

Como instalar e configurar o Apache Spark no Ubuntu/Debian

- 1542
- 328
- Leroy Lebsack
Apache Spark é uma estrutura computacional distribuída de código aberto que é criado para fornecer resultados computacionais mais rápidos. É um mecanismo computacional na memória, o que significa que os dados serão processados na memória.
Fagulha Suporta várias APIs para streaming, processamento de gráficos, SQL, Mllib. Ele também suporta Java, Python, Scala e R como os idiomas preferidos. O Spark é instalado principalmente em clusters Hadoop, mas você também pode instalar e configurar o Spark no modo independente.
Neste artigo, veremos como instalar Apache Spark em Debian e Ubuntu-distribuições baseadas.
Instale Java e Scala no Ubuntu
Para instalar Apache Spark no Ubuntu, você precisa ter Java e Scala instalado em sua máquina. A maioria das distribuições modernas vem com Java instalado por padrão e você pode verificá -lo usando o seguinte comando.
$ java -version
 Verifique a versão java no Ubuntu
Verifique a versão java no Ubuntu Se não houver saída, você pode instalar o Java usando nosso artigo sobre como instalar Java no Ubuntu ou simplesmente executar os seguintes comandos para instalar o Java no Ubuntu e as distribuições baseadas em Debian.
$ sudo apt update $ sudo apt install default -jre $ java -version
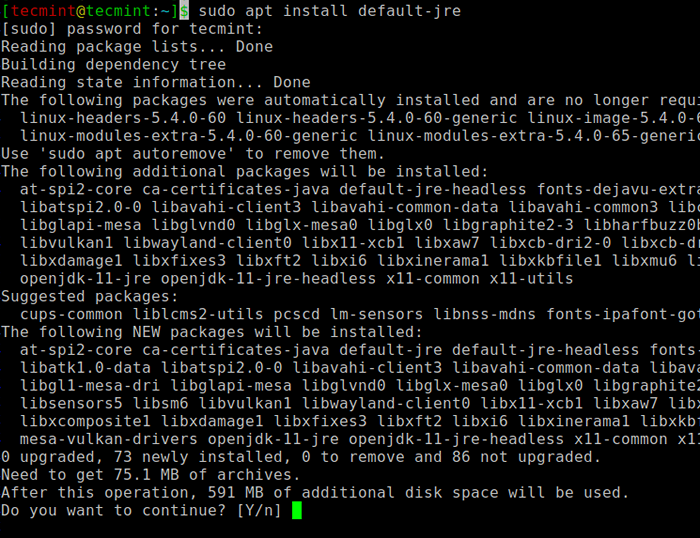 Instale Java no Ubuntu
Instale Java no Ubuntu Em seguida, você pode instalar Scala No repositório APT, executando os seguintes comandos para procurar Scala e instalá -lo.
$ sudo apt scala scala ⇒ busca o pacote $ sudo apt install scala ⇒ instale o pacote
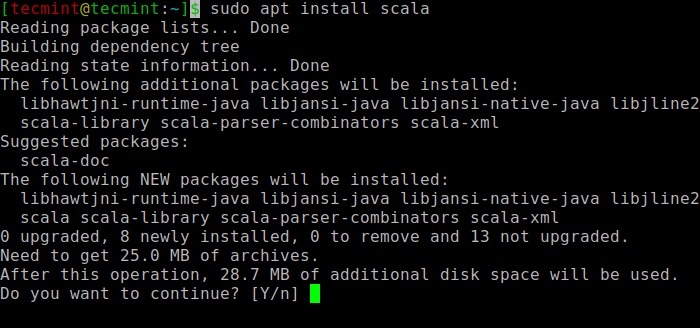 Instale o Scala no Ubuntu
Instale o Scala no Ubuntu Para verificar a instalação de Scala, Execute o seguinte comando.
$ scala -versão Código Scala Runner Versão 2.11.12-Copyright 2002-2017, lâmpada/epfl
Instale o Apache Spark no Ubuntu
Agora vá para a página oficial do Apache Spark Download e pegue a versão mais recente (i.e. 3.1.1) No momento da redação deste artigo. Como alternativa, você pode usar o comando wget para baixar o arquivo diretamente no terminal.
$ wget https: // apachemirror.WUCHNA.com/Spark/Spark-3.1.1/Spark-3.1.1-bin-hadoop2.7.TGZ
Agora abra seu terminal e mude para onde seu arquivo baixado é colocado e execute o seguinte comando para extrair o arquivo Apache Spark Tar.
$ tar -xvzf Spark -3.1.1-bin-hadoop2.7.TGZ
Finalmente, mova o extraído Fagulha diretório para /optar diretório.
$ sudo MV Spark-3.1.1-bin-hadoop2.7 /Opt /Spark
Configurar variáveis ambientais para Spark
Agora você tem que definir algumas variáveis ambientais em seu .perfil Arquivo antes de iniciar o Spark.
$ echo "export spark_home =/opt/spark" >> ~///.Perfil $ eco "Caminho de exportação = $ caminho:/opt/spark/bin:/opt/spark/sbin" >> ~//////////////.Perfil $ echo "Exportar Pyspark_python =/usr/bin/python3" >> ~////.perfil
Para garantir que essas novas variáveis de ambiente estejam acessíveis dentro do shell e disponíveis para o Apache Spark, também é obrigatório executar o seguinte comando para aceitar mudanças recentes em vigor.
$ fonte ~//.perfil
Todos os binários relacionados a faíscas para começar e parar os serviços estão sob o Sbin pasta.
$ ls -l /opt /spark
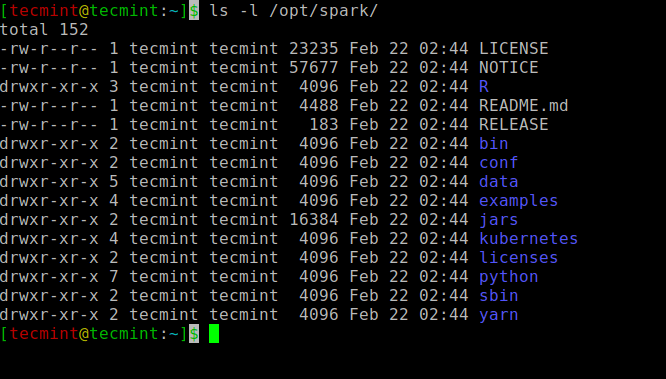 Binários de faísca
Binários de faísca Inicie o Apache Spark no Ubuntu
Execute o seguinte comando para iniciar o Fagulha serviço mestre e serviço de escravos.
$ start-mestre.SH $ STARTWORKERS.SH Spark: // localhost: 7077
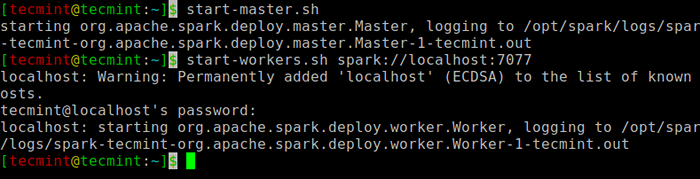 Inicie o serviço Spark
Inicie o serviço Spark Depois que o serviço é iniciado, vá para o navegador e digite a seguinte página de faísca do URL Access. Na página, você pode ver meu mestre e o serviço de escravos é iniciado.
http: // localhost: 8080/ou http: // 127.0.0.1: 8080
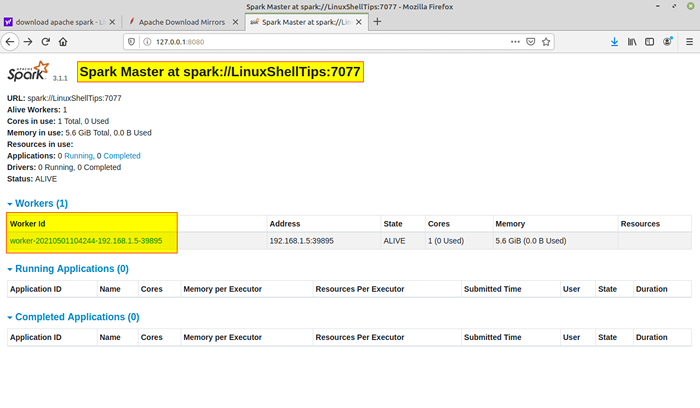 Spark página da web
Spark página da web Você também pode verificar se Spark-shell funciona bem, lançando o Spark-shell comando.
$ Spark-shell
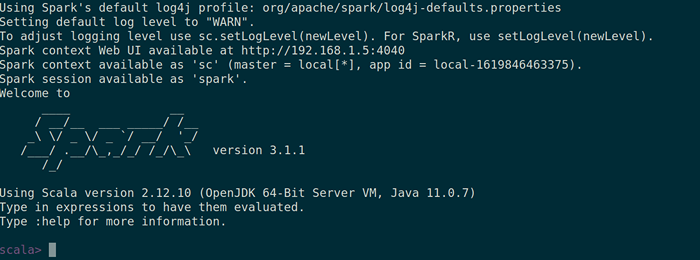 Spark Shell
Spark Shell É isso para este artigo. Vamos te pegar com outro artigo interessante muito em breve.
- « LFCA Aprenda custos e orçamento da nuvem - Parte 16
- Como monitorar o servidor Linux e processar métricas do navegador »