

Como instalar e configurar o Hadoop no CentOS/Rhel 8

- 3023
- 602
- Mr. Mitchell Hansen
O Hadoop é uma estrutura de software gratuita, de código aberto e baseado em Java, usado para armazenamento e processamento de grandes conjuntos de dados em grupos de máquinas. Ele usa HDFs para armazenar seus dados e processar esses dados usando o MapReduce. É um ecossistema de ferramentas de big data que são usadas principalmente para mineração de dados e aprendizado de máquina. Possui quatro componentes principais, como Hadoop Common, HDFs, Yarn e MapReduce.
Neste guia, explicaremos como instalar o Apache Hadoop no RHEL/CENTOS 8.
Etapa 1 - Desativar o Selinux
Antes de começar, é uma boa ideia desativar o Selinux em seu sistema.
Para desativar o Selinux, abra o arquivo/etc/Selinux/Config:
nano/etc/Selinux/config
Altere a seguinte linha:
Selinux = desativado
Salve o arquivo quando terminar. Em seguida, reinicie seu sistema para aplicar as alterações do Selinux.
Etapa 2 - Instale Java
Hadoop está escrito em Java e suporta apenas Java versão 8. Você pode instalar o OpenJDK 8 e ANT usando o comando dnf, como mostrado abaixo:
DNF Instale Java-1.8.0 -openjdk Ant -y
Depois de instalado, verifique a versão instalada do Java com o seguinte comando:
Java -version
Você deve obter a seguinte saída:
Versão OpenJdk "1.8.0_232 "Ambiente de tempo de execução do OpenJDK (Build 1.8.0_232-B09) OpenJDK Servidor de 64 bits VM (Construa 25.232-B09, modo misto)
Etapa 3 - Crie um usuário do Hadoop
É uma boa ideia criar um usuário separado para executar o Hadoop por razões de segurança.
Execute o seguinte comando para criar um novo usuário com o nome Hadoop:
UserAdd Hadoop
Em seguida, defina a senha para este usuário com o seguinte comando:
Passwd Hadoop
Forneça e confirme a nova senha como mostrado abaixo:
Alterando a senha para o usuário Hadoop. Nova senha: reddeme a nova senha: Passwd: todos os tokens de autenticação atualizados com sucesso.
Etapa 4 - Configure a autenticação baseada em chave SSH
Em seguida, você precisará configurar a autenticação SSH sem senha para o sistema local.
Primeiro, mude o usuário para Hadoop com o seguinte comando:
Su - Hadoop
Em seguida, execute o seguinte comando para gerar pares de chave pública e privada:
ssh -keygen -t rsa
Você será solicitado a entrar no nome do arquivo. Basta pressionar Enter para concluir o processo:
Gerando par de chaves RSA pública/privada. Digite o arquivo para salvar a chave (/home/hadoop/.ssh/id_rsa): diretório criado '/home/hadoop/.ssh '. Digite a senha (vazia sem senha): Digite a mesma senha novamente: Sua identificação foi salva em/home/hadoop/.ssh/id_rsa. Sua chave pública foi salva em/home/hadoop/.ssh/id_rsa.bar. A principal impressão digital é: SHA256: A/OG+N3CNBSSYE1ULKK95GYS0POOC0DVJ+YH1DFZPF8 [Email protegido] A imagem Randomart da chave é:+--- [RSA 2048] ----+| | | | | . | | . o o o | |… O s o o | | o = + o o . | | o * o = b = . | | + O.O.O + + . | | +=*ob.+ o e | +---- [SHA256]-----+
Em seguida, anexe as chaves públicas geradas de id_rsa.pub para autorizado_keys e definir permissão adequada:
gato ~//.ssh/id_rsa.pub >> ~///.ssh/autorizado_keys chmod 640 ~/.ssh/autorizado_keys
Em seguida, verifique a autenticação SSH sem senha com o seguinte comando:
ssh localhost
Você será solicitado a autenticar hosts adicionando chaves RSA aos hosts conhecidos. Digite sim e pressione Enter para autenticar o host local:
A autenticidade do host 'localhost (:: 1)' não pode ser estabelecida. A impressão digital da ECDSA é SHA256: 0yr1KDGU44AKG43PHN2GENUZSVRJBBPJAT3BWRDR3MW. Tem certeza que deseja continuar se conectando (sim/não)? Sim Aviso: Adicionado permanentemente 'localhost' (ECDSA) à lista de hosts conhecidos. Ative o console da web com: systemctl atabille -agora cockpit.Último login do soquete: Sáb 1 de fevereiro 02:48:55 2020 [[Email protegido] ~] $
Etapa 5 - Instale o Hadoop
Primeiro, mude o usuário para Hadoop com o seguinte comando:
Su - Hadoop
Em seguida, faça o download da versão mais recente do Hadoop usando o comando wget:
wget http: // apachemirror.WUCHNA.com/hadoop/Common/Hadoop-3.2.1/Hadoop-3.2.1.alcatrão.gz
Depois de baixado, extraia o arquivo baixado:
Tar -xvzf Hadoop -3.2.1.alcatrão.gz
Em seguida, renomeie o diretório extraído para o Hadoop:
MV Hadoop-3.2.1 Hadoop
Em seguida, você precisará configurar variáveis de ambiente Hadoop e Java em seu sistema.
Abra o ~//.Arquivo Bashrc em seu editor de texto favorito:
nano ~//.Bashrc
Anexe as seguintes linhas:
exportar java_home =/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.B09-2.EL8_1.x86_64/export hadoop_home =/home/hadoop/hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home exportar hadoop_common_home = $ hadoop_home export_hdfs_home = $ hidoop_home_home_yarn) : $ Hadoop_home/sbin: $ hadoop_home/bin export hadoop_opts = "-djava.biblioteca.caminho = $ hadoop_home/lib/nativo "
Salve e feche o arquivo. Em seguida, ative as variáveis de ambiente com o seguinte comando:
fonte ~///.Bashrc
Em seguida, abra o arquivo variável do ambiente Hadoop:
nano $ hadoop_home/etc/hadoop/hadoop-env.sh
Atualize a variável java_home conforme seu caminho de instalação Java:
exportar java_home =/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.B09-2.EL8_1.x86_64/
Salve e feche o arquivo quando terminar.
Etapa 6 - Configure o Hadoop
Primeiro, você precisará criar os diretórios Namenode e DataNode dentro do Hadoop Home Directory:
Execute o seguinte comando para criar os dois diretórios:
mkdir -p ~/hadoopdata/hdfs/namenode mkdir -p ~/hadoopdata/hdfs/datanode
Em seguida, edite o Site do núcleo.xml Arquive e atualize com o seu nome de host do sistema:
nano $ hadoop_home/etc/hadoop/site core.xml
Altere o seguinte nome de acordo com o seu nome de host do sistema:
fs.Defaultfs hdfs: // hadoop.Tecadmin.com: 9000| 123456 | fs.Defaultfs hdfs: // hadoop.Tecadmin.com: 9000 |
Salve e feche o arquivo. Então, edite o Site HDFS.xml arquivo:
nano $ hadoop_home/etc/hadoop/hdfs-site.xml
Altere o caminho do diretório Namenode e DataNode, como mostrado abaixo:
dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode| 1234567891011121314151617 | dfs.Replicação 1 DFS.nome.Arquivo Dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dados.Arquivo Dir: /// Home/Hadoop/Hadoopdata/HDFS/DataNode |
Salve e feche o arquivo. Então, edite o MapRed-site.xml arquivo:
nano $ hadoop_home/etc/hadoop/mapa-site.xml
Faça as seguintes alterações:
MapReduce.estrutura.Nome Yarn| 123456 | MapReduce.estrutura.Nome Yarn |
Salve e feche o arquivo. Então, edite o Site de fio.xml arquivo:
nano $ hadoop_home/etc/hadoop/yarn site.xml
Faça as seguintes alterações:
fio.NodeManager.Aux-Services mapReduce_shuffle| 123456 | fio.NodeManager.Aux-Services mapReduce_shuffle |
Salve e feche o arquivo quando terminar.
Etapa 7 - Iniciar o Hadoop Cluster
Antes de iniciar o cluster Hadoop. Você precisará formatar o Namenode como um usuário do Hadoop.
Execute o seguinte comando para formatar o Hadoop Namenode:
HDFS Namenode -Format
Você deve obter a seguinte saída:
2020-02-05 03: 10: 40.380 Informações Namenode.NnstorageretentionManager: vai reter 1 imagens com txid> = 0 2020-02-05 03: 10: 40.389 Info NameNode.FSIMAGE: FSIMAGESAVER LIMPO Ponto de verificação: TXID = 0 Quando o encontro de desligamento. 2020-02-05 03: 10: 40.389 Informações Namenode.Namenode: Shutdown_msg: /*********************************************** *************** Shutdown_msg: Desligando o Namenode no Hadoop.Tecadmin.com/45.58.38.202 ***************************************************** ***********/
Depois de formar o Namenode, execute o seguinte comando para iniciar o cluster Hadoop:
start-dfs.sh
Depois que os HDFs começarem com sucesso, você deve obter a seguinte saída:
Iniciando namenodos no [Hadoop.Tecadmin.com] Hadoop.Tecadmin.com: Aviso: Adicionado permanentemente 'Hadoop.Tecadmin.com, Fe80 :: 200: 2dff: Fe3a: 26ca%eth0 '(ecdsa) para a lista de hosts conhecidos. Iniciando Datanodes iniciando Namenodes secundários [Hadoop.Tecadmin.com]
Em seguida, inicie o serviço de fio, como mostrado abaixo:
Start-yarn.sh
Você deve obter a seguinte saída:
Iniciando RecursoManager iniciando NodeManagers
Agora você pode verificar o status de todos os serviços Hadoop usando o comando jps:
JPS
Você deve ver todos os serviços em execução na seguinte saída:
7987 DataNode 9606 JPS 8183 Secundário 8570 NodeManager 8445 ResourceManager 7870 Namenode
Etapa 8 - Configure o firewall
Hadoop está agora iniciado e ouvindo na porta 9870 e 8088. Em seguida, você precisará permitir essas portas através do firewall.
Execute o seguinte comando para permitir conexões no Hadoop através do firewall:
firewall-cmd --permanent --add-port = 9870/tcp firewall-cmd --permanent --add-port = 8088/tcp
Em seguida, recarregue o serviço Firewalld para aplicar as alterações:
Firewall-CMD--Reload
Etapa 9 - Access Hadoop Namenode e Recursion Manager
Para acessar o Namenode, abra seu navegador da web e visite o URL http: // yourserver-iip: 9870. Você deve ver a seguinte tela:
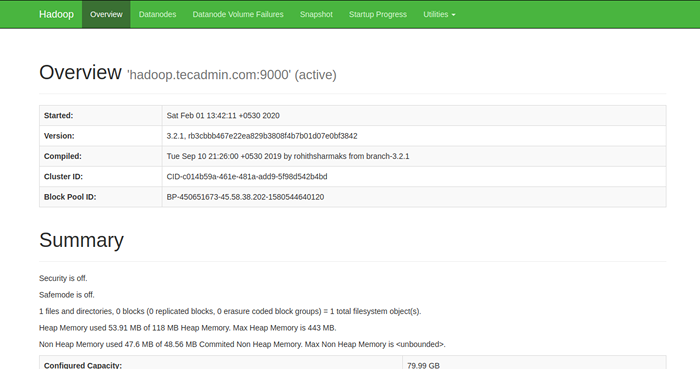
Para acessar o recurso Gerenciar, abra seu navegador da web e visite o URL http: // yourserver-iip: 8088. Você deve ver a seguinte tela:
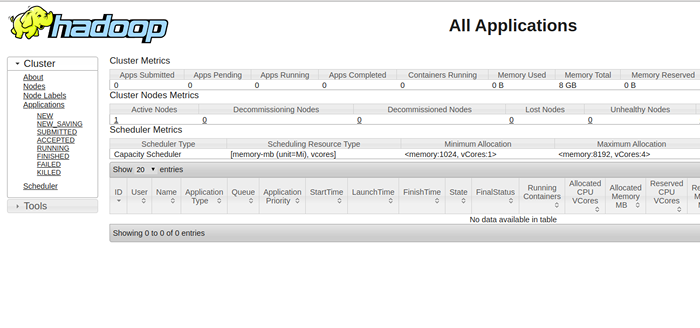
Etapa 10 - Verifique o cluster Hadoop
Neste ponto, o cluster Hadoop está instalado e configurado. Em seguida, criaremos alguns diretórios no sistema de arquivos HDFS para testar o Hadoop.
Vamos criar algum diretório no sistema de arquivos HDFS usando o seguinte comando:
hdfs dfs -mkdir /test1 hdfs dfs -mkdir /test2
Em seguida, execute o seguinte comando para listar o diretório acima:
hdfs dfs -ls /
Você deve obter a seguinte saída:
Encontrado 2 itens drwxr-xr-x-supergrupo Hadoop 0 2020-02-05 03:25 /test1 drwxr-xr-x-supergrupo Hadoop 0 2020-02-05 03:35 /test2
Você também pode verificar o diretório acima na interface da Web Hadoop Namenode.
Vá para a interface da Web Namenode, clique nos utilitários => Navegue no sistema de arquivos. Você deve ver seus diretórios que você criou no início da tela a seguir:
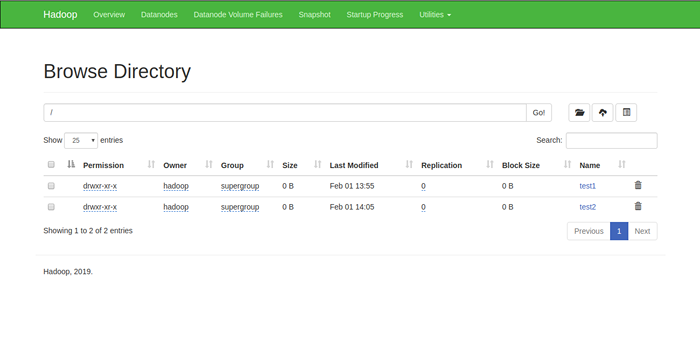
Etapa 11 - Pare o Hadoop Cluster
Você também pode interromper o serviço de namenode e fios Hadoop a qualquer momento executando o Stop-dfs.sh e Stop-yarn.sh Script como usuário do Hadoop.
Para impedir o serviço Hadoop Namenode, execute o seguinte comando como usuário do Hadoop:
Stop-dfs.sh
Para interromper o serviço do Hadoop Resource Manager, execute o seguinte comando:
Stop-yarn.sh
Conclusão
No tutorial acima, você aprendeu a configurar o cluster de nós Hadoop Single Node no CentOS 8. Espero que você tenha agora conhecimento suficiente para instalar o Hadoop no ambiente de produção.