

Como instalar o Apache Hadoop no Ubuntu 22.04

- 2994
- 763
- Wendell Legros
Compreender dados não estruturados e analisar quantidades enormes de dados é um jogo de bola diferente hoje. E assim, as empresas recorreram ao Apache Hadoop e a outras tecnologias relacionadas para gerenciar seus dados não estruturados com mais eficiência. Não apenas as empresas, mas também os indivíduos estão usando o Apache Hadoop para vários fins, como analisar grandes conjuntos de dados ou criar um site que pode processar consultas de usuário. No entanto, a instalação do Apache Hadoop no Ubuntu pode parecer uma tarefa difícil para os usuários novos no mundo dos servidores Linux. Felizmente, você não precisa ser um administrador de sistema experiente para instalar o Apache Hadoop no Ubuntu.
O seguinte guia de instalação passo a passo levará você a todo o processo do download do software para configurar o servidor com facilidade. Neste artigo, explicaremos como instalar o Apache Hadoop no Ubuntu 22.04 Sistema LTS. Isso também pode ser usado para outras versões do Ubuntu.
Etapa 1: Instale o Kit de Desenvolvimento Java
Java é um componente necessário do Apache Hadoop, então você precisa baixar e instalar um kit de desenvolvimento Java em todos os nós da sua rede onde o Hadoop será instalado. Você pode baixar o jre ou jdk. Se você está apenas procurando correr Hadoop, Jre é suficiente, mas se você deseja criar aplicativos que sejam executados no Hadoop, então precisará instalar o JDK. A versão mais recente do Java que o Hadoop suporta é Java 8 e 11. Você pode verificar isso no site da Apache e baixar a versão relevante do Java, dependendo do seu sistema operacional.
- Os repositórios padrão do Ubuntu contêm Java 8 e Java 11 ambos. Use o seguinte comando para instalá -lo.
sudo apt update && sudo apt install openjdk-11-jdk - Depois de instalá -lo com sucesso, verifique a versão Java atual:
Java -version Verifique a versão Java
Verifique a versão Java - Você pode encontrar a localização do diretório java_home executando o seguinte comando. Isso será necessário mais recente neste artigo.
Dirname $ (Dirname $ (readlink -f $ (que java)))) Verifique Java_home Localização
Verifique Java_home Localização
Etapa 2: Crie usuário para Hadoop
Todos os componentes do Hadoop serão executados como usuário que você cria para o Apache Hadoop, e o usuário também será usado para fazer login na interface da web do Hadoop. Você pode criar uma nova conta de usuário com o comando "sudo" ou pode criar uma conta de usuário com permissões "root". A conta de usuário com permissões root é mais segura, mas pode não ser tão conveniente para usuários que não estão familiarizados com a linha de comando.
- Execute o seguinte comando para criar um novo usuário com o nome "Hadoop":
Sudo Adduser Hadoop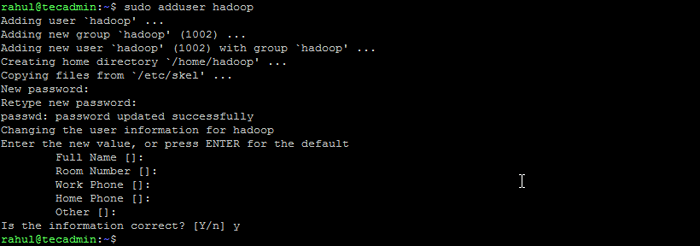 Crie usuário Hadoop
Crie usuário Hadoop - Mude para o usuário do Hadoop recém -criado:
Su - Hadoop - Agora configure acesso SSH sem senha para o recém-criado usuário do Hadoop. Gerar um SSH Keypair primeiro:
ssh -keygen -t rsa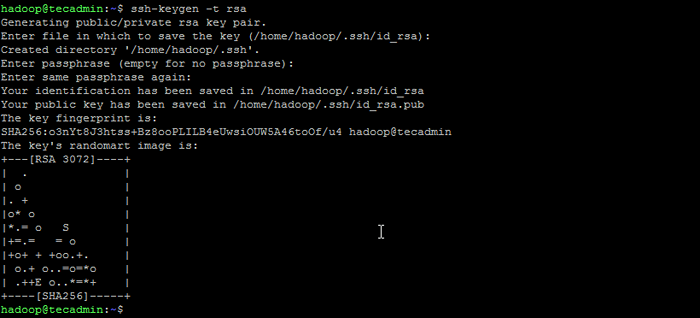 Gerar par de chaves ssh
Gerar par de chaves ssh - Copie a chave pública gerada para o arquivo de chave autorizado e defina as permissões adequadas:
gato ~//.ssh/id_rsa.pub >> ~///.ssh/autorizado_keyschmod 640 ~//.ssh/autorizado_keys - Agora tente fazer ssh para a localhost.
ssh localhostVocê será solicitado a autenticar hosts adicionando chaves RSA aos hosts conhecidos. Digite sim e pressione Enter para autenticar o host local:
 Conecte o ssh ao host
Conecte o ssh ao host
Etapa 3: Instale o Hadoop no Ubuntu
Depois de instalar o Java, você pode baixar o Apache Hadoop e todos os seus componentes relacionados, incluindo Hive, Pig, Sqoop, etc. Você pode encontrar a versão mais recente na página de download oficial do Hadoop. Certifique -se de baixar o arquivo binário (não a fonte).
- Use o seguinte comando para baixar o Hadoop 3.3.4:
wget https: // dlcdn.apache.org/hadoop/comum/hadoop-3.3.4/Hadoop-3.3.4.alcatrão.gz - Depois de baixar o arquivo, você pode descompactá -lo em uma pasta no seu disco rígido.
Tar XZF Hadoop-3.3.4.alcatrão.gz - Renomeie a pasta extraída para remover as informações da versão. Esta é uma etapa opcional, mas se você não quiser renomear, ajuste os caminhos de configuração restantes.
MV Hadoop-3.3.4 Hadoop - Em seguida, você precisará configurar variáveis de ambiente Hadoop e Java em seu sistema. Abra o ~//.Arquivo Bashrc em seu editor de texto favorito:
nano ~//.BashrcAnexar as linhas abaixo ao arquivo. Você pode encontrar o local Java_home executando
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$ Hadoop_home export hadoop_common_lib_native_dir = $ hadoop_home/lib/nativo caminho de exportação = $ caminho: $ hadoop_home/sbin: $ hadoop_home/bin exportar hadoop_opt = "-djava.biblioteca.caminho = $ hadoop_home/lib/nativo "Dirname $ (Dirname $ (readlink -f $ (que java))))comando no terminal.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ Lib/nativo Path = $ PATH: $ HADOOP_HOME/SBIN: $ HADOOP_HOME/BINEXPORT HADOOP_OPTS = "-Djava.biblioteca.caminho = $ hadoop_home/lib/nativo " Salve o arquivo e feche-o.
- Carregue a configuração acima no ambiente atual.
fonte ~///.Bashrc - Você também precisa configurar Java_home em Hadoop-env.sh arquivo. Edite o arquivo variável do ambiente Hadoop no editor de texto:
nano $ hadoop_home/etc/hadoop/hadoop-env.shPesquise o "Export Java_home" e configure -o com o valor encontrado na Etapa 1. Veja a captura de tela abaixo:
 Defina java_home
Defina java_homeSalve o arquivo e feche-o.
Etapa 4: Configurando o Hadoop
Em seguida, é configurar arquivos de configuração do Hadoop disponíveis no diretório etc.
- Primeiro, você precisará criar o Namenode e DataNode Diretórios dentro do Diretório de Usuário do Hadoop. Execute o seguinte comando para criar os dois diretórios:
mkdir -p ~/hadoopdata/hdfs/namenode, datanode - Em seguida, edite o Site do núcleo.xml Arquive e atualize com o seu nome de host do sistema:
nano $ hadoop_home/etc/hadoop/site core.xmlAltere o seguinte nome de acordo com o seu nome de host do sistema:
fs.Defaultfs hdfs: // localhost: 9000123456 fs.Defaultfs hdfs: // localhost: 9000 Salve e feche o arquivo.
- Então, edite o Site HDFS.xml arquivo:
nano $ hadoop_home/etc/hadoop/hdfs-site.xmlAltere os caminhos de diretório Namenode e DataNode, como mostrado abaixo:
dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode12345678910111213141516 dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode Salve e feche o arquivo.
- Então, edite o MapRed-site.xml arquivo:
nano $ hadoop_home/etc/hadoop/mapa-site.xmlFaça as seguintes alterações:
MapReduce.estrutura.Nome Yarn123456 MapReduce.estrutura.Nome Yarn Salve e feche o arquivo.
- Então, edite o Site de fio.xml arquivo:
nano $ hadoop_home/etc/hadoop/yarn site.xmlFaça as seguintes alterações:
fio.NodeManager.Aux-Services mapReduce_shuffle123456 fio.NodeManager.Aux-Services mapReduce_shuffle Salve o arquivo e feche-o.
Etapa 5: Iniciar o Hadoop Cluster
Antes de iniciar o cluster Hadoop. Você precisará formatar o Namenode como um usuário do Hadoop.
- Execute o seguinte comando para formatar o Hadoop Namenode:
HDFS Namenode -FormatDepois que o diretório Namenode for formatado com sucesso com o sistema de arquivos HDFS, você verá a mensagem “Diretório de Armazenamento/Home/Hadoop/Hadoopdata/HDFS/Namenode foi formatado com sucesso““.
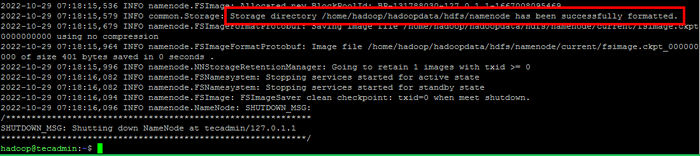 Formato namenode
Formato namenode - Em seguida, inicie o cluster Hadoop com o seguinte comando.
Start-All.sh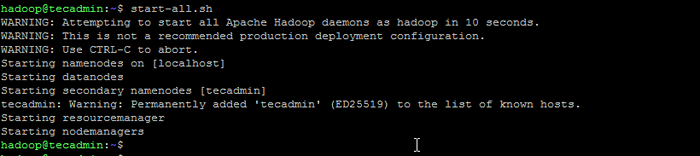 Inicie os serviços do Hadoop
Inicie os serviços do Hadoop - Depois que todos os serviços começarem, você pode acessar o Hadoop em: http: // localhost: 9870

- E a página de aplicativo Hadoop está disponível em http: // localhost: 8088

Conclusão
Instalar o Apache Hadoop no Ubuntu pode ser uma tarefa complicada para os iniciantes, especialmente se eles seguirem apenas as instruções na documentação. Felizmente, este artigo fornece um guia passo a passo que o ajudará a instalar o Apache Hadoop no Ubuntu com facilidade. Tudo o que você precisa fazer é seguir as instruções listadas neste artigo, e você pode ter certeza de que sua instalação no Hadoop estará em funcionamento em nenhum momento.