

Hadoop - executando um exemplo do WordCount MapReduce
- 2703
- 235
- Leroy Lebsack
Este tutorial ajudará você a executar um exemplo do WordCount MapReduce no Hadoop usando a linha de comando. Este também pode ser um teste inicial para o seu teste de configuração do Hadoop.
1. Pré -requisitos
Você deve ter uma configuração do Hadoop em execução no seu sistema. Se você não possui o Hadoop instalou a instalação do Hadoop no Tutorial Linux.
2. Copie os arquivos para o sistema de arquivos Namenode
Depois de formatar com sucesso o namenode, você deve ter iniciado todos os serviços do Hadoop corretamente. Agora crie um diretório no Hadoop FileSystem.
$ hdfs dfs -mkdir -p/user/hadoop/entrada
Copiar copiar algum arquivo de texto para o sistema de arquivos hadoop dentro do diretório de entrada. Aqui estou copiando licença.txt para isso. Você pode copiar mais daquele arquivos.
$ hdfs dfs -put licença.txt/usuário/hadoop/entrada/
3. Comando WordCount em execução
Agora execute o exemplo do WordCount MapReduce usando o seguinte comando. O comando abaixo lerá todos os arquivos da pasta de entrada e processará com o arquivo jar mapReduce. Após a conclusão bem -sucedida dos resultados da tarefa, serão colocados no diretório de saída.
$ CD $ HADOOP_HOME $ HADOOP JAR Share/Hadoop/MapReduce/Hadoop-Mapreduce-Examples-2.6.0.saída de entrada de wordcount jar
4. Mostrar resultados
Primeiro, verifique os nomes do arquivo de resultado criado em [email protegido]/usuário/hadoop/sistema de saída do sistema usando o seguinte comando.
$ hdfs dfs -ls/user/hadoop/saída
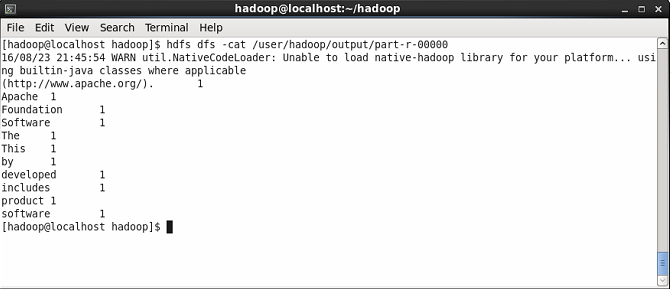
Agora mostre o conteúdo do arquivo de resultado onde você verá o resultado do WordCount. Você verá a contagem de cada palavra.
$ hdfs dfs -cat/user/hadoop/output/Part-R-00000
- « Como instalar Go 1.19 em Fedora 36/35 e CentOS/Rhel 8/7
- Como instalar o Apache Maven no CentOS/Rhel 8/7 »