Kafka e visualize o status de execução:
SUDO SYSTEMCTL START KAFKA SUDO SYSTEMCTL STATUS KAFKA
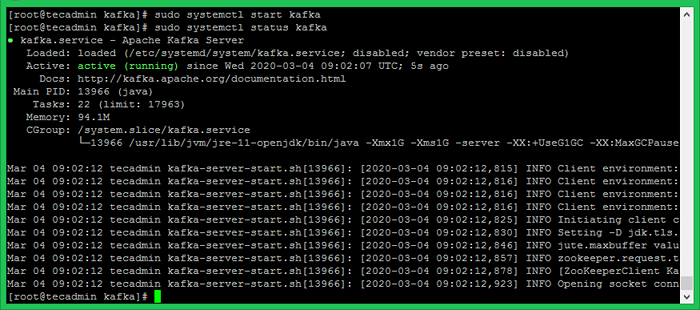
Tudo feito. Você instalou com sucesso o Kafka no seu CentOS 8. A próxima parte deste tutorial ajudará você a criar tópicos no cluster Kafka e trabalhará com o produtor Kafka e o Serviço de Consumidores.
Etapa 5 - Criando tópicos em Apache Kafka
Apache Kafka fornece vários scripts de shell para trabalhar nele. Primeiro, crie um tópico chamado “Testtopic”Com uma única partição com uma única réplica:
CD/usr/local/kafka bin/kafka-topics.SH --Create --Bootstrap-Server LocalHost: 9092-Replicação-fator 1-Partições 1-TOPIC TOPTIC CRIADO TOTE TESTTICO.
O fator de replicação descreve quantas cópias de dados serão criadas. Como estamos executando com uma única instância, mantenha este valor 1.
Defina as opções de partições como o número de corretores que você deseja que seus dados sejam divididos entre. Como estamos correndo com um único corretor, mantenha este valor 1.
Você pode criar vários tópicos executando o mesmo comando que acima. Depois disso, você pode ver os tópicos criados em Kafka pelo comando Running Abaixo:
bin/kafka-topics.SH -List -Zookeeper localhost: 9092 TESTTIC KAFKAONCENTOS8 TUTORIALKAFKAINSTALLCONTOS8
Como alternativa, em vez de criar manualmente tópicos, você também pode configurar seus corretores para criar tópicos automaticamente quando um tópico inexistente é publicado para.
Etapa 6 - Produtor e consumidor Apache Kafka
O "produtor" é o processo responsável por colocar dados em nosso kafka. O Kafka vem com um cliente da linha de comando que receberá informações de um arquivo ou de entrada padrão e o enviará como mensagens para o cluster kafka. O Kafka padrão envia cada linha como uma mensagem separada.
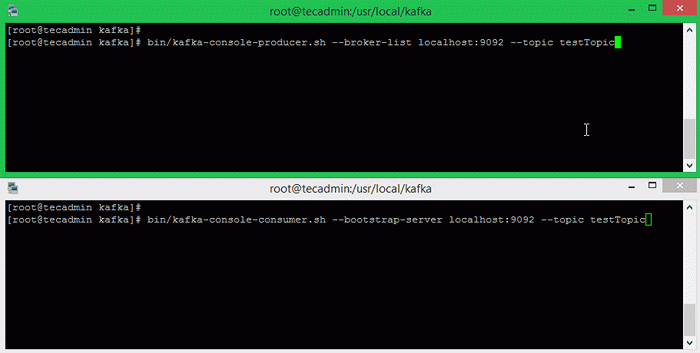
Vamos executar o produtor e depois digitar algumas mensagens no console para enviar para o servidor.
Bin/Kafka-Console-produtor.SH-Localhost de Lista de Boscadores: 9092-TOPIC TESTTOPIC> Bem-vindo a Kafka> Este é o meu primeiro tópico>
Agora abra um novo terminal para executar o processo do consumidor Apache Kafka. Kafka também fornece e consumidor de linha de comando ler dados do cluster kafka e exibir mensagens para a saída padrão.
Consumidor-consumidor de Bin/Kafka.sh-bootstrap-server localhost: 9092-TOPIC TESTTICO-Frogo-acolhedor de boas-vindas a kafka Este é o meu primeiro tópico
A opção de regressão é usada para ler mensagens desde o início do tópico selecionado. Você pode pular esta opção para ler apenas as mensagens mais recentes.
Por exemplo, execute o produtor e consumidor Kafka nos terminais separados. Basta digitar algum texto nesse terminal do produtor. Irá visível imediatamente no terminal do consumidor. Veja a captura de tela abaixo do produtor e consumidor da Kafka no trabalho:
Conclusão
Você instalou e configurou com sucesso o serviço Kafka na máquina do CentOS 8 Linux.