

Como instalar e configurar o Apache Hadoop em um único nó no CentOS 7

- 1722
- 300
- Robert Wunsch DVM
Apache Hadoop é uma estrutura de estrutura de código aberto para armazenamento de big data distribuído e processamento de dados em clusters de computador. O projeto é baseado nos seguintes componentes:
- Hadoop comum - Ele contém as bibliotecas e utilitários Java necessários para outros módulos Hadoop.
- HDFS - Sistema de arquivos distribuído Hadoop - um sistema de arquivos escalável baseado em Java distribuído em vários nós.
- MapReduce - Estrutura de fios para processamento paralelo de big data.
- Fio Hadoop: Uma estrutura para gerenciamento de recursos de cluster.
Instale o Hadoop no CentOS 7 Este artigo o guiará sobre como você pode instalar o Apache Hadoop em um único cluster de nó em CENTOS 7 (também funciona para RHEL 7 e Fedora 23+ versões). Este tipo de configuração também é referenciado como Modo pseudo-distribuído Hadoop.
Etapa 1: Instale Java no CentOS 7
1. Antes de prosseguir com a instalação do Java, o primeiro login com o usuário root ou um usuário com privilégios root configure seu nome de host da máquina com o seguinte comando.
# Hostnamectl Set-HostName Master
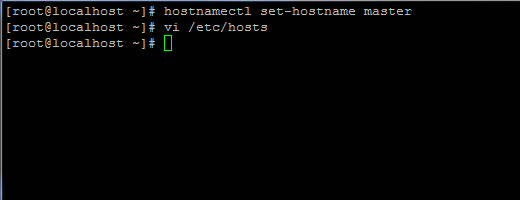 Defina o nome do host no CentOS 7
Defina o nome do host no CentOS 7 Além disso, adicione um novo registro no arquivo hosts com sua própria máquina FQDN para apontar para o endereço IP do seu sistema.
# vi /etc /hosts
Adicione a linha abaixo:
192.168.1.41 Mestre.Hadoop.LAN
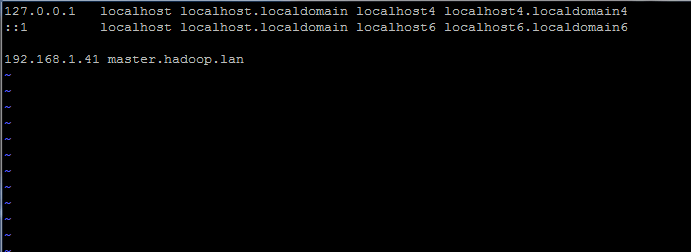 Defina o nome do host em /etc /hosts
Defina o nome do host em /etc /hosts Substitua o nome do host acima e os registros FQDN por suas próprias configurações.
2. Em seguida, vá para a página de download do Oracle Java e pegue a versão mais recente de Kit de Desenvolvimento Java SE em seu sistema com a ajuda de ondulação comando:
# curl -lo -h "cookie: oraclelicense = aceit -securebackup -cookie" "http: // download.oráculo.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.rpm ”
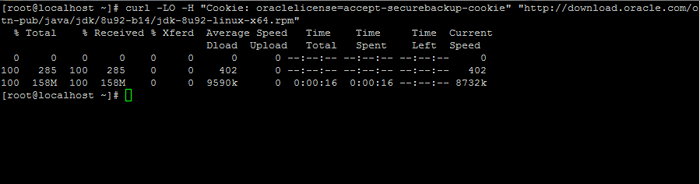 Baixe o Java SE Development Kit 8
Baixe o Java SE Development Kit 8 3. Após o término do download binário Java, instale o pacote emitindo o comando abaixo:
# rpm -uvh jdk-8u92-linux-x64.RPM
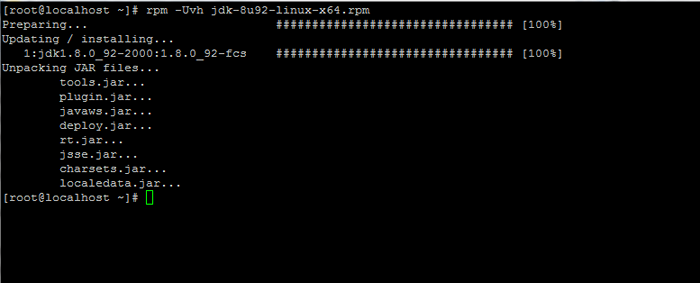 Instale Java no CentOS 7
Instale Java no CentOS 7 Etapa 2: Instale a estrutura do Hadoop no CentOS 7
4. Em seguida, crie uma nova conta de usuário em seu sistema sem poderes raiz que o usaremos para o caminho de instalação e o ambiente de trabalho do Hadoop. O novo diretório de conta da conta residirá em /opt/hadoop diretório.
# useradd -d /opt /hadoop hadoop # passwd hadoop
5. Na próxima etapa, visite a página do Apache Hadoop para obter o link da versão estável mais recente e baixar o arquivo em seu sistema.
# Curl -o http: // apache.Javapipe.com/hadoop/comum/hadoop-2.7.2/Hadoop-2.7.2.alcatrão.gz
 Baixe o pacote Hadoop
Baixe o pacote Hadoop 6. Extraia o arquivo da cópia do conteúdo do diretório para o Hadoop Conta Home Path. Além disso, altere as permissões de arquivos copiados de acordo.
# tar xfz hadoop-2.7.2.alcatrão.gz # cp -rf hadoop -2.7.2/*/opt/hadoop/ # chown -r hadoop: hadoop/opt/hadoop/
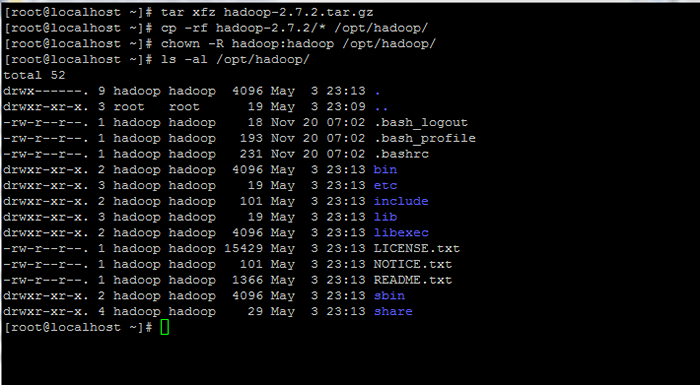 Extraia e defina permissões no Hadoop
Extraia e defina permissões no Hadoop 7. Em seguida, faça login com Hadoop usuário e configure Hadoop e Variáveis de ambiente Java em seu sistema editando o .Bash_profile arquivo.
# su - Hadoop $ VI .Bash_profile
Anexe as seguintes linhas no final do arquivo:
Variáveis Java Env exportar java_home =/usr/java/caminho de exportação padrão = $ caminho: $ java_home/bin export classpath =.: $ Java_home/jre/lib: $ java_home/lib: $ java_home/lib/ferramentas.jarra ## Hadoop Env variáveis export hadoop_home =/opt/hadoop export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export Hadoop_yarn_home = $ hadoop_home export hidoop_opts = "-djava.biblioteca.caminho = $ hadoop_home/lib/nativo "export hadoop_common_lib_native_dir = $ hadoop_home/lib/nativo caminho de exportação = $ path: $ hadoop_home/sbin: $ hadoop_home/bin
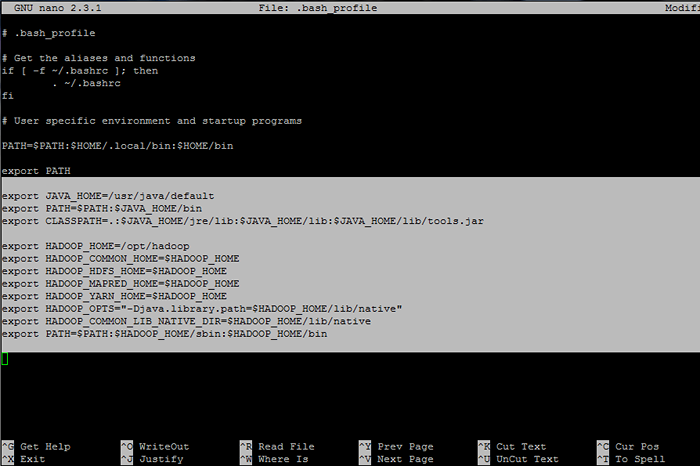 Configurar variáveis de ambiente Hadoop e Java
Configurar variáveis de ambiente Hadoop e Java 8. Agora, inicialize as variáveis do ambiente e verifique seu status emitindo os comandos abaixo:
$ fonte .BASH_PROFIL
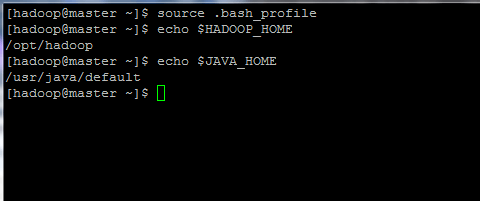 Inicialize variáveis de ambiente Linux
Inicialize variáveis de ambiente Linux 9. Finalmente, configure a autenticação baseada em chave SSH para Hadoop conta executando os comandos abaixo (substitua o nome de anfitrião ou Fqdn contra o SSH-COPY-ID comando de acordo).
Além disso, deixe o senha Arquivado em branco para fazer o login automaticamente via SSH.
$ ssh-keygen -t rsa $ ssh-copy-id master.Hadoop.LAN
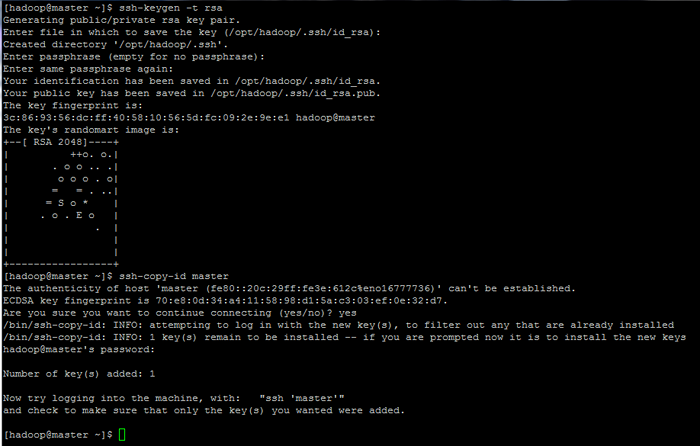 Configure páginas de autenticação baseadas em chave SSH: 1 2 3
Configure páginas de autenticação baseadas em chave SSH: 1 2 3
- « Encontre os 10 principais endereços IP acessando seu servidor da Web Apache
- 10 perguntas úteis da entrevista sobre serviços Linux e daemons »